关键词 > Python代写
FCP Summative Assessment
发布时间:2024-06-18
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
FCP Summative Assessment
Introduction
Opinion dynamics aims to understand how views spread through a population- how long does it take for everyone to like a certain song or settle on a side in a political debate? Simple models of opinion dynamics can be developed using ODEs, or as discrete models on a grid. However, these structures do not capture the complex social relationships people have (i.e most of us interact with more than 4 people!). Better models of opinion dynamics instead used networks to model these social relationships, allowing us to understand how opinions spread through a human population. In this assignment, you will work as a group to implement a number of models for understanding how opinions spread through a population, allowing you to identify the effect of key parameters.
The assignment will assess your ability to:
1. Translate from a description of a mathematical model into working code for simulating that model.
2. Write Python code that adheres to a given specification, in part validated by automatic test functions.
3. Work with a group to develop code that is not only correct, but also easy to read.
4. Make effective use of version control tools such as Git.
Submission
This assignment is to be completed in groups of four. You should work together to produce a single codebase, but each person should contribute some individual parts to the code. The core assignment has 5 sections, and the first four of these can be completed independently of each other- you may want to assign each of these tasks to one group member. The final part will require you to integrate these bits of code, and is best tackled as a group. Also note, that you are expected to work together- if one team member is struggling, you are expected to work together to help them out!
Each member of your group should submit your work via Blackboard. Submission should consist of:
1. Code (submitted as a single .zip file)
2. Reflection report (submitted individually)
3. A readme.txt, explaining what you've implemented, how to run it, and including a link to a shared Github repo.
The deadline for this assessment is 1pm, May 2nd. Each person should expect to spend 12-15 hours on this assignment (including the 6 hours available during lab sessions).
Assessment
Each of the five tasks has been allocated a number of points (totalling 100). For each task, half the points are allocated for correctness, and half allocated for readability. We will evaluate correctness by running the tests functions we have provided you with, by running the test functions we have asked you to write (and checking that they cover all the cases we would expect), and by comparing whether the output is as described in the "What we expect to see section". We will evaluate readability based on your use of functions to organise code, your use of comments, variables names and function names to make it clear how your code works, and your use of Git (i.e consistently making commits with informative commit messages).
Task 1: The Ising Model (15 points)
The first model we’ll consider involves a population of people who can hold opinions either for or against an issue- we'll model this by assigning them a value, , equal to +1 (for) or –1 (against). The key assumption we'll make in this model is that people want to hold similar opinions to there neighbours, and are more likely to change their opinion if everybody around them disagrees. We can capture this principle by calculating, the agreement, , the amount that person, , agrees with their immediate neighbours:
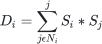
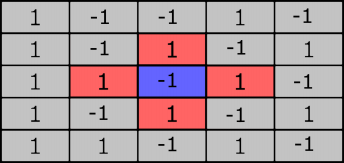
where represents the neighbours of person . In this model, we'll initially model our population using a numpy array, and assume that each person's neighbours are those immediately adjacent in the grid (i.e we count those above, below, left and right, but not connected diagonally). In the image below, the neighbours of the cell in blue are shown in red.
If a person agrees with a neighbour, then the product will be positive. If a person disagrees, the signs of and will be different and so the product will be negative. This suggests the first approach we can use for understanding how opinions spread through a population- we can repeatedly pick a random person and then calculate . If is positive, then that person agrees with a majority of their neighbours and shouldn't change their opinion. If is negative, then they should flip their opinion.
This simple model can be extended in two ways. First, we can introduce the fact that although people generally want to agree with their neighbours, they won't always do so- some people will stand for their principles even in the face of disapproval of their neighbours. We can introduce this by sometimes flipping an opinion even when is positive. In this model, we choose to accept flips that reduce agreement with probability . This captures that flips that only reduce by a small amount are more likely than those that increase it by a large amount.
The variable represents how tolerant a society is of those who disagree with their neighbours- if is large, then the fraction will be small, regardless of the value of . As is close to 1 for values for close to 0, large will lead to a high probability of flips- this society is tolerant of those who disagree. As is reduced, the chance of a flip reduces.
