关键词 > COMP3702/7702
COMP3702/7702 Artificial Intelligence 2020
发布时间:2021-12-11
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP3702/7702 Artificial Intelligence
Question 1. (20 marks)
Answer the following questions about the search problem shown below:
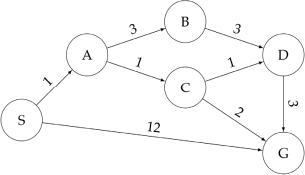
The initial state is S and the goal state is G. For the questions that ask for a path, please give your answers in the form ‘S–
a) (5 marks) What path does breadth-first search return for this search problem?
b) (5 marks) What path does uniform cost search return for this search problem?
c) (5 marks) What path does an A* graph search, using a consistent heuristic, return for this search problem?
d) Consider the heuristics for this search problem shown in the table below:
|
State |
h1 |
h2 |
|
S A B C D G |
5 3 6 2 3 0 |
4 2 6 1 3 0 |
i. (2.5 marks) Is h1 admissible? Yes or no.
ii. (2.5 marks) Is h2 admissible? Yes or no.
Reminder: Put your answers to all questions in the answer booklet
Question 2. (5 marks)
Mr Search says that informed search is always more efficient than blind search. Is Mr Search correct? Give reasons for your answer.
Question 3 (25 Marks)
Consider the following crossword puzzle with candidate words, which can be cast as a constraint satisfaction problem (CSP):
|
|
|
|
|
1 |
|
|
|
|
2 |
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
|
|
|
Denote the variables: 1D (1-down), 2A (2-across), 2D, 3A, 4D and 5A. Note that words can only be used once in a solution.
a) (2.5 marks) List all binary constraints between variables for this CSP.
b) (3 marks) Apply domain consistency to this CSP. List the resulting variable domains.
c) (9 marks) Apply arc consistency to the domain-consistent CSP from b). List the resulting variable domains. List the arc-consistent variable domains.
d) (9 marks) Apply backtracking search to the domain-consistent CSP from question b). Use the variable ordering (1D, 2A, 2D, 3D, 4A, 5A) and the variable order in the Words list to expand nodes in the search graph. List all variable assignment and removal operations, and any backtracking operations.
e) (1.5 marks) What is the solution to this CSP?
Question 4 (25 marks)
s0 s1 s2 s3 s4 s5
|
5 |
|
|
|
|
10 |
|
|
0 |
0 |
|||||
Consider the above gridworld. An agent is currently on grid cell s2, as indicated by the star, and would like to collect the rewards that lie on both sides of it. If the agent is on a numbered square (0, 5 or 10), the instance terminates and the agent receives a reward equal to the number on the square. On any other (non-numbered) square, its available actions are to move Left and Right. Note that Up and Down are never available actions.
If the agent is in a square with an adjacent square below it, it does not always move successfully: when the agent is in one of these squares and takes a move action, it will only succeed with probability ⃞ . With probability 1 െ⃞ , the move action will fail and the agent will instead fall downwards into a trap. If the agent is not in a square with an adjacent space below, it will always move successfully.
For parts a), b) and c), we are using discount factor ∈ ߛሾ0,1ሿ .
a) (5 marks) Consider the policy πோ⃞⃞⃞௧ , which is to always move right when possible. For each state ∈ ⃞ሼ⃞1, 4⃞ 3,⃞ 2,⃞ሽ in the diagram above, give the value function ⃞గೃ⃞⃞⃞⃞ in terms of ߛand ⃞ .
b) (5 marks) Consider the policy π⃞⃞⃞௧ , which is to always move left when possible. For each state ∈ ⃞ሼ⃞1, 4⃞ 3,⃞ 2,⃞ሽ in the diagram above, give the value function ⃞గ⃞⃞⃞⃞ in terms of ߛand ⃞ .
c) (2.5 marks) For what range of values of ⃞ is it optimal for the agent to go left from the start state (s2, represented by the star)? Express your solution in terms of .ߛ
For parts d), e) and f), let the discount factor ߛ ൌ 0.9, and let the probability of falling into a trap ⃞ ൌ 0.8 for both s3 and s4 (independently).
