关键词 > CP1407
Practical 3 Clustering Review: K-Means & Hierarchical clustering
发布时间:2024-06-18
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Practical 3
Clustering Review: K-Means & Hierarchical clustering
|
What are we doing? |
The purpose of this prac isto understand working principle of these two clustering algorithms including K-means and Hierarchical clustering throughout an example data.
Submission:
You are required to submit one document containing the solution of the last task given in this practical.
|
Hierarchical Clustering |
Let’s consider eight data points with two dimensions x andy as candidates for
hierarchical clustering. The data points, along with dimensional values and scatter plot, are given in the figure as below:
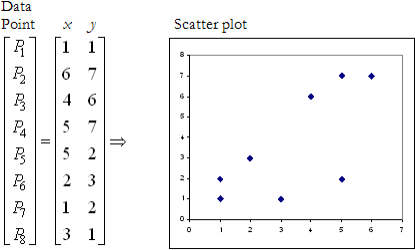
We use the Manhattan distance** function and the single-linkage method using a distance threshold for the merging. Start with a threshold of 0 and increment it with 1 at each level
** Manhattan distance (City-block distance):
This distance is simply the addition of all the distances across dimensions, calculated by the following function: Manhattan distance (A, B) =∑i |(xi − yi )|
The process is described as a sequence of the following steps:
Step 1
At the beginning, each element Pi is a cluster on its own, and therefore, the set of clusters are: (0, 8, {{P1}, {P2}, {P3}, {P4}, {P5}, {P6}, {P7}, {P8}})
Distance matrix
|
|
P1 |
P2 |
P3 |
P4 |
P5 |
P6 |
P7 |
P8 |
|
P1 |
0 |
11 |
8 |
10 |
5 |
3 |
1 |
2 |
|
P2 |
|
0 |
3 |
1 |
6 |
8 |
10 |
9 |
|
P3 |
|
|
0 |
2 |
5 |
5 |
7 |
6 |
|
P4 |
|
|
|
0 |
5 |
7 |
9 |
8 |
|
P5 |
|
|
|
|
0 |
4 |
4 |
3 |
|
P6 |
|
|
|
|
|
0 |
2 |
3 |
|
P7 |
|
|
|
|
|
|
0 |
3 |
|
P8 |
|
|
|
|
|
|
|
0 |
Step 2 (Distance level 1)
We seek to find the minimum Manhattan distance between the points. We can see that this threshold is now 1 and occurs between the points P1, and P7 , and also
between the points P2, and P4. We combine the two to form the cluster P1P7 and
P2P4 and remove those as individual clusters from the set to get the new cluster set:
(1, 6, {{P3}, {P1, P7}, {P2, P4}, {P5}, {P6}, {P8}})
Distance matrix
|
|
P1P7 |
P2P4 |
P3 |
P5 |
P6 |
P8 |
|
P1P7 |
0 |
9 |
7 |
4 |
2 |
2 |
|
P2P4 |
|
0 |
2 |
5 |
7 |
8 |
|
P3 |
|
|
0 |
5 |
5 |
6 |
|
P5 |
|
|
|
0 |
4 |
3 |
|
P6 |
|
|
|
|
0 |
3 |
|
P8 |
|
|
|
|
|
0 |
Step 3 (Distance level 2)
The minimum distance is now 2 (using single-linkage strategy). This is between P3, and P2P4, between P6, and P1P7, and between P8, and P1P7. We get:
(2, 3, {{P2, P3, P4}, {P5}, {P1, P6, P7, P8}})
Distance matrix
|
|
P2 P3P4 |
P5 |
P1P6P7P8 |
|
P2 P3P4 |
0 |
5 |
5 |
|
P5 |
|
0 |
3 |
|
P1P6P7P8 |
|
|
0 |
Step 4 (Distance level 3)
The minimum distance is now 3 (using single-linkage strategy) between P5, and P1P6P7P8. Thus putting them in one cluster, we get:
(3, 2, {{P2, P3, P4}, {P1, P5, P6, P7, P8}})
Step 5 (Distance level 5 – skip level 4)
All points are in one cluster. The clustering process is complete.
