关键词 > MTHE472/MATH872
MTHE 472/MATH 872 Homework 7 - Computational Assignment
发布时间:2021-04-15
MTHE 472/MATH 872 Winter 2021
Homework 7 - Computational Assignment
Problem 1: Value Iteration/Policy Iteration/Q-Learning and Linear Programming [40 Points]
Consider the following problem: Let X = {B, G}, U = {0, 1}, where X denotes whether a fading channel is in a good state (x = G) or a bad state (x = B). There exists an encoder who can either try to use the channel (u = 1) or not use the channel (u = 0). The goal of the encoder is send information across the channel.
Suppose that the encoder’s per-stage cost (to be minimized) is given by:
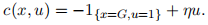
for some η ∈ R to be specified below.
If you view this as a maximization problem, you can see that the goal is to maximize information transmission efficiency subject to a cost involving an attempt to use the channel; the model can be made more complicated but the idea is that when the channel state is good, u = 1 can represent a channel input which contains data to be transmitted and u = 0 denotes that the channel is not used. When u = 1 and x = G, the channel is utilized successfully.
Suppose that the transition kernel is given by:

We will consider either a discounted cost criterion for some β ∈ (0, 1) (you can fix an arbitrary value)
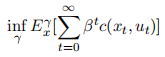
or the average cost criterion
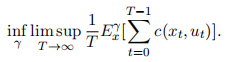
a) Using Matlab or some other program, obtain a solution to the problem given above in (1) through the following:
(i) [10 Points] Value Iteration. Take some fixed β ∈ (0, 1) of your choice. Consider
, η = 0.95 and η = 0.05. Interpret the optimal solution for these different values of η, in view of the application.
(ii) [10 Points] Policy Iteration. With the same β as above, work again with each of the following:
(iii) [10 Points] Q-Learning. Try only
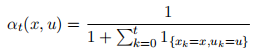
b) [10 Points] Consider the criterion given in (2). Apply the convex analytic method, by solving the corresponding linear program, to find the optimal policy? In Matlab, the command linprog can be used to solve linear programming problems. See (7.23) in the lecture notes.
c) [Optional] Study quantized approximation methods in Section 8.3.1 and 8.3.2, for both state space quantization and action space quantization to arrive at a finite model MDP with rigorous convergence guarantees.
Problem 2: The Kalman Filter [20 Points]
Let a linear system driven by Gaussian noise be given by the following:
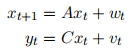
Here 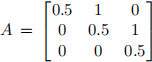 , C = [1 0 0]
, and the i.i.d. noise processes satisfy wt ~ N (0, I), vt ~ N (0, 1). The initial state is also zero-mean Gaussian and suppose that
, C = [1 0 0]
, and the i.i.d. noise processes satisfy wt ~ N (0, I), vt ~ N (0, 1). The initial state is also zero-mean Gaussian and suppose that 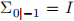 (here, we use the notation in Chapter 6 of the Lecture notes).
(here, we use the notation in Chapter 6 of the Lecture notes).
a) Write down the Kalman Filter update equations and the Riccati recursions.
b) Do the Riccati recursions converge to a limit; is the limit unique? Explain why or why not. By Matlab (or another program) verify your answer.
b) By simulating the above system in Matlab (or any other program), run the Kalman Filter from t = 0 until T = 1000. Plot 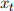 ,
, 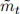 and
and 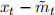 .
.
Problem 3: Q-Learning and its Convergence [Optional]
Complete the proof sketch of Theorem 8.2.1.