ൌ 0.8 for both s3 and s4 (independently).
d) (5 marks) Compute the value function for the gridworld problem above.
e) (5 marks) Compute the Q-function for the gridworld problem above.
f) (2.5 marks) What is the optimal policy in the gridworld problem above when ߛ ൌ 0.9 and ⃞ ൌ 0.8?
ൌ 0.8?
Question 5 (10 Marks)
We continue to consider the gridworld from the previous page, repeated here:
s0 s1 s2 s3 s4 s5
|
5 |
|
|
|
|
10 |
|
|
0 |
0 |
|||||
In question 5 we assumed knowledge of the transition function ⃞ሺ⃞,⃞,⃞ᇱሻ . Now, in this question, assume we do not know the transition function.
a) (6 marks) Suppose we choose to use Q-learning (in absence of the transition function) and we obtain the following observations:
|
⃞௧ |
⃞ |
|
reward |
|
s3 |
Left |
s2 |
0 |
|
s2 |
Left |
s1 |
0 |
|
s1 |
Left |
s0 |
5 |
|
s4 |
Right |
s4-below |
0 |
What values does the Q-function attain if we initialise the Q-values to 0 and replay the experience in the table exactly two times? Use a learning rate ߙ ൌ 0.6, discount factor ߛ ൌ 0.9 and the probability of falling into a trap of ⃞ ൌ 0.8 for both s3 and s4 (independently).
ൌ 0.8 for both s3 and s4 (independently).
b) (2 marks) Which of the following can be used to obtain a policy if we don’t know the transition function? (Choose all correct options. Put your answer in the answer booklet.)
i) Value Iteration followed by Policy Extraction
iii) TD learning followed by Policy Extraction
iv) Policy Iteration with a learned ⃞ሺ ,⃞⃞, ሻᇱ⃞
c) (2 marks) Under which conditions would one benefit from using approximate Q- learning over vanilla Q-learning? (Select one only. Put your answer in the answer booklet.)
i) When the state space is very high-dimensional
iii) When the transition function is unknown
Question 6 (15 Marks)
Anne is a COMP3702 student who enjoys playing a simple game of chance on her phone while waiting for her lecture to begin. The game involves pressing one of two buttons, a1 or a2 each round, which return a reward ⃞௧ . The goal is to maximise the average reward accumulated over time. The rewards for pushing a button are not know to Anne, but she does know that they follow a fixed distribution. She is investigating two algorithms, ϵ-greedy and the upper-confidence bound (UCB).
In one instance of the game, Anne takes the actions and receives the rewards in the table below:
|
t |
Action |
|
|
1 2 3 4 5 6 |
a1 a2 a1 a2 a1 a1 |
2 1 2 0 0 0 |
a) (3 marks) If Anne uses ϵ-greedy, which button is she most likely to press next?
b) (4 marks) Anne is considering a variation on the UCB algorithm that uses the following confidence bound estimate: 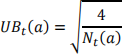
where ⃞௧ ሺ⃞ሻ is the number of times action a has been chosen by round t. Using this UCB algorithm, which button should Anne press next?
Anne is curious as to how the game works, so inspects the source code This reveals that the rewards are encoded as a repeated game in normal form with the following payoff
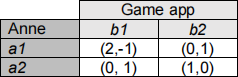
c) (3 marks) The source code also shows that the game app has a fixed strategy of playing b1 with probability 0.6. With this knowledge, what strategy should Anne use to play the game?
d) (5 marks) Bing is the app developer. He notices Anne’s success (and that she has accessed the game source code). What can Bing do to improve his strategy and maximise the payoff to his game app? Give a suitable strategy and state your reasons for choosing it.
