关键词 > APS360H1
APS 360 H1 Applied Fundamentals of Machine Learning Midterm Test Fall 2021
发布时间:2024-06-24
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
APS 360 H1
Fall 2021 Midterm Test
Applied Fundamentals of Machine Learning
Date : October 25th, 2021
Question 1. [10 marks]
Circle the best answer for each of the questions below. Do not circle more than one answer per question.
Part (a) [1 mark]
Which of these problems is best described as an unsupervised learning problem?
(A) Generating a random number
(B) Clustering an unlabelled data set * (2 marks)
(C) Finding the shortest path between two points of a graph
(D) Predict house prices from the size of house, given a dataset of house prices/sizes
Part (b) [1 mark]
Which of these best describes the concept of inductive bias?
(A) Bias of a machine learning algorithm learned from a training data set
(B) The assumptions we incorporate in our model to help learn to solve a problem * (2 marks)
(C) Learning from an unbalanced data set
(D) A model with high precision but low recall
Part (c) [1 mark]
Which of the following activation func-tions are not compatible with back-propagation?
(A) f(x) = tanh(x)
(B) f(x) = (1 + e−x) −1
(C) f(x) = sign(x) * (2 marks)
(D) f(x) = max(0, x)
Part (d) [1 mark]
Which of the following is true about con- volutional neural networks?
(A) Pooling/stride reduce the number of channels of an input image/feature map.
(B) Convolving an input image/feature map having any number of channels with a single kernel produces a fea- ture map with one channel. * (2 marks)
(C) The order of operations used in a convolutional neural network is typically “Convolution-Pooling-Activation” .
(D) Convolution is used to reduce the height/width of an input image/feature map.
Part (e) [1 mark]
Which loss would be most suitable for training a neural network for regression?
(A) Delta rule
(B) Back-propagation
(C) Mean squared error * (2 marks)
(D) Cross entropy
Part (f) [1 mark]
Suppose we have an input image of size 3×15×15 and we apply a kernel of size 3×4×4 with padding of size 2 and stride of 1, followed by a pooling with kernel size of 4×4 and strides of 4. What are the di- mensions of the output?
(A) 1×8×8
(B) 3×8×8
(C) 1×4×4 * (2 marks)
(D) 3×4×4
Part (g) [1 mark]
Which of these computes the gradients in PyTorch?
(A) optimizer.zero_grad()
(B) optimizer.step()
(C) loss.backward() * (2 marks)
(D) loss = criterion(model(inputs), labels)
Part (h) [1 mark]
Which of the following is correct?
(A) We optimize the weights on training set and the hyper- parameters on the test set.
(B) We can increase the learning rate as training progresses.
(C) Smaller batch sizes typically allow using larger learning rates.
(D) Using a standard adaptive learning rate method doubles the memory usage. * (2 marks)
Part (i) [1 mark]
Assume an input image of size 64 ×64 with 3 channels, and a model with a single con-volutional layer having 2 kernels of size 3x3, and 3 kernels of size 5 ×5. What are the total number of convolutional weights you need to learn? Assume there are no bias terms.
(A) (2 × 3 × 3 × 3) + (3 × 3 × 5 × 5) * (2 marks)
(B) (64 × 64 × 3) + (2 × 3 × 3) + (3 × 5 × 5)
(C) (2 × 3 × 3) + (3 × 5 × 5)
(D) 64 × 64 × 3 × 3 × 5 × 5
Part (j) [1 mark]
Which of the following is incorrect about convolutional neural networks?
(A) They are more efficient compared to fully-connected net-works.
(B) As we go deeper, height and weight are decreased while depth is increased.
(C) We can use either convolution with strides or pooling layers to reduce the depth. * (2 marks)
(D) Kernels of size 3×3 can approximate bigger kernel sizes.
Question 2. [8 marks]
You are given a data set to solve a problem and split this data into training and test data sets. You decide to train a deep neural network (NN) to solve the problem, however you are not sure what batch size to use.
Part (a) [4 marks]
Having a larger batch size gives us a better approximation of the gradient at a specific point in the optimization space (i.e. the space of points corresponding to model parameters that will be learned). Given this, is it always a good strategy to train with a large batch size? Why or why not?
Part (b) [2 marks]
Now suppose that you train many different NN models (each having different hyper-parameters), and you select the model with the best accuracy on the test set. Explain potential flaws with this methodology.
Part (c) [2 marks]
Propose a more effective methodology and also explain its drawbacks.
Question 3. [11 marks]
Provide concise answers to the following questions regarding training of neural networks.
Part (a) [2 marks]
Why is backpropagation easier in the output layer (i.e. the delta rule), than for hidden layers?