Secondly, we can introduce the effect of an external pull on opinions (representing, for example, a prevailing opinion in the media). We can include this by adding a term to the equation for calculating disagreement, H, where H represents the strength of the external opinion. The equation for then becomes:
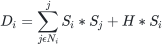
The code given in "FCP_assignment.py" partially implements this model- we've written the main function and some code for plotting the grid. However, the function for calculating the change in "agreement" has not been implented (currently it just returns a random value), nor have the two extensions been implemented. Your task is to complete the code by implementing the function calculate_agreement and updating the main function to include flips that increase disagreement.
How you'll know your code is correct
We've included the test function, test_ising that we'll use to make sure your code is correct. I should be able to run this function by running your code with the flag test_ising. If the overall model is correct, then you should see that for small values of , large islands of a particular opinion coalesce over time. As you increase , the size of these islands should decrease, until the system remains disordered throughout the simulation. Increasing the external opinion in either direction should bias the model towards that direction. Note that as this is a stochastic (i.e using randomness) model, your output won't be exactly the same as shown here, but the general trend should be observed.
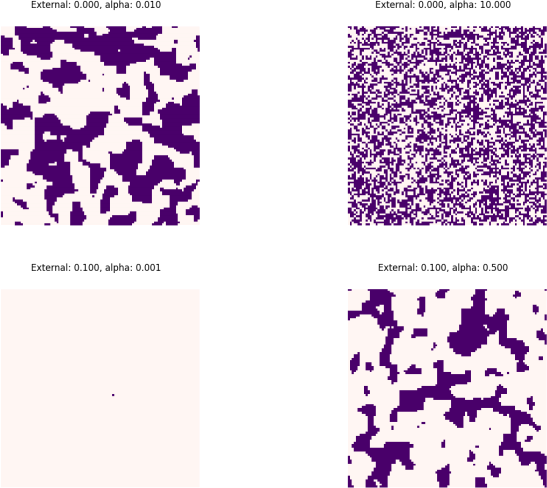
What I expect to see when I assess your code
I should be able to run this model from the command line by calling your program with the flag -ising_model . Your code should default to using a value of H=0, unless I also include the flag -external
$ python3 assignment.py -ising_model #This should run the ising model with default parameters
$ python3 assignment.py -ising_model -external -0.1 #This should run the ising model with default temperature and an external inf
$ python3 assignment.py -ising_model -alpha 10 #This should run the ising model with no external influence but with a temperature
$ python3 assignment.py -test_ising #This should run the test functions associated with the model.
Task 2: Defuant Model. (20 points)
The second model we'll consider represents opinions on a continous scale, [0, 1]. Here, we again use the principle that people want to agree with their neighbours, but we'll also limit that agreement to people whose opinion is within some distance of ours- essentially, people don't want to listen to somebody whose opinion is radically different to their own. We'll model this by repeatedly choosing a random person, and then a random neighbour of that person. If the two selected people have a difference of opinion greater than a threshold, nothing happens. If their difference of opinion is less than the threshold, then we update both people's opinions, by moving them towards the mean opinion. Mathematically, we can describe this as:
if |xi(t) − xj(t)| < T
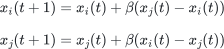
where , is the threshold for interaction, and is a coupling parameter- if is large, then each update will cause both neighbours to adjust their opinions strongly towards the mean. If is small, each update will only cause small changes towards the mean. Your task is to implement this model on a 1D grid. This means each person in the population only has two possible neighbours- one to the left and one to the right. You should include some plotting to solution of the model and some test functions to make sure your code is working correctly.
How you'll know your code is correct
You should include a function test_defuant to check whether your model is correctly updating opinions. Make sure to cover the basic behaviour of the model and any edge cases. I should be able to call your test function by running your code with the flags -test_defuant . If the overall model is correct, I should see an initially random distribution of opinions begin to separate into distinct clusters. Increasing the value of should increase the rate at which these clusters form, while decreasing the threshold should increase the number of clusters. For a threshold around 0.5, I would expect to see the model evolve to a single cluster (i.e everybody converges to a single opinion). As the threshold is reduced, I should see more clusters begin to emerge.
