关键词 > INFO20003
Exam: Database Systems (INFO20003_2023_SM1)
发布时间:2024-06-22
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Exam: Database Systems (INFO20003_2023_SM1)
Section 1: Relational Database Modelling + Implementation (25 Marks)
Question 1
Data Types
Select the most appropriate MySQL data types for the following pieces of information:
(Please make sure you read all options available to select the most correct!)
Auto-incremented primary key of table ‘Movies’ (movie_id: the theatre offers thousands of movies over time)
Number of family members on a family ticket
Does a ticket type include a complementary popcorn?
The customer’s 4 digit long Australian postcode
Total revenue the movie theatre made (including fractions of a dollar)
Movie ticket type (1 of 4 different choices: ‘children, ‘adults’, ‘concession’, ‘vip’)
Video trailer of the movie
Date of birth of a customer
Time and date that a customer purchased a movie ticket to print on a receipt
Name of a customer for ticket booking
Question 2
ER MODELLING
Bridgman Images manages copyright on behalf of many art galleries, museums, and libraries (“copyright owners”). Customer organisations that wish to use a copyrighted image created by an artist can pay a fee to Bridgman Images who will then provide a high-quality image for reproduction.
Bridgman Images needs to know which copyright owners have owned the copyright for an image since the artwork was created, the dates the ownership started and ended, and the fee paid for the copyright (e.g., “copyright owner: National Gallery of Victoria; from: 01/01/2016; to: 01/01/2018; fee: 10,000”). Each artwork may have been owned by many copyright owners, and at any one time multiple copyright owners may own the copyright for the one image.
About each copyright owner we need to know its unique organisation name, address, and phone numbers of the organisation. About the artist we store their first name, last name, birth year, and death year (e.g., Paolo Veronese, born 1528, died 1588). About each artwork we store its unique title (e.g., “The Wedding Scene at Cana”), type of artwork (e.g., painting), and the height and width in centimetres of the original artwork (e.g., H: 30.6cm W: 41.9cm). An artist produces many artworks, but each individual artwork in the Bridgman Images database is created by one artist.
The following ER model is a student’s attempt to model Bridgman Images. Identify all mistakes in the model that do not support this case study and describe what needs to be done to correct those mistakes. (E.g., Issue #1: a wrong relationship cardinality between entities X and Y. Fix #1: Replace the relationship from one to many on the X entity side.)
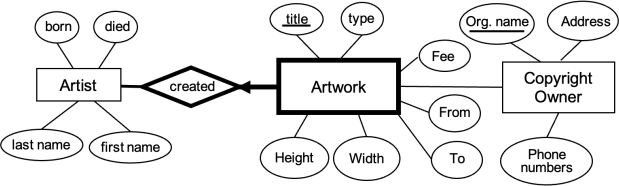
Question 3
DDL
In a particular education system, teachers regularly undergo a “performance review”. They are given an integer rating on their teaching quality and professional skills.
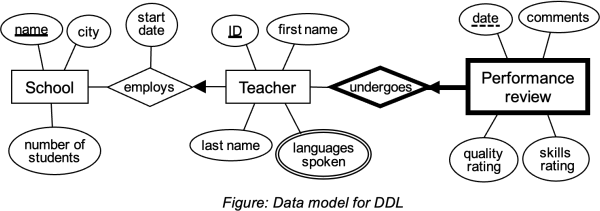
Write SQL statements to create the tables for the data model. Be sure to specify primary and foreign keys. You do not need to specify whether the fields are NULL / NOT NULL. Where the data type is not obvious, feel free to choose an appropriate data type.
Section 2: SQL & RA (24 Marks)
SQL Intro
Note: Do not use Views or Variables to answer these questions (same as with assignment 2).
The following data model and the description are the same as Assignment 2.
You and a group of fellow undergrads have created a start-up like Google Scholar called ‘newScholar’. newScholar is a free accessible web search engine that provides a broad range of information on scholarly publications. It also provides information on researchers and relations among scholarly publications and researchers.
For each researcher, newScholar records the researcher’s details such as first name, last name, and one email address. Each researcher can also be associated with a few keywords representing their ‘research area’, such as Databases, Machine learning, Psychology, Medicine, etc. For each researcher, newScholar maintains their list of publications. The researchers who author a publication together are called ‘co-authors’.
For each publication, newScholar stores its title, date of publication, start page number (e.g., 475), end page number (e.g., 500), and a list of authors (there can be multiple authors of a publication, where each author is a researcher). Each publication can also be associated with a few keywords representing its ‘research area’, such as Databases, Machine learning, Psychology, Medicine, etc. NewScholar database will not store the actual publications, but rather a link to the document objects. Each publication is linked to one document object. For each document object, newScholar stores the URL link and the document size in KB. Each publication has a list of references (i.e., it “cites” other publications), where each reference is another publication. If publication A is in the reference list of another publication B, then A is “cited by” B. Figure 1 shows an example publication with its basic information and its list of references.
