关键词 > INFO20003
Exam: Database Systems. (INFO20003_2022_SM1)
发布时间:2024-06-20
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Quiz: Exam: Database Systems. (INFO20003_2022_SM1)
Section 1: Relational Database Modelling + Implementation (25 marks)
Question 1
Data Types
Select the most appropriate MySQL data types for the following pieces of information:
The expiry date of a product
An employee’s sign-off time
Did Cathy test positive for COVID?
A person’s mobile phone number in Australia with +61 prefix (followed by 9 numbers)
A global enterprise’s annual revenue
Auto-incremented primary key of table ‘Student’
A person’s age
A 16-digit long credit card number
One out of 4 positions of an academic in a university – Lecturer, Senior Lecturer, Associate Professor, or Professor
Video demonstration of an electric appliance
Question 2
ER Modelling A
Assuming that common sense applies, which one of the following ER model fragments is most believable?
ER-ModellingA.png
Option A
Option B
Option C
Option D
Question 3
ER Modelling B
A group of students was asked to draw a Conceptual ER model in Chen’s notation for a booking system of accommodation.
Each accommodation is identified by a unique identifier number. The system also stores the address, number of rooms, check-in time, and check-out time of each accommodation. Each accommodation is assigned a single type (e.g., villa, motel, etc.), but each type can be assigned to multiple accommodations. A unique type identifier and a description is associated with each accommodation type. For each booking, the system stores the check-in date, check-out date, number of rooms booked, and the total number of guests for that booking. Each booking is made by a single person. The system will store the first name, last name, a unique email address, date of birth, and at most two credit card numbers of the person that made a booking.
Below are the attempts by the students. Identify the ER model that addresses all the requirements of this case study.
ERmodellingB.png
Option A
Option B
Option C
Option D
Question 4
DDL
In a language school franchise “Dream Big” in Australia teachers regularly undergo a performance review. Every year, they are given an integer rating ([1,10]) on their teaching quality and professional skills. For each teacher, the list of languages spoken is recorded in addition to their names. Since the school has many branches, for each individual branch we store its unique name, the city where it resides, and the number of students currently attending.
Write SQL statements to create the tables for the data model shown below. Be sure to specify primary and foreign keys. You do not need to specify whether the fields are NULL/NOT NULL. Where the data type is not obvious, feel free to choose an appropriate data type.
DDL.png
Given the values of attributes in the table BOOK shown below, answer the two following questions:
BOOK

Question 5
Using the BOOK table answer the following questions.
Is the set (Category, Circulation) a superkey of this table?
Is the set (ID, Title) a superkey of this table?
Is the set (ID, Title) a key of this table?
Question 6
Write down all possible candidate keys of this table (given the data currently in the book table)
Section 2: SQL & RA (24 marks)
SQL Intro
Please note that the following data model and the description is the same as Assignment 2.
Description
You and a group of fellow undergrads have created a start-up called ‘newQuora’. The company’s goal is to create an online question-and-answer forum for users around the world.
The system has two kinds of users: general and admins. Most user attributes are straightforward personal information and are listed in the ER diagram below.
Discussions are organized into forums, each of which is about a particular topic. New forums can be opened by admins. Users can subscribe to any number of forums to get regular updates.
Users can create a ‘post’ in any forum, which becomes a topic for discussion. Any user can comment on a post, or on comments of a post (nested comments). Users can also “upvote” a post or comment.
General users (but not admins) can have different “relationships” among themselves. One user can be “following” another to receive updates when they post or comment. Note that following is a non-symmetric relation: if A is following B, that does not imply B is following A. A is denoted as a “follower” of B.
General users (but not admins) can also add each other to friend-lists. When one user sends a friend-request to another, the latter can reject or accept the friendship. If the latter accepts, the pair are now friends. Note that friendship is a symmetric relation: if A is a friend of B, then B is a friend of A, whether A sent the friend request to B or vice-versa. Once a pair of users are friends, either may later unfriend the other, in which case the friendship ends for both. A user’s “friends” means their current “confirmed” friends, not those where the friendship has ended or not begun.
Data model
sqlDatamodel.png
Figure 1: The physical ER model
Notes on implementation:
Posts + Comments:
Comments are stored in the same table as Posts, and are connected to their parent posts/comments via a unary relationship.
Posts have a NULL FK for their ‘parentpost’.
Comments have a non-null ‘parentpost’ FK.
Both posts and comments can be ‘parentposts’, i.e. users can comment on posts or on another comment. A post/comment can be the ‘parentpost’ of many comments, but a comment will only have one ‘parentpost’.
sqlExamplePost.png
Figure 2: An example of a forum with post + comments, and how this relates to the `parentpost` and `forum` attributes in the post table.
