关键词 > CS230
CS 230 Winter 2024 Assignment 5
发布时间:2024-06-26
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CS 230 Winter 2024 Assignment 5
Coverage: Subroutines in MIPS, CPU Pipeline and Performance Measures
• All submissions are to be completed through MarkUs (https://markus.student.cs.uwaterloo.ca/markus_cs230_w/en/assignments)
• Read the policy described in Learn regarding late submissions. Check MarkUs to see how many 12-hour grace periods you have remaining.
• Double check your submissions in MarkUs after you have uploaded them. It is your responsibility to ensure that the uploaded version is readable in MarkUs.
• Solutions for assignments will not be posted.
• Questions are approximately equally weighted.
1. For this question, you will be submitting two separate files. However, you may choose to develop the solution in a single file, and divide the code into separate files before submitting the final versions.
You should test the final versions of your solutions by concatenating the files before assembling them. Here is how you can do that in Linux:
cat a5q1b.asm a5q1a.asm > a5q1.asm
/u/cs230/pub/binasm < a5q1.asm > a5q1.mips
The first command concatenates the two files from part b) and part
a) into a single file (note the order of the files). The second command assembles the joint files.
When we test your solution, we will providing our own versions of each part. In other words, when we test your part a), we will use our own version of part b) and vice versa. This means your solution for each part should not depend on any details of the other part.
It is very important that the solutions for this question follow the register conventions described on Slide 74 of Module 2. The main purpose of this assignment is to test the creation and use of subprograms. The majority of the correctness marks will be connected to properly using the registers according to the conventions.
• Your programs must assemble and run properly with the given MIPS assembler binasm in the student.cs environment.
• The marks for this question will be based on correctness. If your program does not assemble properly, then the correctness marks will be 0. Test your submission thoroughly before submitting.
• Your solution should include comments at the beginning that include your name, your Quest ID, and a brief description of the program. You are not required to comment every line of your program. However, you should include inline comments that highlight the logical steps of your solution.
(a) Recall the filter function from CS115/135. This is an abstract list function that consumes a function and a list and produces a list containing only the elements that make predicate function produce true. For example (filter odd? ’(1 2 3)) produces the list ’(1 3).
For this part, create a subroutine that is labelled filter that has three arguments (in this order): the address of a function that itself has one parameter, the address of the first element of an array, and the size of the array. The function passed as an argument is the predicate function. The predicate function will return either 1, which represents the value true, or 0, which represents the value false.
The filter subroutine will create a copy of the elements of the original array that cause the predicate function to produce true. The copy should appear in the memory addresses immediately following the original array. The subroutine should return the address of the first element of the newly created array, and the size of the newly created array (in that order). For example, suppose the filter subroutine is given the address of a subroutine that will check to see if a value is an odd number as the first argument, the address of an array with values [1, 2, 3] as the second argument, and the size 3 as the third argument. When the filter subroutine is finished, the values [1, 3] would appear in memory locations immediately following [1, 2, 3]. Note that this subroutine will be calling another subroutine. This means that it is both a callee and a caller. The subroutine it calls has the right to change any registers that are designated as unsaved temporary. So, if this is an issue, you should save the important register values of filter on the stack before calling another subroutine.
(b) Write a program that uses the filter subroutine from part a) to create a new array that is a subset of the original. The program will use the array front end, where the address of the first element is in register $1 and the size of the array is in register $2. The new array will contain the values of the original array that are non-negative, multiples of 4. in the same relative order as the original array. Before the main program ends, but after the filter subroutine has been called, the address of the new array should be saved in register $1 and the size of the new array should be saved in register $2.
The program must include a subroutine called wordaligned. This subroutine has a single argument that is an integer and returns 1 if the number is a non-negative, multiple of 4, and returns 0 otherwise. For example, if the subroutine is given the integer 12, 1000, or 0 it will return the value 1. If the subroutine is given the integer -4 or 15, it will return the value 0. The code for the subroutine should appear at the end of the file, after the instruction jr $31 of the main program.
The basic structure of this part b) file is:
;; Prepare to call the filter subroutine
;; Call filter subroutine
jr $31
wordaligned:
;; Code for wordaligned subroutine
jr $31
Note that this program should not work directly with the arrays. There will be a severe loss of correctness marks for solutions of part b) that directly access the elements of the arrays using lw and sw.
You may want to test your solution using the arraydump front end.
No solution provided. Marking is based on tests in OUTPUT.txt
2. For Questions 2 and 3 you will be working with the following MIPS assembly program.
1 beq $2 , $0 , endloop
2 add $3 , $0 , $1
3 add $4 , $2 , $0
4 loo p : addi $4 , $4 , −1
5 lw $13 , 0 ( $3 )
6 s l t $14 , $13 , $0
7 bne $14 , $0 , e n d if
8 sub $15 , $13 , $4
9 sw $15 , 0 ( $3 )
10 e n d if : addi $3 , $3 , 4
11 bne $4 , $0 , loo p
12 endloop : j r $31
Line numbers have been added to the beginning of each instruction so you can use them as references in subsequent questions.
(a) Write the machine code version of the program. The machine code instructions should be written as hexadecimal values. The file should contain each 8-digit hexadecimal number preceded by 0x (for a total of 10 characters) on a separate line. The alphadigits in the hexadecimal values should all be uppercase. See the solution for Question 3 of Tutorial 08 for the expected format.
0x1040000A
0x00011820
0x00402020
0x2084FFFF
0x8C6D0000
0x01A0702A
0x15C00002
0x01A47822
0xAC6F0000
0x20630004
0x1480FFF8
0x03E00008
(b) Assume you have a processor running at 8GHz with the cycles per instruction set architecture defined as follows:
• Memory accesses: 8 cycles
• Branch/Jump instructions: 2 cycles
• Everything else: 4 cycles
Assume that the program is run using the array front end and the user enters 5 for the array size, and the numbers: [-5, 0, 2, -8, 3] for the array contents.
What is the CPI of the processor for the program given the input described?
How much time would the processor take to complete the program instructions?
Your answer should ignore the user time it takes to enter the data. You may assume there are no extra cycles due to pipelining or hazards for this question.
Show your work.
With the given data, the loop is executed 5 times. For the negative values in the array, the branch bne $14, $0, endif is taken, so the instructions on lines 8 and 9 are only repeated 3 times. All other instructions in the loop are repeated 5 times.
Total memory accesses: 5 + 3 = 8
Total Branch/Jump accesses: 1 + 5 + 5 + 1 = 12 ***
Everything else: 2 + 5 · 3 + 3 = 20
Total cycles: 8 · 8 + 12 · 2 + 20 · 4 = 168 cycles
The total number of instructions executed is:
3 + 6 × 5 + 3 × 2 + 1 = 40
The CPI is 168/40 = 4.2
Each cycle will take 8× 1 109 seconds = 0.125 ns
The total time will be 168 × 0.125 ns = 21 ns
Some students may assume that the jr $31 instruction is not a jump instruction. If you see the numbers: 170 cycles, then this is an acceptable answer. This means the total time would be: 21.25 ns.
3. Consider the code from the program listed at the beginning of Question 2. For this question assume that pipelining has been implemented. Assume that each stage takes 1 cycle to complete.
(a) Identify the pipeline hazards present in this code, i.e. situations that would generate stall bubbles. In the case of data hazards identify the two lines of code involved. Summary of hazards:
• Line 1 is a control hazard
• Line 7 is a control hazard
• Line 11 is a control hazard
• data hazard between Lines 3 and 4
• data hazard between Lines 5 and 6
• data hazard between Lines 6 and 7
• data hazard between Lines 8 and 9
(b) Assume that this program is run using the array frontend, and that register $1 contains the address of the first element of the array, and $2 contains the size of the array. Assume that the size of the array is 2, and that the numbers [4, -7] have been placed in the array. Assuming that no pipeline optimizations have been implemented, i.e. no forwarding or branch prediction, determine the number of cycles it takes to complete the execution of this program.
Justify your answer using a pipeline diagram formatted like the diagram below:
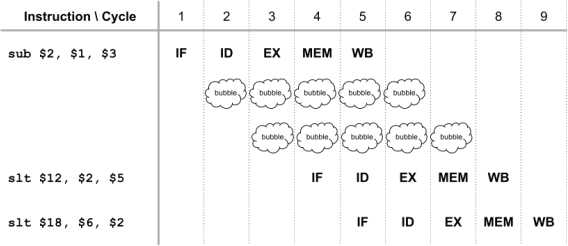
It may be helpful to use a spreadsheet to draw the diagram.
Sample diagram in separate document.
This diagram shows that it will take 39 cycles to complete the program.
(c) Suppose forwarding and static branch prediction have been implemented. Given the same array, when compared to the answer in part (b):
• how many cycles would be saved due to forwarding?
• how many cycles would be saved due to static branch prediction?
Consider each case (forwarding and branch prediction) separately. In each case, identify which lines of stall bubbles from your diagram in part (b) will be eliminated.
• Forwarding will eliminate the two stalls following Line 3.
Forwarding will eliminate one of the stalls following Line 5 (lw). This line is repeated twice, so this is a total reduction of two stalls.
Forwarding will eliminate one of the stalls between Line 6 (lw) and Line 7 (bne). This line is repeated twice, so this is a total reduction of two stalls.
Forwarding will eliminate the two stalls between Line 8 (sub) and Line 9 (sw). This line is only repeated once.
This is a total savings of 8 cycles due to forwarding.
• Static branch prediction guesses correctly for the branch on Line 1, which saves one stall bubble.
Static branch prediction guesses correctly the first time, but not the second time for the branch on Line 7, which saves a total of one stall bubble.
Static branch prediction guesses correctly for the branch on Line 11 the first time, but not the second time for the branch on Line 7, which saves a total of one stall bubble.
This is a total savings of 3 cycles due to branch prediction.
(d) Suppose you ran the same code with an array [-5, 0, 2, -8, 3]. Would there be any difference between the number stall bubbles saved using static branch prediction compared to the number of stall bubbles saved using dynamic branch prediction for the branch instruction at Line 7?
Briefly justify your answer.
Dynamic branch prediction will be correct for the array element value 2. It is correct in this case since the branch should not be taken for non-negative integers. Since the branch is not taken for the array element 0, it will do the same the next time through the loop.
However dynamic branch prediction is incorrect for the array elements 0, -8, and 3. Negative numbers take the branch and non-negative numbers don’t take the branch. Since each of these elements follow a value that has the opposite branch behaviour, they will have an incorrect prediction.
Static branch prediction will be correct for all non-negative values in the array. It will be correct for the values 0, 2, and 3, which is correct two more times than dynamic branch prediction over these values.