The corresponding dendrogram formed from the hierarchy is presented here:
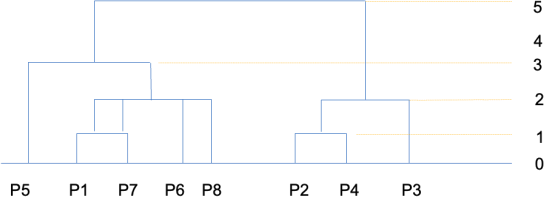
This demonstrates that in hierarchical clustering a nested set of clusters is created and each level in the hierarch has a separate set of clusters. At the root level, all items belong to one cluster, and at the leaf level each item is in its own unique cluster.
|
Non-hierarchical Clustering (K-Means) |
Let’s consider the same dataset of the previous example (P1~P8) to find two clusters using the k-means algorithm. The computation proceed as follows:
Step 1
Arbitrarily, let us choose two cluster centres to be the data points P5 (5,2) and P7
(1,2). Their relative positions can be seen in the figure below. We could have started with any other two points. The initial selection of points does not affect the final result.
![]()
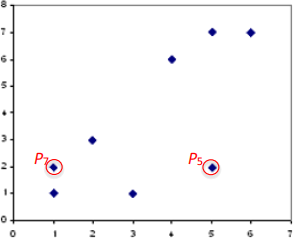
Step 2
Let us find the Euclidean distances of all the data points from these two cluster centres.
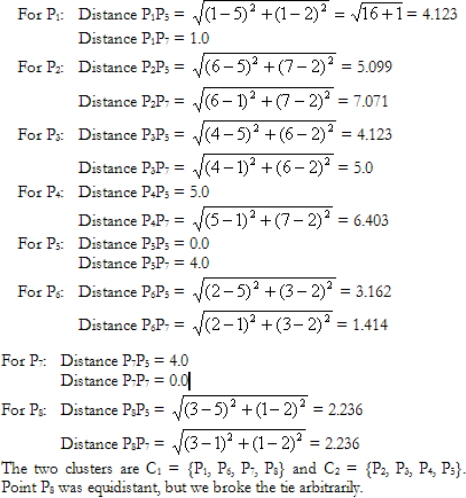
Step 3
The new cluster centres are:
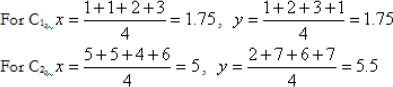
Step 4
The distances of all data points from these new cluster centres are:
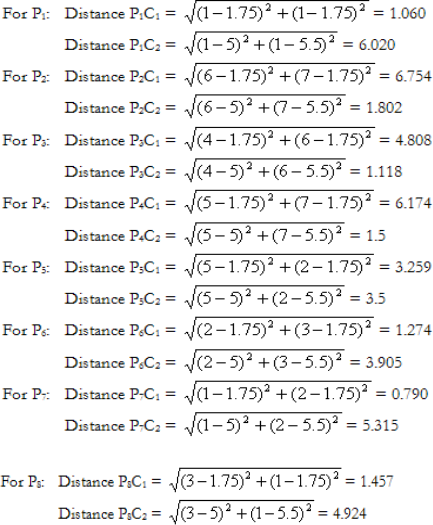
Step 5
By the closest centre criteria P5 should be moved from C2 to C1, and the new clusters are C1={P1, P5, P6, P7, P8} and C2={P2, P3, P4}.
The new cluster centres are:
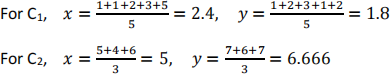
Step 6
If we repeat the computations of Step 4, we will find that no data point will switch
clusters. Therefore, the iteration stops and the final clusters are C1={P1, P5, P6, P7, P8} and C2={P2, P3, P4}.
|
Practice on Clustering |
Draw the dendrogram for the first six points (P1, P2, P3, P4, P5, P6) of the example
data set we used in this practical previously, after applying the hierarchical clustering algorithm.
|
Laboratory Questions |
Open bank_data.csv in weka. Run Hierarchical clustering for both single and
complete link. Compare the dendograms. Next, run K-means clustering for both ‘Euclidean’ and ‘Manhattan’ distance metric. Compare your results.
Submit your solution to LearnJCU.
