关键词 > AD699
AD699: Data Mining for Business Analytics Spring 2019 Quiz #1
发布时间:2024-06-28
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
AD699: Data Mining for Business Analytics
Spring 2019
28MAR
Quiz #1
Version: ALPHA
1. A survey was recently conducted in which 650 BU students were asked about their web browser preferences. Of all the students asked, 461 said that they sometimes use Firefox. 72 of the students said that they never use Chrome or Firefox. 12 of the Firefox users stated that they never use Chrome. Given that a person uses Chrome, what is the probability that the person never uses Firefox?
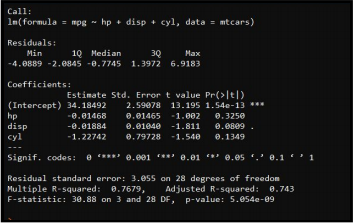
2. The screenshot below shows the intercept and the coefficients of a linear regression model with the output variable mpg and the input variables hp (horsepower), disp (displacement, in liters), and cyl (cylinders).
What mpg would this model predict for a car with 150 horsepower, a displacement of 200 liters, and a 6-cylinder engine?
3. A data scientist has just built a multiple linear regression model with an r-squared value of .7915. This model includes 10 predictors and it was built with 152 rows of data. What is the adjusted r-squared of this model?
4. Which of the following statements characterizes the difference between explanatory and predictive linear regression models?
a. When regression is performed for explanatory purposes, a data partition
must be performed beforehand, so that the person who built the model can check the results against a validation set; predictive linear regression, however, is not associated with data partitioning.
b. Explanatory regression is done so that an equation can be generated with coefficients and an intercept; with predictive regression, however, the intercept and some of the coefficient terms can be viewed as optional.
c. With explanatory regression, the person constructing the model will not use more than seven inputs a time; with explanatory regression, however, the number of input variables is theoretically limitless.
d. When regression is conducted for explanatory purposes, the ‘goodness offit’ is one of the most important metrics considered; when regression is conducted for predictive purposes, however, the main consideration is simply the model’s ability to predict outcomes for new records.
5. You are reviewing a linear regression model that you have built, and you notice a pattern with the residuals. For the smaller input values, the residuals tend to be very large, but as the input values get bigger and bigger, the residuals become smaller. What assumption about linear regression appears to have been violated here?
a. The rule of arbitrary distributions.
b. Homoskedasticity.
c. Parsimony.
d. Error reduction.
6. The University Grille on Commonwealth Avenue just released the findings from a three year-study of students’ salad orders to determine the popularity of Caesar and Ranch dressing. In this study, the ordering habits of 3000 students who have ordered salads were analyzed. 185 of these students never ordered any dressing on their salads. 2100 of the students ordered Caesar dressing, but never ordered Ranch. What is the probability that a randomly-selected student from this survey ordered Ranch?
7. When comparing user reviews or recommendations, why might correlation distance be a more appropriate metric to use in some cases than Euclidean distance?
a. Euclidean distance is unreliable for subjective measurements because if all the data are measured on the same scale (for instance, 1 through 10) then the values must be normalized prior to analysis.
b. A user might feel that correlation distance is more effective for capturing the meaning among such relationships because the people making the reviews may not have reviewed the same content (for example, user A might have seen and reviewed 5 movies, while user B saw and reviewed 5 completely different movies).
c. There is no single, universal standard or benchmark by which different people base their reviews of a product. The correlation distance between two reviewers captures the direction of their movement as they go from one product to another.
d. Because Euclidean distances quickly become unreliable when a large data set is used to generate them, something significant (like a movie or product database) will require a more powerful metric such as correlation distance instead.