Friendships:
We record when a friend request is made, and accepted/rejected/confirmed in the FriendOf table. newQuora does not allow you to send a friend request to a user that you have rejected or unfriended, and there is no way for the other person to send another friend request to you if you have rejected or unfriended them.
`User1` in the friendOf table was the user that sent the friend request.
The phrase ‘ A is a current friend of B’ indicates that when the query is run, there is a row in the friendof table where (A is user1 and B is user2 OR A is user2 and B is user1) AND (the friend request was confirmed, and has not been unfriended)
Question 7
SQL Q1
Find the first names of all admin users. Return as (user_firstname).
Question 8
SQL Q2
Find the usernames of any general users that have posted more than 3 times to the forum with a topic of ‘databases’ (assume only one forum has this topic). Order results so that the user who has the highest number of posts in this forum is at the top of the results. Return as (username, number_of_posts_in_forum).
Question 9
SQL Q3
Let a user's "number of unsubbed posts" mean the total count of posts made by a user that were either a) not in a forum at all or b) in a forum which the user is not currently subscribed to.
EG if a user BOB is only subscribed to Forum X (no other forums), and has made 4 posts:
Post 1 was in Forum X
Post 2 was in Forum Y
Post 3 was in Forum Z
Post 4 was NOT IN A FORUM
Bob's "number of unsubbed posts" is 3. (posts 2,3,4 are not in a subscribed forum or have no forum at all)
Your task:
Find the user who has the highest “number of unsubbed posts”. Return as (username, number_of_ unsubbed_posts).
Question 10
SQL Q4
For all general users, find how many total upvotes they have received from their current friends vs how many they have received from users that are not currently their friend. Return as (username, number_of_upvotes_friends, number_upvotes_others).
Question 11
RA 1
For each of the relational algebra below, state whether they are correct or not for the following statement:
List the topics of forums where the general user with user id “1” has posted at least once before the date “01-01-2022”.
ra1.png
A
B
C
D
Question 12
RA 2
For each of the relational algebra below, state whether they are correct or not for the following statement:
Display the content of all the posts in the forums that is created by admin with id ‘2’, where these posts have been upvoted in 2022.
ra2.png
A
B
C
Section 3: Query Processing and Optimisation (27 marks)
Single Relation Plan Intro
Consider a relation called Products that stores information about ordered products from a store. Imagine that the relation Product consists of 1000 data pages and each page stores 100 tuples. Imagine that the totalprice attribute can take any value between 0 and 10000 ([0,10000]), and imagine that quantity can take any value between 1 and 100, specifically [1,100]. Suppose that the following SQL query is executed frequently using the given relation:
SELECT productType
FROM Products
WHERE totalprice < 5000 AND quantity = 20;
Question 13
Single Relation Plan A
Compute the estimated result size for the query, and the reduction factor of each filter.
RF(totalprice)
RF(quantity)
Result Size (tuples)
Question 14
Single Relation Plan B
Assume that an unclustered B+ tree index on (quantity) is the only index available. Suppose there are 100 index pages.
Give the lowest estimated cost (in I/0s) after considering all access methods available for completing this query.
Enter the number as numeric (e.g. 20).
Question 15
Single Relation Plan C
What would happen with the cost if our query changed and became:
SELECT productType
FROM Products
WHERE totalprice < 8000 AND quantity = 10;
Assuming that the unclustered B+ tree index on quantity from the previous question is the only index available, would the cost of the best plan change?
Yes, because the RF value will change leading to an expensive index scan
No, because the RFs change
No, because the result size will stay the same
No, the result size changes, but best plan cost is still the same
Multi-Relation Plan Intro
Consider two relations called Patient and Diagnosis. Imagine that the relation Patient has 20 pages and the relation Diagnosis has 10000 pages. Consider the following SQL statement:
SELECT *
FROM Patient INNER JOIN Diagnosis
ON Patient.patientID = Diagnosis.patientID
WHERE Diagnosis.test = ‘GTT’;
There are 12 buffer pages available in memory. Both relations are stored as simple heap files. Neither relation has any indexes built on it.
Evaluate Nested Loops Join, Block-oriented Nested Loop Join, Sort Merge Join and Hash Join using the number of disk I/O's as the cost. Consider Patient as the outer relation in all alternatives. Assume that sorting can be performed in two passes for both relations. All selections are performed on-the-fly after the join.
Question 16
Multi-Relation Plan A
Page-oriented Nested Loop Join (cost in I/Os). Enter the number as numeric (e.g. 20).
