关键词 > APS360
APS 360 Applied Fundamentals of Machine Learning Midterm Test Winter 2022
发布时间:2024-06-24
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
APS 360
Winter 2022 Midterm Test
Applied Fundamentals of Machine Learning
Date : March 04, 2022
Question 1. [10 marks]
Circle the best answer for each of the questions below. Do not circle more than one answer per question.
Part (a) [1 mark]
Which of these problems is best described as an unsupervised learning problem?
(A) Generating a random pictures
(B) Representation learning with a contrastive loss * (1 marks)
(C) Traversing a neural network graph during a forward pass
(D) Predict stock prices from the size of a company, given a dataset of companies size and prices
Part (b) [1 mark]
Which of these best describes the concept of inductive bias?
(A) Bias of a machine learning algorithm learned from a training data set
(B) The assumptions we incorporate in our model to help learn to solve a problem * (1 marks)
(C) Learning from an unbalanced data set
(D) A model with high precision but low recall
Part (c) [1 mark]
Which loss would be most suitable for training a neural network for regression?
(A) Mean squared error plus weight decay * (1 marks)
(B) Backpropagation
(C) Cross entropy
(D) Delta rule
Part (d) [1 mark]
Which of the following activation func-tions are not compatible with back- propagation?
(A) f(x) = tanh(x)
(B) f(x) = max(0, x)
(C) f(x) = sign(x) * (1 marks)
(D) f(x) = (1 + e −x ) −1
Part (e) [1 mark]
Which of the following is true about con- volutional neural networks?
(A) Pooling/stride reduce the number of channels of an input image/feature map.
(B) Convolution is used to reduce the height/width of an input image/feature map.
(C) Convolving an input image/feature map having any number of channels with a single kernel produces a fea-ture map with one channel. * (1 marks)
(D) The order of operations used in a convolutional neural network is typically “Convolution-Pooling-Activation”.
Part (f) [1 mark]
Assume an input image of size 64×64 with 3 channels, and a model with a single con- volutional layer having 2 kernels of size 3x3, and 3 kernels of size 5×5. What are the total number of convolutional weights you need to learn? Assume there are no bias terms.
(A) (2 × 3 × 3 × 3) + (3 × 3 × 5 × 5) * (1 marks)
(B) (2 × 3 × 3) + (3 × 5 × 5)
(C) (64 × 64 × 3) + (2 × 3 × 3) + (3 × 5 × 5)
(D) 64 × 64 × 3 × 3 × 5 × 5
Part (g) [1 mark]
Which of these computes the gradients in PyTorch?
(A) optimizer.zero_grad()
(B) optimizer.step()
(C) loss.backward() * (1 marks)
(D) loss = criterion(model(inputs), labels)
Part (h) [1 mark]
Which of the following is correct?
(A) Smaller batch sizes typically allow using larger learning rates.
(B) We optimize the weights on training set and the hyper-parameters on the test set.
(C) We can increase the learning rate as training progresses.
(D) For the problems discussed in class, neural networks are typically unable to find the global optimal. 1 (
(E) marks)Using a standard adaptive learning rate method reduce the memory usage.
Part (i) [1 mark]
Suppose we have an input image of size 3×15×15 and we apply a kernel of size 3×4×4 with padding of size 2 and stride of 1, followed by a pooling with kernel size of 4×4 and strides of 4. What are the di- mensions of the output?
(A) 3×4×4
(B) 1×4×4 * (1 marks)
(C) 3×8×8
(D) 1×8×8
Part (j) [1 mark]
Which of the following is incorrect about convolutional neural networks?
(A) They are more efficient compared to fully-connected net-works.
(B) As we go deeper, height and width are decreased while depth is increased.
(C) We can use either convolution with strides or pooling layers to reduce the depth. * (1 marks)
(D) Kernels of size 3×3 can approximate bigger kernel sizes.
Question 2. [10 marks]
In this question we will consider neural networks (NNs) with sigmoid activation functions of the form
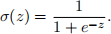
If we denote by vj(l) the value of neuron j at layer l its value is computed as
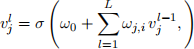
where L is the number of neurons in the previous layer (i.e. layer l − 1).
In the following questions you will have to design NNs that compute functions of two Boolean inputs X1 and X2 . Recall that Boolean variable can only take on of two value: 0 or 1. Given that the outputs of the sigmoid units are real numbers Y in the interval (0.0, 1.0), we will treat the final output as Boolean by considering it as 1 if greater than 0.5 and 0 otherwise.
Feel free to use a calculator or your computer for this question. Part (a) [4 marks]
Determine three weights ω0 ,ω 1 ,ω2 , for a single layer NN with two inputs X1 and X2 that implements the logical OR function Y = X1 OR X2 . Note that, as per the equation above, ω0 is the bias weight (sometimes called b). The definition of X1 OR X2 is provided in the table below.

Part (b) [4 marks]
Determine three weights ω0 ,ω 1 ,ω2 , for a single layer NN with two inputs X1 and X2 that implements the logical AND function Y = X1 AND X2 . The definition of X1 AND X2 is provided in the table below.