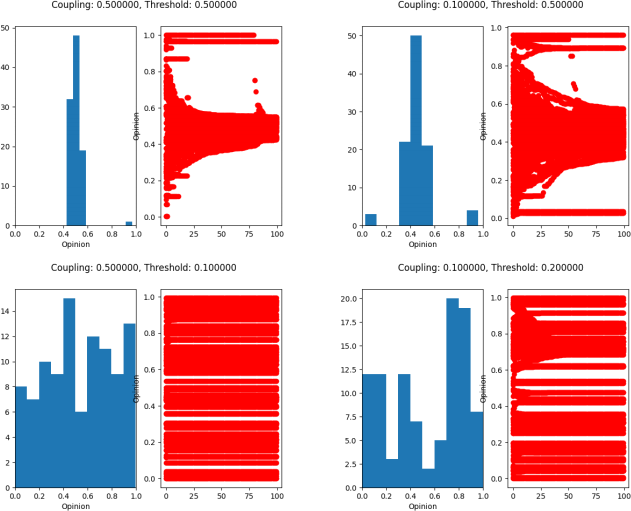
In these plots, the first is simply a histogram of the population for the last timestep. The second plot has the timestep on the x-axis, and the value of each member of the population at that timestep on the y axis.
What I would expect to see when I assess your code
I should be able to run this model from the command line by calling your program with the flag -defuant . Your code should default to using a value of = 0.2 and a threshold of 0.2. I should be able to adjust these values with optional flags -beta and -threshold . When ran, your code should solve the model using the specificed parameters, and produce a figure similar to the two shown above.
$ python3 assignment.py -defuant #This should run the defuant model with default parameters
$ python3 assignment.py -defuant -beta 0.1 #This should run the defuant model with default threshold and a beta of 0.1.
$ python3 assignment.py -defuant -threshold 0.3 #This should run the defuant model with a threshold of 0.3
$ python3 assignment.py -test_defuant #This should run the test functions that you have written.
Task 3: Networks (20 points)
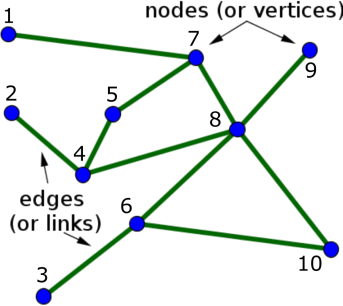
Both models above consider the spread of opinion on grids- each person has either 2 or 4 neighbours. In practice, these are not the kinds of relationships we see in real life. A better way to model the relationships between people is with a graph. A graph consists of a set of nodes, , connected by a set of edges, . Nodes and are connected by edge . By using a graph to model the relationships between people, we can get a better model of how opinions spread in the real world. Before we can update our models to use a graph, rather than a grid, we need to implementing some basic functionality for working with networks.
It's relatively easy to make networks with random connectivity. Unfortunately, such networks don't really resemble the kind of networks we see in the real world. Before we can look at generating some more realistic networks, we need a way to deciding whether a network structure is realistic or not. To do this, we can calculate certain quantities, comparing whether our networks produce similar values to those seen in real data. The metrics we will consider are:
1. Mean degree. The degree of a node is simply the number of edges it has- if a node is connected to 2 other nodes, it has a degree of 2. The mean is simply the average of the degree of all nodes in the network. In image above, node 1 has a degree of 1, while node 7 has a degree of 3.
2. Mean path length. The path length is the distance between two nodes- you can find this by using e.g. breadth-first-search. For a given node, the mean path length is the mean distance to all nodes it is connected to. If node 3 is connected to nodes 1 and 2, and node 2 is also connected to node 4, then node 3 has two paths of length 1 (to nodes 1 and 2) and one path of length 2 (to node 4), giving an an average path length, , of . For a network, the mean path length is the average of over all nodes in the network.
3. Mean Clustering co-efficient. The clustering coefficient measures the fraction of a node's neighbours that connect to each other, forming a triangle that includes the original node. We can calculate the number of possible connections between a node's neighbours using the formula , where is the number of neighbours. For a node with 3 neighbours,there are possible connections (and therefore 3 possible triangles that the original node could appear in). If there is 1 connection between these 3 neighbours, then The clustering coefficient is 1/3. We can then find the mean clustering coefficient for the network by averaging over for all nodes in the network.
We've given you some code that defines a Node class (for representing individual nodes) and a Network class for representing the graph. Currently, this class has methods for creating a random network of specified size (A node has probability of being connected to any other node), and a method for plotting the network. Your task is to complete the code for calculating the three metrics described above.
How you'll know your code is correct
We have included some test functions for you to check whether these parts are implemented correctly. I should be able to run these functions by calling your code with the flag -test_networks .