Question 17
Multi-Relation Plan B
Block-oriented Nested Loop Join (cost in I/Os). Enter the number as numeric (e.g. 20).
Question 18
Multi-Relation Plan C
Sort-Merge Join (cost in I/Os). Enter the number as numeric (e.g. 20).
Question 19
Multi-Relation Plan D
Hash-join (cost in I/Os). Enter the number as numeric (e.g. 20).
Query Optimisation Introduction
Consider the following relational schema and SQL query. The schema captures information about employees, the sales they made and the items that are sold.
Employee(EmpID PK, firstname, lastname, position, salary, phonenumber)
Order(OrderID PK, dateofOrder, ItemID FK, EmpID FK, quantity, totalcost)
Item (ItemID PK, ItemType, price, description)
Consider the following query:
SELECT *
FROM Employee AS E, Order AS O, Item AS I
WHERE E.EmpID = O.EmpID
AND O.ItemID = I.ItemID
AND O.totalcost > 5000 AND E.position = ‘Junior executive’;
The system’s statistics indicate that there are 20 different position levels, and total cost of an order ranges from 0 to 10,000 ([0,10,000]) since some items may be offered free of cost depending on any reward option availed by the employee ordering.
There is a total of 1000 employees, 600,000 orders and 10,000 items in the database. Each relation fits 100 tuples in a page. Suppose there exists a clustered B+ tree index on Order.totalcost of size 50 pages, and a clustered B+ tree on Item.ItemID, of size 10 pages.
Assume that 100 tuples of a resulting join between Employee and Order fit in a page. Similarly, 100 tuples of a resulting join between Order and Item fit in a page.
Assume that sorting of any relation (if required) can be done in 2 passes.
NLJ is a Page-oriented Nested Loops Join.
If selection over filtering predicates is not marked in the plan, assume it will happen on-the-fly after all joins are performed, as the last operation in the plan.
Compute the cost of the plans shown below.
Question 20
Query Optimisation Plan 1
Compute the following results for the below Plan 1:
1. The result size of the child join in pages (marked as 'A' in the diagram)
2. The cost of the child join in I/Os (marked as 'B' in the diagram)
3. The cost of the parent join in I/Os (marked as 'C' in the diagram)
plan1.jpeg
The result size of the child join in PAGES (marked as 'A' in the diagram)
The cost of the child join in I/Os (marked as 'B' in the diagram)
The cost of the parent join in I/Os (marked as 'C' in the diagram)
Question 21
Query Optimisation Plan 2
Compute the following results for the below Plan 2:
1. The result size of the selection on revenue in pages (marked as 'A' in the diagram)
2. The result size of the child join in pages (marked as 'B' in the diagram)
3. The cost of the selection on totalcost in I/Os (note this also accounts for the index access cost as well) (marked as 'C' in the diagram)
4. The cost of the child join in I/Os (marked as 'D' in the diagram)
5. The cost of the parent join in I/Os (marked as 'E' in the diagram)
Plan2.jpg
The result size of the selection on revenue in PAGES (marked as 'A' in the diagram)
The result size of the child join in PAGES (marked as 'B' in the diagram)
The cost of the selection on totalcost in I/Os (note this also accounts for the index access cost as well) (marked as 'C' in the diagram)
The cost of the child join in I/Os (marked as 'D' in the diagram)
The cost of the parent join in I/Os (marked as 'E' in the diagram)
Section 4: Normalisation (10 marks)
Normalisation Intro
The table below is part of the screen writers billing records for the Publishers Guild:
Consultation (CusNo, Name, Agency, Writer, Rating, Mobile, Order, Prod_ID, Prod_Desc)
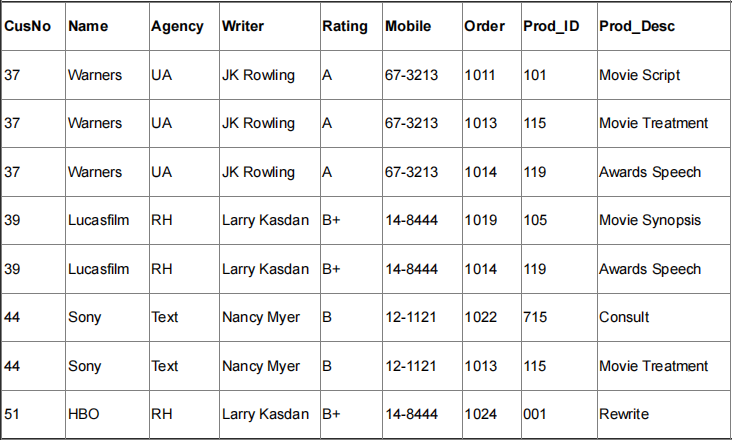
The following functional dependencies hold:
CusNo -> Name, Agency
Writer -> Rating, Mobile
Order -> Prod_ID, Prod_Desc
The set {CusNo, Order} is a candidate key, consider this to be the primary key when answering questions below.
