关键词 > IEOR242
IEOR 242: Applications in Data Analysis, Spring 2021 Practice Midterm Exam 3
发布时间:2024-07-01
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
IEOR 242: Applications in Data Analysis, Spring 2021
Practice Midterm Exam 3
March 2021
1 True/False and Multiple Choice Questions – 45 Points
Instructions: Please circle exactly one response for each of the following 15 questions. Each question is worth 3 points. There will be no partial credit for these questions.
1. The probability model underlying logistic regression states that Pr(Y = 1jX) = h(β0 +β1 X1 +· · ·+βpXp ) where Y is the dependent variable, X is the vector of independent variables, (β0 , β1, . . . , βp ) are the logistic regression coe伍cients, and h(w) = ![]() is the logistic function.
is the logistic function.
A. True
B. False
2. Consider a linear regression model with a highly insignificant variable such that the p-value of the corresponding coe伍cient is greater than 0.50. Then, removing this variable from the model and re- training always results in a decrease in the training set R2 value.
A. True
B. False
3. Consider a linear regression model with a highly insignificant variable such that the p-value of the corresponding coe伍cient is greater than 0.50. Then, removing this variable from the model and re- training always results in an increase in the test set OSR2 value.
A. True
B. False
4. Consider a simple linear regression problem with a continuous dependent variable Y and a single inde- pendent variable X . Suppose that we have a training dataset of n = 2 observations (x1 , y1 ), (x2 , y2 ) that satisfies x1 ![]() x2 and yi = β0 + β1 xi for i = 1, 2, where β0 , β1 are the true coefficients for the model. Let
x2 and yi = β0 + β1 xi for i = 1, 2, where β0 , β1 are the true coefficients for the model. Let
β(^)0 andβ(^)1 denote the estimates of β0 and β1 , respectively, based on minimizing the RSS (residual sum
of squared errors) on the training set. Then, it must be the case that β(^)0 = β0 and β(^)1 = β1 .
A. True
B. False
5. In order to train a boosting model (with trees as the base models), one of the required inputs to the algorithm is the number of splits in each of the base tree models, and this parameter should ideally be tuned with cross-validation.
A. True
B. False
6. Consider training a CART model for binary classification and suppose that we use either the error rate impurity function or the Gini index impurity function. Then, in both cases, the total impurity cost of the tree is guaranteed to strictly decrease after every additional split.
A. True
B. False
7. Consider using the bootstrap to asses the variability of the OSR2 value of a previously trained Random Forests model on the test set,e.g., by constructing a confidence interval. Suppose that we set B = 10, 000 for the number of bootstrap replications. Then, this procedure requires computing the OSR2 value of the Random Forests model on 10,000 diferent bootstrapped datasets.
A. True
B. False
8. The accuracy of a logistic regression model does not depend on the choice of the probability threshold value.
A. True
B. False
9. Consider the dataset below in Figure 1 for a binary classification problem with p = 2 features and where + denotes a positive label and - denotes a negative label.
Figure 1
Then, it is possible for some classifier to achieve perfect 100% accuracy on this dataset.
A. True
B. False
10. After removing punctuation, the bag of words representation of “Paul likes to travel” is the same as that of “Paul likes to travel. Paul likes to travel.”
A. True
B. False
11. It is always the case that nonparametric methods (like boosting and random forests) will outperform parametric methods (like linear regression) in terms of out of sample predictive performance.
A. True
B. False
12. Consider a binary classification problem where the test set has Npos > 0 positive observations and Nneg > 0 negative observations. Suppose that we have previously trained a model on the training set, and that, on the test set, this model has a true positive rate value denoted by TPR and a false positive rate value denoted by FPR. Then a correct expression for the accuracy of this model on the test set is given by:
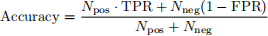
A. True
B. False
13. Which of the following actions has the least risk of increasing the likelihood of overfitting?
A. Increasing the number of trees/iterations when training a boosting model
B. Increasing the number of trees when training a random forests model while leaving the value of m (mtry) fixed
C. Decreasing the value of m (mtry) when training a random forests model while leaving the number of trees fixed
D. Introducing new independent variables in a linear regression model that are quadratic functions of the original set of independent variables
14. Which of the following statements are true regarding k-fold cross-validation?
1. Increasing the value of k results in more overall computation time for the cross-validation procedure
2. Using k = n where n is the number of data points in the training set is the same as leave-one-out cross-validation (LOOCV).
3. Using k = 1 is the same the validation set method. A. Only (1.) and (2.)
B. Only (1.) and (3.)
C. Only (2.) and (3.)
D. All three statements
15. Consider training a CART model for a classification problem on a training set of size n = 6 with p = 2 independent variables. Figure 2 below displays a scatter plot of the independent variables (X1 , X2 ) along with 5 regions corresponding to the CART model that was trained. What is the most definitive (i.e., strongest) statement that can be made about the accuracy A of this CART model on the training set?

Figure 2
A. 0 ≤ A ≤ 1
B. 4/6 ≤ A ≤ 1 C. 5/6 ≤ A ≤ 1 D. A = 1
2 Short Answer Questions – 55 Points
Instructions: Please provide justification and/or show your work for all questions, but please try to keep your responses brief. Your grade will depend on the clarity of your answers, the reasoning you have used, as well as the correctness of your answers.
The first two problems concern a dataset of golf player statistics with 162 observations, each corre- sponding to a diferent top professional golfer who participated in the PGA tour in 2018. Various attributes concerning player performance and winnings throughout the entire length of the 2018 season were collected and aggregated. Table 1 below describes these attributes in more detail. For clarity, the first 6 observations of the dataset are also included below. We are primarily interested in building models for predicting player success – in terms of monetary winnings – based on the four direct performance statistics/attributes that are provided. We are also interested in which performance statistics have the greatest impact on success.
Table 1: Description of the dataset.
Variable Description
|
PlayerName |
The player’s name |
|
Winnings |
Total monetary winnings over the entire season, in millions of dollars (USD) |
|
AverageScore |
Average total point score per 18 hole round |
|
AveragePutts |
Average number of putts per hole |
|
AverageDrivingDist |
Average drive distance per hole, in yards |
|
DrivingAccuracy |
Percentage of shots where the drive shot successfully lands on the fairway area |
> head(golf_data) # A tibble: 6 x 6
PlayerName Winnings AverageScore AveragePutts AverageDrivingDist DrivingAccuracy <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Aaron Baddeley 0 .905 70 .8 1 .72 286 . 57.7
2 Aaron Wise 1 .05 70 .7 1 .73 303 . 61 .8
3 Abraham Ancer 3 .17 70 .6 1 .75 293 . 70 .2
4 Adam Hadwin 2 .22 70 .5 1 .73 291 . 67.8
5 Adam Long 1 .65 71 .5 1 .79 292 66 .5
6 Adam Schenk 1 .26 70 .8 1 .75 301 . 61 .3