Part (c) [2 marks]
Is it possible to implement the XOR logical function with a single layer NN? The definition of X1 XOR X2 is provided in the table below. Explain your answer.

Question 3. [10 marks]
In the following network, we use softmax for the output activation function.

Part (a) [2 marks]
In the figure above, what is the missing output value? Why?
Part (b) [2 marks]
Assuming we are using one-hot encoding and the set of labels is {0,1,2,3}, What is the predicted label? Why?
Part (c) [3 marks]
Assuming we have 1000 samples in a training set. How many times do we update the weights of the network in an epoch in the case of:
- i) Stochastic Gradient Descent?
- ii) Mini-batch gradient descent with batch size of 50?
- iii) Batch gradient Descent?
Part (d) [3 marks]
Consider the following binary classification problem.
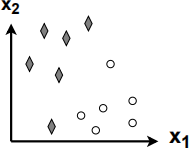
Using the following linear classifier:
f(X) = sign(ω0 + ω1x1 + ω2x2 ),
where sign(z) returns +1 (class 1, diamonds) for z > 0, otherwise it returns -1 (class 2, circles).
We try to minimize the following loss function in w = (ω0 ,ω 1 ,ω2 ) space:
J(w) = L(w) + λω0(2) ,
where L(w) = N/1 (total number of misclassif ied samples), N is the total number of samples and λ = 109 is a large constant. Which of the following is a possible decision boundary after the training? Explain your choice.
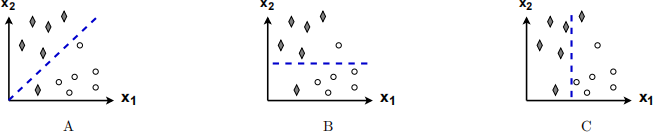
Question 4. [12 marks]
class SoDeep(nn.Module):
def init (self):
super(SoDeep, self) . init ()
self.layer1 = nn.Linear(in_features=32*32, out_features=64)
self.layer2 = nn.Linear(in_features=64, out_features=128)
self.layer3 = nn.Linear(in_features=128, out_features=4)
def forward(self, img):
flattened = img.view(-1, 32*32)
x = self.layer1(flattened)
x = self.layer2(x)
return self.layer3(x)
You are given a neural network architecture written in pytorch, as above. Note: You do not have to do the arithmetic to calculate any of the answers, writing the expression to calculate it is sufficient.
Part (a) [2 marks]
How many weights does layer1 have?
Part (b) [2 marks]
How many neurons does layer2 have?
Part (c) [2 marks]
How many hidden layers are there in this model?
Part (d) [2 marks]
Assume this is a classification model. How could you change it to be a regression model?
Part (e) [4 marks]
You train the model on a non-linearly separable data set, and the test accuracy is very poor. Another neural network of similar size and training hyper-parameters has much higher test accuracy.
What is wrong with the above code/architecture? Why exactly is this a problem?
Question 5. [10 marks]
For your course project,you decide to train a binary classifier to predict if your fellow students in the course have a pet cat or dog based on their student number. When you collected the data set you noticed the vast majority of students in your class have a cat (for which you assign the label True), and the remaing students all have a dog (label False). You evaluate your trained classifier by calculating the prediction accuracy on a test data set and get an accuracy of 90%, convincing yourself that you’ve solved this problem.
Part (a) [2 marks]
Why should you question the project itself, regardless of the results?
Part (b) [4 marks]
How do you explain the high test accuracy? What aspect of the data set caused this? Be as specific as possible. You can assume the training and test sets were randomly sampled without replacement from the entire data set, and the test data set is not used in training.
Part (c) [4 marks]
How could you have better evaluated your trained classifier? What would you have expected to see using this evaluation method that would have identified the problem?
Question 6. [9 marks]
class ConvNet(nn.Module):
def init (self):
super(ConvNet, self) . init ()
self.conv1 = nn.Conv2d(3, 5, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(5, 10, 5)
self.fc1 = nn.Linear(10 * 5 * 5, 32)
self.fc2 = nn.Linear(32, 1)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 10 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
Given the above convolution neural network, answer the following questions. Note: You do not have to do the arithmetic to calculate any of the answers, writing the expression to calculate it is sufficient.
Part (a) [2 marks]
What are the total number of weights in the convolutional layers?
Part (b) [2 marks]
What are the total number of weights in the fully-connected layers?
Part (c) [2 marks]
Suppose the size of an input image X is 128 (height) x 128 (width) x 3 (channels) (with this exact order) and we want to feed it to the network. Write a single line of code to properly format the input to NCHW format. Now suppose we want to resize the image to 3x64x64. Write a single PyTorch transform code to do that.
Part (d) [2 marks]
What is an appropriate loss function to use to train this network, assuming it’s trained on a classification problem? What if we increased the number of classes to 10?
Part (e) [1 mark]
Now, suppose that we want to increase the number of classes to 1000 and use Negative Log Likelihood loss (nn.NLLLoss()) to train the network. Beside changing the output size of fc2, What other change should we make?