8. Based on the information shown below, which of the following statements is true about the distance between the reviews made by Andrew and Brian?
|
|
Orange is the New Black |
BoJack Horseman |
Black Mirror |
13 Reasons Why |
Big Mouth |
|
Andrew |
4 |
2 |
5 |
3 |
4 |
|
Brian |
3 |
1 |
4 |
3 |
5 |
a. The Euclidean distance between Andrew and Brian is less than the hamming distance.
b. The Euclidean distance between Andrew and Brian is the same as the hamming distance.
c. The Euclidean distance between Andrew and Brian is greater than the hamming distance.
d. The Euclidean distance between Andrew and Brian can be determined with this data, but the hamming distance cannot be determined.
9. You recently learned that someone built a classification tree using R to explore survival among passengers on the Titanic, with two outcome variables: “Survived” or “Did Not Survive.” The predictors in this person’s model were: Gender (Male or Female), Passenger Class (1st, 2nd, 3rd, or Crew), and Age (a numeric variable). After you built the model, you discovered that the root node was Gender. What does this mean?
a. This means that Gender can be considered a conclusive variable -- it separated the passengers into “Survived” or “Did Not Survive” without requiring the use of additional decision nodes in the classification process.
b. Among all the possible splits that the model could have started with, it found that Gender did the best job of creating homogeneous groupings further down the tree.
c. Gender is the last variable that the model should consider when creating the data partition (assuming the rows have been randomized prior to the partition, and aren’t already listed in some logical order).
d. Of all the variables that were used as inputs, Gender is most likely to appear in the final classification nodes.
10. Which of the following statements is true about trees, splits, and predictors?
a. When a tree splits based on a particular predictor, it cannot split again on that same predictor (this is why random forests are preferred to single trees).
b. A tree may split along values for a particular predictor at one point, and then split again on that same predictor at another point further down the tree.
c. If a tree creates a split at the root node for a particular predictor, it may split again on that predictor, but only once more.
d. The relationship among splits and predictors is such that the number of
splits will never exceed the square root of the number of predictors used to build the model.
11. You recently built a classification tree that had 7 terminal nodes. How many classification rules can be derived from this tree?
12. A basketball player named Yao Ming is 7 feet, 6 inches tall. If he and his wife, Ye Li, had a son, what would someone who believes in “regression to the mean” predict about the eventual height of this son?
a. The son would likely be taller than Yao Ming, especially if Ye Li is taller than the average woman.
b. The son’s height could be predicted by an exact equation: Yao Ming’s height, plus Ye Li’s height, divided by 2 (in other words, the mean of their heights).
c. The son would be taller than the average person, but not as tall as Yao Ming.
d. The principle of regression to the mean would not apply in this case, since Yao Ming’s height is so much greater than the mean height for adult males.
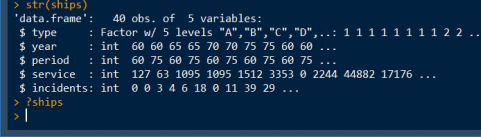
13. You have been instructed to build a data mining model using the variables shown here, with the outcome variable “incidents” and all of the other variables shown (type, year, period, and service) as predictors. However, you are not allowed to perform any data manipulation or data preprocessing -- in other words, you must run a function on these variables without changing any of them at all. Which of the following data mining algorithms could be used to accomplish this?
a. Classification Tree.
b. K-nearest neighbors.
c. None of the choices shown here.
d. Multiple Linear Regression.
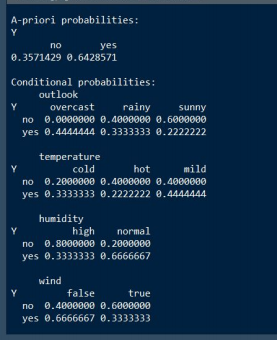
14. Using the data shown in the screenshot below, use a Naive Bayesian approach to generate a probability for whether someone will play tennis on a day with mild temperature and normal humidity.
15. Which of the following is a problem that could be solved with a linear regression model?
a. The type of car that a consumer will select when faced with several choices at a used auto lot.
b. Whether a particular consumer is likely to “churn” away from his current mobile phone subscription plan.
c. The vacation destination that a consumer would choose if presented with three options: New York City, San Francisco, or Key West.
d. The amount of annual spending that a consumer is likely to generate on his American Express credit card.