Question 22
Normalisation A
In what normal form is the 'Consultation' table
1NF
2NF
3NF
Not in any normal form
Question 23
Normalisation B
Could any anomalies arise in the 'Consultation' relation above? If yes, discuss which anomalies and problems may occur, and provide an example of each.
Question 24
Normalisation C
Normalize the 'Consultation' relation to 3rd Normal Form (3NF). For each step explicitly identify which normal form is violated and briefly explain why. Write the normalised tables in a textual format. Here's an example step:
...
Not in xNF because of y. Normalised to xNF is:
RelationName (id(PK), Column, ForeignKeyColumn(FK))
AnotherRelation (id(PK), Column, AnotherColumn(PFK))
...
Section 5: Data warehousing (12 marks)
Data Warehousing Introduction
You’ve been hired by “Not A Bank” Bank to help create a data warehouse to track customers’ spending data. Your model will pull data from many other databases and use advanced A.I. (with dozens of ‘if’ statements) to classify purchases into a 'category'.
Answer Questions A-C using the following model:
DataWarehouse.png
Question 25
Data Warehousing A
This data model is ...
A star schema as it contains dimensions and a fact table
A snowflake schema as it has more than 4 standard dimensions.
A snowflake schema as it has hierarchical dimensions.
Neither a snowflake nor a star schema
Question 26
Data Warehousing B
Match the aspects/components to their role in the model (choose the most specific role/term that applies).
Amount
Business
BankExpenditure
Country
TypeCategory
‘Customer making a purchase’
Question 27
Data Warehousing C
Which of these queries could be answered using the above model
What was the total expenditure amount by customers with a ‘high’ IncomeBracket between June 1 and June 30th in 2021?
How many purchases were made in Melbourne, Vic, Australia, at a business whose name contains the word “woolworths”?
Are customers over the age of 40 more likely to make purchases at MelbourneCentral or at MelbourneEmporium? (both are located in the Melbourne CBD locality).
Find customers that have spent more on purchases with a type of ‘gamer gear’ than on ‘food’.
How many people purchased alcohol at 2/2/22, 2:22pm?
Find the total spending at businesses on the 14th of June 2022 grouped by their average review rating.
Question 28
Data Warehousing D
“Data warehouses often involve large data stores compared to most Transactional Databases”. Which of these reasons account for that?
Datawarehouses are often denormalized, thus duplicate data, which requires more storage space
Relational DBMS like MySQL are more optimized and efficient compared to a datawarehouse DBMS
Datawarehouses aggregate data from many sources (eg perhaps multiple transactional databases)
Datawarehouses are subject to inefficiencies when people manually insert the data into the datamarts.
Datawarehouses contain all of the data that is encompassed in the OLTP databases that they model, so must be at least as big as any one of them
Section 6: Database Concepts (27 marks)
Question 29
Transactions A
Transactions are not necessary on a database that only has a single user at any one time.
True
False
Question 30
Transactions B
How many separate transactions (implicit + explicit) are present in this SQL? Enter the number as numeric (e.g. 2).
SELECT * FROM employees;
BEGIN;
SELECT * FROM employees WHERE name = ’bob’;
UPDATE employees
SET salary = salary * 1.03;
COMMIT;
SELECT * FROM customers;
BEGIN;
UPDATE customers
SET special_reward_rate = special_reward_rate + 1 ;
COMMIT;
Transactions C Intro
Imagine two processes, P1 and P2. Both of these processes each begin their own transaction within the database at approximately the same time. P1 is trying to calculate the average grade for students in INFO20003. P2 is simultaneously trying to update the grades of 2 INFO20003 students.
Unfortunately, it turns out one of the tutors disabled transaction isolation at some point by accident, so there’s no guarantee that these transactions have executed in a serializable manner!
One possible interleaving is given below. The 'y axis' of the table indicates time (eg actions in the 1st row occur BEFORE actions on the second row, etc).
TIME P1 (Transaction #1) P2 (Transaction #2)
0 Read(Student1Grade = 80)
1 Read(Student1Grade = 80)
2 Write(Student1Grade = 83)
3 Read(Student2Grade = 70)
4 Read(Student2Grade = 70)
5 Write(Student2Grade = 75)
6 Read(Student3Grade = 60)
Answer the following questions:
