关键词 > APS360H1
APS 360 H1 Applied Fundamentals of Deep Learning 2023
发布时间:2024-06-25
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Applied Fundamentals of Deep Learning
Date : March 3, 2023
Question 1. [10 marks]
Circle the best answer for each of the questions below. Do not circle more than one answer per question.
Part (a) [1 mark]
Which of the following statement/s is/are correct?
(A) All neurons in the same layer of an ANN share the same bias.
(B) Backpropagation algorithm is used to find the hyperparameters that min- imize the loss function.
(C) A neural network that achieves a very high validation accuracy is said to regularize well.
1. A only
2. A and B
3. A and C
4. All
5. None * (1 marks)
Part (b) [1 mark]
Which of the following statement/s is/are correct?
(A) Architecture of a neural network evolves during the training to fit the data better.
(B) Softmax can be used as an activation function in the hidden layer of an ANN.
(C) During training of a neural network, at the beginning of every Epoch the parameters are initialized to small random values.
1. A only
2. A and B
3. A and C
4. All
5. None * (1 marks)
Part (c) [1 mark]
Which of the following statement/s is/are correct?
(A) Adding an extra convolutional layer to a CNN increases the number of trainable parameters.
(B) Adding an extra maxpooling layer to a CNN increases the number of train- able parameters.
(C) Drop-out is a technique used in the convolutional layers of a CNN.
1. A only * (1 marks)
2. A and B
3. A and C
4. All
5. None
Part (d) [1 mark]
Which of the following statement/s is/are correct?
(A) The inherent parallelism in the computations involved in a CNN was first exploited when training LeNet-5.
(B) SGD with Momentum can help with the exploding gradient problem.
(C) During training, it is better to start with a smaller learning rate and gradually increase it, rather than start with a larger learning rate and gradually decrease it.
1. A only
2. A and B
3. A and C
4. All
5. None * (1 marks)
Part (e) [1 mark]
Which of the following statement/s is/are correct?
(A) Adding intermediate classifiers and using the sum of the intermediate loss and the final loss in backpropagation can improve regularization.
(B) Transpose convolution was first introduced in GoogLeNet.
(C) Skip-connections can help with the vanishing gradient problem.
1. A only
2. A and B
3. A and C
4. All
5. C only * (1 marks)
Part (f) [1 mark]
Which of the following statement/s is/are correct?
(A) Padding in Transpose convolution has the effect of decreasing the output size.
(B) 1 by 1 - convolution can be used to reduce the featuremap size.
(C) It is generally agreed that Deep Learning began at the University of Toronto.
1. A only
2. A and B
3. A and C * (1 marks)
4. All
5. None
Part (g) [1 mark]
Which of the following statement/s is/are correct?
(A) Transfer learning is a technique where a pre-trained CNN is used as it is to classify images belonging to new classes that were not present in the original training of that CNN.
(B) The compact encodings produced by an Autoencoder have more restric-tions placed on them than those produced by a Variational Autoencoder.
(C) t-SNE is a Machine Learning technique that can be used as a base-line for a project in this course that performs classification.
1. A only
2. A and B
3. A and C
4. All
5. None * (1 marks)
Part (h) [1 mark]
Which of the following statement/s is/are correct?
(A) Cross entropy is computed using two probability distributions.
(B) In an ANN designed for Regression, the Neuron at the output of the net- work can only produce a number in the interval [0, 1].
(C) Other things being equal, the backpropagation update to a weight con-nected to an input variable is proportional the value of that variable.
1. A only
2. A and B
3. A and C * (1 marks)
4. All
5. None
Part (i) [1 mark]
Which of the following statement/s is/are correct?
(A) Other things being equal, Mini-Batch-Descent makes more updates to the parameters than Stochastic Gradient Descent.
(B) Drop-out helps with the vanishing gradient.
(C) Weights from the decoder part of a pre-trained Autoencoder can be used in Transfer Learning.
1. A only
2. A and B
3. A and C
4. All
5. None * (1 marks)
Part (j) [1 mark]
Which of the following statement/s is/are correct?
(A) Autoencoders can be used in dimensionality reduction.
(B) Autoencoders can be used to create new images.
(C) Pooling is an essential operation in CNNs.
1. A only
2. A and B * (1 marks)
3. A and C
4. All
5. None
Question 2. [20 marks]
Answer the following questions as concisely as possible.
Part (a) [2 marks]
State one advantage and one disadvantage of a large convolutional filter.
Part (b) [2 marks]
Consider the parameters of a pre-trained Autoencoder. State one application of the parameters of the decoder part and another application of the parameters of the encoder part.
Part (c) [2 marks]
An ANN was trained for regression and the parameters are fixed. Suppose the architecture and the values of all the parameters are given to us. If we know the value of the output, is it possible to calculate the input vector? Yes or No? Justify.
Part (d) [3 marks]
A neuron takes 10 inputs and uses ReLu activation. At the moment, each of the inputs and the bias are at the same value 1. All the weights, except one weight w3 , are also at the same value 1. If the output of the neuron is 0, find the highest possible value of w3 .
Part (e) [3 marks]
Consider a neuron on the first hidden layer of an ANN. The pre-activation output a is connected to the ReLu activating function which produces the output y = 2.3. If the input variables are given by xi = 2i, find 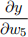
Part (f) [3 marks]
A 2-layer-ANN designed for Regression takes 4 inputs, uses ReLu activation in its hidden layer, and has 10 neurons in the hidden layer. At the moment all of its inputs have the same value 1 while all of the parameters have the same value 0.1. Find the output.
Part (g) [2 marks]
A 3 × 3 convolutional filter operates on a 9 × 9 image with no padding. Find the sum of all possible stride values that are less than 4.
Part (h) [3 marks]
State 3 innovations in terms of the architecture of deep CNNs that came after Alex-Net. Use the technical terms. No explanation necessary.
Question 3. [20 marks] Part (a) [7 marks]
A CNN was designed, trained, and tested to separate cat and dog images. The confusion matrix from the testing is shown below:
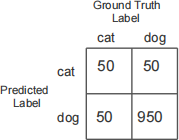
(i) Find the accuracy. [2 marks]
(ii) Despite the number above, the test results are actually really bad! How did I come to this conclusion. Explain in one sentence. [2 marks]
(iii) What led to the grossly inflated accuracy number? Use a technical term to answer this question. [3 marks]
Part (b) [3 marks]
If the output from: nn.Conv2d(6, 18, 5, 2) is a Tensor of shape (18 × 7 × 7), find the shape of the Tensor that was sent into the line above.
Part (c) [6 marks]
In the following implementation of a CNN, find the input (x) Tensor shape.
def init (self):
self.conv1 = nn.Conv2d(3, 8, 7, 2)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(8, 16, 5, 2)
self.fc1 = nn.Linear(16*2*2,5000)
seff.fc2 = nn.Linear(5000,10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16*2*2)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
Part (d) [4 marks]
(i) Find the total number of parameters in the Neural Network implemented below: [2 marks]
def init (self):
self.layer1 = nn.Linear(300,50)
seff.layer2 = nn.Linear(50,300)
def forward(self, x):
x = F.relu(self.layer1(x))
x = self.layer2(x)
return x
(ii) What type of neural network is being implemented above? Give the most likely answer. [2 marks]
Question 4. [20 marks] Part (a) [10 marks]
A mini-CNN takes in gray-scale images and uses 4 different convolutional filters that are followed by max- pooling. The output of the maxpooling layer is fully connected, an ANN which classifies the images into 5 classes.
One channel of this CNN minus the ANN part is shown in the diagram below. Convolutional kernel given by the matrix C operates on the input image M (with no padding and zero bias) to create the featuremap Y. There is no activation. The maxpooling operation shown in the diagram creates the subsampled map YS.
You are required to locate the entries in the matrix M that are responsible for creating the entry 8 in the map YS. Your answer forms a sub-matrix of M. Clearly indicate these entries by drawing a square inside the grid M and shading the square. (Hint: There is no need to find all the entries in Y.)
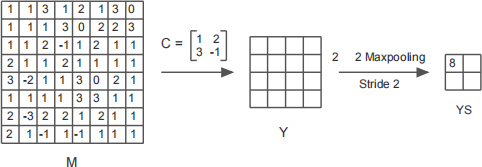
Part (b) [10 marks]
Write a PyTorch implementation of the “mini” CNN in part(a) above if it does not use any activation in the layers up to and including the sub-sampled layer YS. The maps in sub-sampled layer are fully con- nected to the input of an ANN that has 1000 neurons in the hidden layer followed by an output layer. Use appropriate activation functions in the ANN.
Question 5. [10 marks]
A transpose convolutional kernel given by:
C=ones(3,3)
operates on a featuremap M of shape 5 × 5 given by:
mi,j = i − j
to generate an up-sampled featurmap P, with stride 2, and no padding, and no output padding.
Find p3,2 .