Part (b) [2 marks]
In the weight update rule for backpropagation/the delta rule, why do we subtract the gradient from the weights rather than add the gradient to the weights?
Part (c) [2 marks]
How does using momentum help training?
Part (d) [2 marks]
What are two important characteristics of all activation functions used in modern neural networks trained with backpropagation.
Part (e) [3 marks]
Assume we have a dataset of 20,000 examples and we sample mini-batches of size 20. How many iterations are there in one epoch if we train with: (a) stochastic gradient descent, (b) mini-batch gradient descent, and (c) batch gradient descent? Note we are using the strict definition of stochastic gradient descent here.
Question 4. [10 marks]
During hyperparameter tuning of a neural network model, we encountered different loss vs. epoch plots. Each of the following plots corresponds to a set of hyperparameters. Pick the best set of hyperparameters among the plots below (Write ”The best” in front of the set name). For the remaining sets, suggest a change in hyperparameters() for each that may result in better performance.
Part (a) [2 marks]
SET A
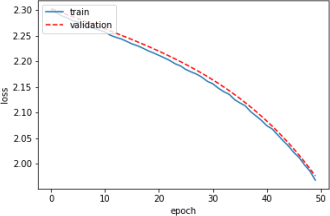
Part (b) [2 marks]
SET B
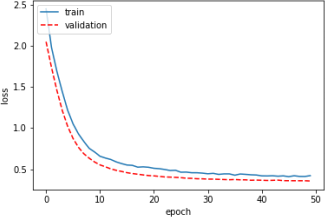
Part (c) [2 marks]
SET C
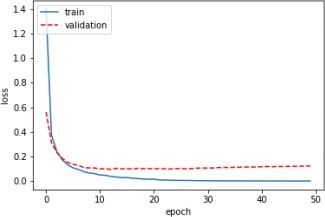
Part (d) [2 marks]
SET D
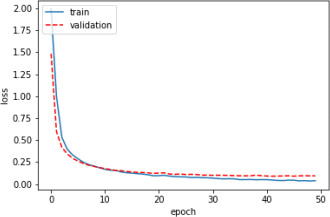
Part (e) [2 marks]
SET E
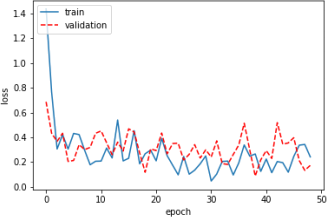
Question 5. [14 marks]
Given the code below, for a binary neural network classifier, answer the following questions.
1 def __init__ ( self ) :
2 super ( MLP , self ) . __init__ ()
3 self . firstLayer = nn . Linear (20 , 10)
4 self . middleLayer = nn . Linear (10 , 10)
5 self . lastLayer = nn . Linear (10 , 1)
6 def forward ( self , input ) :
7 activation1 = self . firstLayer ( input )
8 activation1 = F . relu ( activation1 )
9 activation2 = self . middleLayer ( activation1 )
10 activation2 = F . relu ( activation2 )
11 activation3 = self . middleLayer ( activation2 )
12 activation3 = F . relu ( activation3 )
13 activation4 = self . lastLayer ( activation3 )
14 return activation4
Part (a) [2 marks]
What is the input size of the network?
Part (b) [1 mark]
How many layers are in the network?
Part (c) [1 mark]
What is the total number of parameters in the network (including Biases)?
Part (d) [4 marks]
Which loss function should you use and Why?
Part (e) [2 marks]
How would you modify this network (including its loss) in order to classify days of the week (Mon, Tue, Wed, Thur, Fri, Sat, Sun)?
Part (f) [4 marks]
Below, you may find a part of the code used for training a Neural Network. There are 5 blank spaces (# ) for comments in the following code. From the list of the comments below, please put the number of each comment in the right place. (Number 1 is done as an example)
1. # backward pass
2. # update the weights
3. # forward pass
4. # reset gradients to zero
5. # loss calculation
1 for epoch in range ( num_epochs ) :
2 ...
3 for i , data in enumerate ( train_loader , 0) :
4 ...
5 optimizer . zero_grad () #___
6
7 outputs = net ( inputs ) #___
8
9 loss = criterion ( outputs , labels . float () ) #___
10
11 loss . backward () #___
12
13 optimizer . step () #___
14 ...
Question 6. [12 marks]
Consider the convolutional neural network (CNN) architecture below.
Part (a) [6 marks]
Complete the PyTorch code to achieve the architecture described in the diagram below. You may assume that all the necessary packages have already been imported, and that the code has no syntax errors. Note that the size mentioned under each block is the output size of that operation. For example, 8 × 64 × 64 is the size of the feature map that is generated by applying the first convolution to the input image.

1 class CNNClassifier ( nn . Module ) :
2 def __init__ ( self ) :
3 super ( CNNClassifier , self ) . __init__ ()
4 # Conv2d : in_ch , out_ch , kernel_size , stride , padding
5 self . conv1 = nn . Conv2d ( ____ , ____ , ____ , ____ , 1)
6 # Pool : kernel_size , stride
7 self . pool = nn . MaxPool2d ( ____ , ____ )
8 self . conv2 = nn . Conv2d ( ____ , ____ ,3 , ____ , ____ )
9 self . fc1 = nn . Linear ( ____ , ____ )
10 self . fc2 = nn . Linear ( ____ , ____ )
11
12 def forward ( self , x ) :
13 x = self . pool ( F . relu ( self . conv1 ( x ) ) )
14 x = self . pool ( F . relu ( self . conv2 ( x ) ) )
15 x = x . view ( ____ , ____ )
16 x = F . relu ( self . fc1 ( x ) )
17 x = self . fc2 ( x )
18 return x
Please fill in the blanks ( ) in the code block above.
Part (b) [3 marks]
While training this CNN, your GPU runs out of memory. What are three things you could do to avoid this error?
Part (c) [3 marks]
What changes would you need to make to remove the max pooling layers and still maintain the overall network architecture (i.e. deminsionality of Conv layers)? Indicate which lines of code need to be updated and provide the changes.
Question 7. [10 marks]
The following code is to be used for MNIST classification with images of 28 × 28 pixels. You may assume that all necessary packages have been imported and that the code has no syntax errors.
1 mnist_train = mnist_data [:3200]
2 mnist_val = mnist_data [3200:4224]
3
4 class MNISTClassifier ( nn . Module ) :
5 def __init__ ( self ) :
6 super ( MNISTClassifier , self ) . __init__ ()
7 # Conv2d : in_ch , out_ch , kernel_size , stride , padding
8 self . conv1 = nn . Conv2d (1 , 4 , 5)
9 # Pool : kernel_size , stride
10 self . pool = nn . MaxPool2d (2 , 2)
11 self . conv2 = nn . Conv2d (5 , 10 , 3)
12 self . fc1 = nn . Linear (250 , 32)
13 self . fc2 = nn . Linear (32 , 10)
14
15 def forward ( self , x ) :
16 x = self . pool ( F . sigmoid ( self . conv1 ( x ) ) )
17 x = self . pool ( F . sigmoid ( self . conv2 ( x ) ) )
18 x = x . view ( -1 , 250)
19 x = F . sigmoid ( self . fc1 ( x ) )
20 x = self . fc2 ( x )
21 return x
22
23 def train ( model , data , batch_size =32 , num_epochs =4) :
24 train_loader = torch . utils . data . DataLoader ( data , batch_size )
25 critereon = nn . CrossEntropyLoss ()
26 optimizer = optim . SGD ( model . parameters () , lr = 0.01 , momentum = 0.9)
27
28 for epoch in range ( num_epochs ) :
29 for imgs , labels in train_loader :
30 out = model ( imgs )
31 loss = critereon ( out , labels )
32 loss . backward ()
33 optimizer . step ()
34 optimizer . zero_grad ()
35
36 model = MNISTClassifier ()
37 train ( model , mnist_train , num_epochs = 2)
Part (a) [2 marks]
What is the total number of iterations in the above code? You may assume the code works as intended.
Part (b) [4 marks]
Determine the total number of parameters/weights in this model (including Biases).
Part (c) [4 marks]
The above code yields an error that the dimensions are not correct. How can you change the first convo- lutional layer to correct the error? Show your work.
Question 8. [10 marks]
Following are a series of questions based on deep learning architectures we’ve seen in the course.
Part (a) [2 marks]
One of the biggest challenges in deep learning has been the problem of vanishing or exploding gradients preventing us from training very deep models. Name two improvements that have helped address this problem.
Part (b) [2 marks]
GoogLeNet (or the Inception architecture) has many fewer weights than AlexNet, and yet achieves a higher accuracy on the ImageNet test set. What two changes from AlexNet are most responsible for this?
Part (c) [2 marks]
What are the two most important reasons AlexNet was able to demonstrate the potential of convolutional neural networks so successfully, as compared to LeNet decades before?
Part (d) [2 marks]
What is the (spatial) convolutional filter size used in the VGG architecture? How did the architecture justify using this filter size exclusively?
Part (e) [2 marks]
Your model has a layer, named layerX, used as follows: class MyModel(nn.Module):
def forward(self, img):
...
output = self.layerX(prev_output)
...
where prev_output is the output from the previous layer in the model. How would you change the code to add a residual (or skip) connection to layerX?