NewScholar manually curates a list of top 10 publications every fortnight depending on the number of citations of the publications. A publication can make it to top 10 more than once over time. For each paper that is in the top 10 for a particular fortnight at a particular position, newScholar keeps a record of the start date when a publication reached that position (beginning of the fortnight) and end date (end of the fortnight). If a publication is again in the next fortnight’s top 10 (whether in the same position, or different), a new row is recorded, with the start/end dates being the start/end dates of this new fortnight. For example, the publication entitled “Learning to index” can be number 1 for the fortnight from January 1st - January 14th, 2022 but the rank drops to number 3 from January 15th - January 28th, 2022. This would result in 2x rows, one with position 1 and one with position 3. Note that we do not need to know the rationale why this is the current ranking.

Fig 1: An example of publication with title, authors, and the list of references
The Data Model
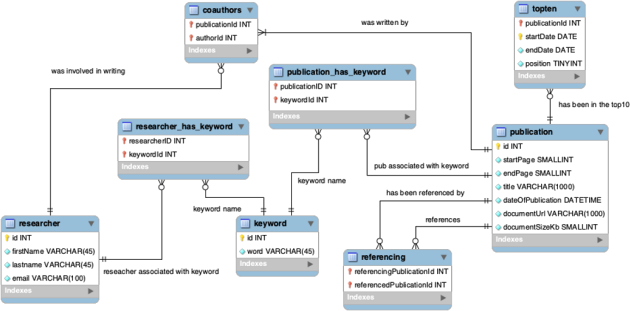
Fig 2: The physical ER model of newScholar startup database.
Question 4
SQL Q1
Find the title and URL of publications that have been featured at least once in the top ten list. Return as (title, documentUrl).
Question 5
SQL Q2
List keywords which have been included in at least 3 publications that were published on or after 01/01/2023. Return as (word, numPublications).
Question 6
SQL Q3
Find publications that were co-authored by at least one researcher in the ‘Databases’ area. The publications also must not reference a publication that is ten pages or longer. Return as (title, documentUrl).
Question 7
SQL Q4
A researcher is said to have co-authored an “expert publication” if the researcher and the publication share at least one common keyword. An “expert publication” is relative to the researcher: a publication that is an expert publication for one researcher might not be an expert publication for another researcher that also co-authored it (because the second researcher doesn’t have any keywords in common with the publication). For each researcher, count how many of the publications they have co-authored are expert publications relative to them. If a researcher has no expert publications, return their count as zero. Return as (researcherId, numExpertPublications). Below are some example cases to help you:
Researcher’s keywords Publication’s keywords Expert publication?
Databases, Machine Learning Databases Yes. At least one keyword (Databases) is in common.
Databases, Machine Databases, Machine Yes. At least one keyword (Databases and Machine Learning) is in common.
Learning Learning
Databases, Machine Learning Algorithms No. There are no keywords in common.
(no keywords) (no keywords) No. The researcher and publication have no keywords so there are no keywords in common.
Question 8
Relational Algebra Q1
For the following relational algebra query...

...select which of the following SQL queries are equivalent. (There may be more than one.)
SQL Query A
SELECT title
FROM publication
NATURAL JOIN coauthors
WHERE dateOfPublication > '2023-01-01' AND authorId = 3;
SQL Query B
SELECT title
FROM publication
INNER JOIN coauthors
ON publication.id = coauthors.publicationId
WHERE dateOfPublication > '2023-01-01' AND authorId = 3;
SQL Query C
SELECT title
FROM coauthors
INNER JOIN publication
ON publication.id = coauthors.publicationId
WHERE authorId = 3 OR dateOfPublication > '2023-01-01';
SQL Query D
SELECT title
FROM publication
INNER JOIN coauthors
ON coauthors.publicationId = publication.id
GROUP BY dateOfPublication, authorId
HAVING dateOfPublication > '2023-01-01' AND authorId = 3 ;
SQL Query A
SQL Query B
SQL Query C
SQL Query D
Question 9
Relational Algebra Q2
For the following relational algebra query...
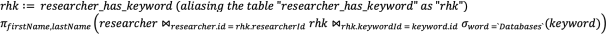
...select which of the following SQL queries are equivalent. (There may be more than one.)