What I would expect to see
I should be able to create and plot a network of size N by calling your program with a flag -network
$ python3 assignment.py -network 10 #This should create and plot a random network of size 10
Mean degree:
Average path length:
Clustering co-efficient:
$ python3 assignment.py -test_network #This should run the test functions that we have provided
Task 4: Small world networks. (15 points)
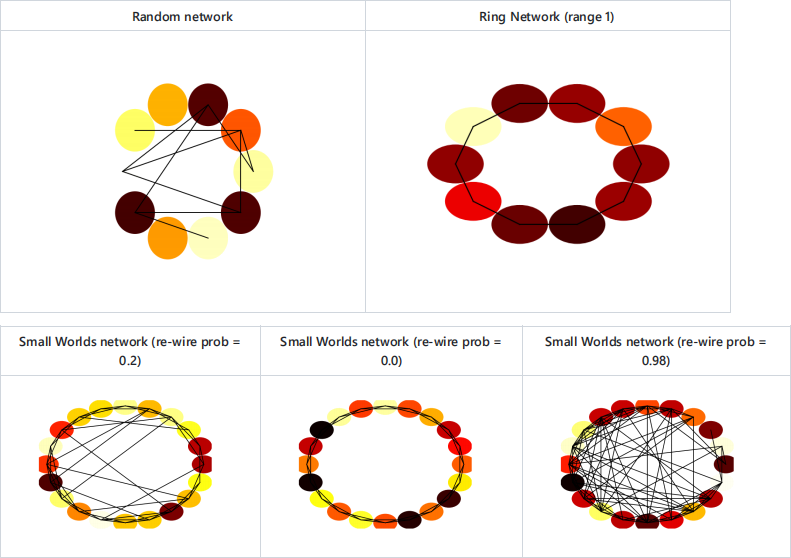
In a ring network, a node is connected to all nodes within a specificed range- i.e for a range of 1, the node with index 5 is connected to nodes 4 and 6, while with a range of 2, its connected to 3, 4, 6, and 7. A more realistic network structure is a so-called small worlds network. We can make a small world network by starting with a ring network of range 2, and then for each edge, with probability p, we "re-wire" it, by changing the destination to a randomly selected node (but disallowing self-connections or repeat connections).
Your task is to implement a function for creating ring and small world networks.
How you'll know your code is correct
Small world networks are charactised by having higher clustering co-efficients and lower mean path lengths than random networks of a similar size. If you set the re-wiring probability very low, you should produce a ring network. If you set it very high, you should produce a random network. In between these regions, you should produce a small-worlds network.
What I would expect to see when assessing your code
I should be able to create and plot a network of size by calling your program with a flag -ring_network
$ python3 assignment.py -ring_network 10 # This should create a ring network with a range of 1 and a size of 10
$ python3 assignment.py -small_world 10 #This should create a small-worlds network with default parameters
$ python3 assignment.py -small_world 10 -re_wire 0.1 #This should create a small worlds network with a re-wiring probability of 0
Task 5: Opinion formation on networks. (20 points)
Now that you have a model for opinion formation (on a grid) and some code for creating a network, you can adapt your model(s) to use a network to capture the social connections between people. To do this, you will need to modify how your models select which neighbours to interact with; rather than randomly selecting an adjacent index, you should instead select from the set of connected nodes.
Your task is to modify either the Ising or Defuant model to use a network rather than an array or grid. You should do this by modifying your Ising or Defuant model to optionally take a network as an input. If no network is provided, your code should default to using an array or a grid. If a network is provided, the model should be solved using the network instead.
What I expect to see when assessing your code
I should be able to run either the defuant or ising model on a network by includig the flag -use_network
$ python3 assignment.py -ising_model -use_network 10 #This should solve the ising model on a small world network of size 10.
$ python3 assignment.py -defuant -use_network 10 #This should solve the defuant model on a small world network of size 10.
Task 6
You must also submit an individual report, reflecting on the project, your individual contribution, and your success working as a team. The template for the reflective report is available on Blackboard. Note that as part of your reflective report, you will be asked if you are happy to share the same mark among all members of your group. If everyone agrees, then everybody in the group will get the same mark. Otherwise, each student will get a different mark based on our assessment of individual contribution. This will be based on engagement during group meetings, commits recorded in git, and the contents of the reflection reports.