SQL Query A
SELECT firstName, lastName
FROM researcher
INNER JOIN researcher_has_keyword AS rhk
ON researcher.id = rhk.researcherId
INNER JOIN keyword
ON rhk.keywordId = keyword.id ;
SQL Query B
SELECT firstName, lastName
FROM researcher
INNER JOIN researcher_has_keyword AS rhk
ON researcher.id = rhk.researcherId
INNER JOIN keyword
ON rhk.keywordId = keyword.id AND word = 'Databases';
SQL Query C
SELECT firstName, lastName
FROM researcher
NATURAL JOIN researcher_has_keyword AS rhk
NATURAL JOIN (
SELECT id AS keywordId
FROM keyword
WHERE word = 'Databases'
) T;
SQL Query D
SELECT firstName, lastName
FROM researcher
INNER JOIN researcher_has_keyword AS rhk
ON researcher.id = rhk.researcherId
NATURAL JOIN (
SELECT id AS keywordId
FROM keyword
WHERE word = 'Databases'
) T;
SQL Query A
SQL Query B
SQL Query C
SQL Query D
Section 3: Query Processing and Optimisation (27 Marks)
Single Relation Plan Intro
Consider a relation called Movies that stores information about the movies available to watch in Netflix. Imagine that the relation Movies consists of 1000 data pages and each page stores 100 tuples. Imagine that the duration of a movie can be any integer number between 0 to 500 minutes [0, 500] and the year of a movie can be any year between 1920 to 2020, that is, (1920, 2020]. Suppose that the following SQL query is executed frequently using the given relation:
SELECT MovieName
FROM Movies
WHERE duration < 250 AND year = 2000;
Question 10
Single Relation Plan A
Compute the estimated result size for the query, and the reduction factor of each filter.
RF(duration)
RF(year)
Result Size
Question 11
Single Relation Plan B
Compute the estimated cost of plan alternatives, assuming that a clustered B+ tree index on (duration) is (the only index) available. Suppose there are 100 index pages.
Give the lowest (estimated) cost in I/Os after considering all access methods available.
Enter the number as numeric (e.g. 20).
550
Question 12
Single Relation Plan C
What would happen if our query changed and became:
SELECT MovieName
FROM Movies
WHERE duration > 25 AND year = 2000;
Assuming that the clustered B+ tree index on duration from the previous question is the only index available, would the cost of the best plan change?
Yes, because the RF value will change leading to an expensive index scan
No, eventually the result size will stay same
No, the best plan is still the same.
Multi-relation Introduction
Consider two relations called Movies and Actors. Imagine that the relation Movies has 1000 pages and the relation Actors has 50 pages.
Consider the following SQL statement:
SELECT *
FROM Movies INNER JOIN Actors
ON Movies.MovieID = Actors.MovieID
WHERE Actors.country = ‘Australia’;
The following information is also available:
There are 12 buffer pages available in memory.
Both relations are stored as simple heap files.
Neither relation has any indexes built on it.
Consider Actors as the outer relation in all alternatives.
Assume that sorting can be performed in two passes for both relations. All selections are performed on-the-fly after the join.
Evaluate Nested Loops Join, Block-oriented Nested Loop Join, Sort Merge Join, and Hash Join using the number of disk I/Os as the cost.
Question 13
Multi Relation Plan A
Page-oriented Nested Loop Join (cost in I/Os). Enter the number as numeric (e.g. 20).
50,050
Question 14
Multi Relation Plan B
BLOCK-oriented Nested Loop Join (cost in I/Os). Enter the number as numeric (e.g. 20).
5,050
Question 15
Multi Relation Plan C
Sort-Merge join (cost in I/Os). Enter the number as numeric (e.g. 20).
5,250
Question 16
Multi Relation Plan D
Hash Join (cost in I/Os). Enter the number as numeric (e.g. 20).
3,150
Query Optimisation Introduction
Consider the following relational schema and SQL query. The schema captures information about shows, performances and the theatres where the shows have taken place.
Performance (PerformanceID (PK), name, genre, releasedate, duration, budget) Show (ShowID (PK), dateofShow, PerformanceID (FK), TheatreID (FK), attendance, revenu e) Theatre (TheatreID (PK), name, city, capacity)
Consider the following query:
SELECT *
FROM Performance AS P, Show AS S, Theatre AS T
WHERE P.PerformanceID = S.PerformanceID
AND S.TheatreID = T.TheatreID
AND S.revenue < ‘60,000’ AND P.genre = ‘Musical’;
The system’s statistics indicate that there are 10 different genres, and revenue ranges from 0 to 100,000 ([0,100,000]).
There is a total of 5000 performances, 60,000 shows and 1000 theatres in the database. For performances, shows, and theatre relations, 10 tuples fit in a page. Suppose there exists a clustered B+ tree index on Show.revenue of size 10 pages.
Compute the cost of the plans shown below.
Assume that sorting of any relation (if required) can be done in 2 passes.
NLJ is a Page-oriented Nested Loops Join.
Assume that 10 tuples of a resulting join between Performance and Show fit in a page. Similarly, 10 tuples of a resulting join between Show and Theatre fit in a page.
If selection over filtering predicates is not marked in the plan, assume it will happen on-the-fly after all joins are performed, as the last operation in the plan.
Question 17
Query Optimisation Plan 1
Compute the following results for the below Plan 1:
1. The result size of the child join in pages (marked as 'A' in the diagram)
2. The cost of the child join in I/Os (marked as 'B' in the diagram). Consider 'Performance' as the outer.
3. The cost of the parent join in I/Os (marked as 'C' in the diagram)
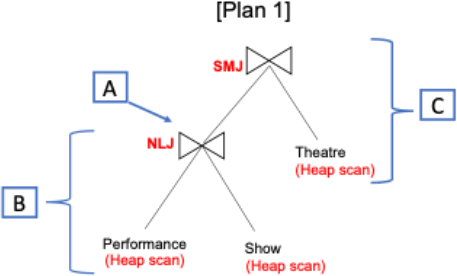
ResultSize of child join in PAGES (marked A in diagram)
Cost of child join in I/Os (marked B in diagram).Consider 'Performance' as the outer.
Cost of parent join in I/Os (marked C in diagram)
Question 18
Query Optimisation Plan 2
Compute the following results for the below Plan 2:
1. The result size of the selection on revenue in pages (marked as 'A' in the diagram)
2. The result size of the child join in pages (marked as 'B' in the diagram)
3. The cost of the selection on revenue in I/Os (note this also accounts for the index access cost as well) (marked as 'C' in the diagram)
4. The cost of the child join in I/Os (marked as 'D' in the diagram)
5. The cost of the parent join in I/Os (marked as 'E' in the diagram)
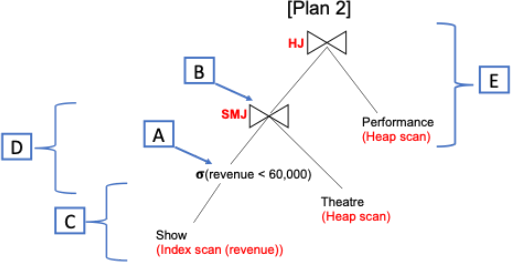
The result size of the selection on revenue in PAGES (marked as 'A' in the diagram)
The result size of the child join in PAGES (marked as 'B' in the diagram)
The cost of the selection on revenue in I/Os (note this also accounts for the index access cost as well) (marked as 'C' in the diagram)
The cost of the child join in I/Os (marked as 'D' in the diagram)
The cost of the parent join in I/Os (marked as 'E' in the diagram)
The result size of the selection on revenue in PAGES (marked as 'A' in the diagram)
The result size of the child join in PAGES (marked as 'B' in the diagram)
The cost of the selection on revenue in I/Os (note this also accounts for the index access cost as well) (marked as 'C' in the diagram)
The cost of the child join in I/Os (marked as 'D' in the diagram)
The cost of the parent join in I/Os (marked as 'E' in the diagram)
Section 4: Normalisation (10 marks)
Normalisation Intro
The table below contains a list of codes of conduct violations by students and the fines imposed in the Harry Potter College:
StudentTicket (studentID, LastName, FirstName, PhoneNo, Ticket, Date, Code, Fine)
studentID LastName FirstName PhoneNo Ticket Date Code Fine
900344 James Richard 0452-345123 15634 10/10/18 2 $25
900344 James Richard 0452-345123 16017 13/09/19 1 $15
1094560 Portman Natalie 0469-693426 14987 10/05/19 3 $100
1094560 Portman Natalie 0469-693426 16293 24/08/19 1 $15
1094566 Green Sandra 0401-345908 17892 16/12/18 2 $25
The pair (Ticket, studentID) is the candidate key for this relation. The following functional dependencies hold for this relation:
studentID -> LastName, FirstName, PhoneNo
Ticket -> Date, Code, Fine
Code -> Fine
Question 19
Normalisation A
In what normal form is the 'StudentTicket' table?
1st Normal Form
2nd Normal Form
3rd Normal Form
Not in any normal form
Question 20
Normalisation B
Could any anomalies arise in the 'StudentTicket' relation above? If yes, discuss which anomalies and problems may occur, and provide an example for each of them.
Question 21
Normalisation C
Normalize the 'StudentTicket' relation to 3rd Normal Form (3NF). For each step explicitly identify which normal form is violated and briefly explain why. Write the normalised tables in a textual format. Here's an example step:
...
Table x not in 2nd NF because of y. Normalised to 2nd NF is:
RelationName (id(PK), Column, ForeignKeyColumn(FK))
AnotherRelation (id(PK), Column, AnotherColumn(PFK))
...
