关键词 > CSCI-UA.0480
CSCI-UA.0480-003 Parallel Computing Exam 2 (Final) Spring 2020
发布时间:2024-06-15
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CSCI-UA.0480-003
Parallel Computing
Exam 2 (Final)
Spring 2020
[Total: 100 points]
1. Suppose that MPI_COMM_WORLD consists of the four processes 0,1, 2, and 3, and suppose the following code snippet is executed (my_rank contains the rank of the executing process in MPI_COMM_WORLD) [Note: The code shown here is just part of a bigger program. It is not a full- fledged program.].
|
int x, y, z; MPI_Comm COMM; int new_rank; MPI_Comm_Split(MPI_COM_WORLD, my_rank%2, my_rank, &COMM); MPI_Comm_rank(COMM, &new_rank); switch(new_rank) { case 0: x=11; y=12; z=10; MPI_Reduce(&x, &y, 1, MPI_INT, MPI_SUM, 0, COMM); MPI_Allreduce(&y, &z, 1, MPI_INT, MPI_SUM, COMM); break; case 1: x=3; y=8; z=5; MPI_Reduce(&x, &z, 1, MPI_INT, MPI_SUM, 0, COMM); MPI_Allreduce(&y, &x, 1, MPI_INT, MPI_SUM, COMM); break; default: x=8; y=9; z=11; MPI_Reduce(&z, &y, 1, MPI_INT, MPI_SUM, 0, COMM); MPI_Allreduce(&x, &y, 1, MPI_INT, MPI_SUM, COMM); MPI_Bcast(&y, 1, MPI_INT, 1, COMM); break; } |
a. [5 points] Is there a possibility of deadlock in the above code? If yes, describe the scenario that leads to the deadlock. If not, prove that all collective calls called by the processes will not be blocked forever.
b.[12 points] For each one of the four processes (IDs 0, 1, 2, 3, and 4 in the original MPI_COMM_WORLD) what will be the values of x, y, and z after the execution of the above code.
c. [5 points] How many processes will execute the “default” part of the switch case? What are their process IDs in the original MPI_COMM_WORLD? Justify your answer.
d. [4 points] Can a process have more than one ID (i.e. multiple ranks)? If yes, describe a scenario. If not, explain why not.
e. [4 points] After the execution of the above code, how many communicators exist? What are they?
2. [5 points] Can two processes share the same cache memory? Justify your answer.
|
3. [10 points] If we run two processes on a single core, we expect that the sequential version of the program will be faster than the parallel version where two MPI processes run on that single core. Describe two scenarios where two MPI processes running on a single core give a better performance than the sequential program. |
|
4. [10 points] Suppose we have two MPI processes and we run them on a processor with two cores. Describe two scenarios where we can get better performance if we run these two processes on a processor with four cores instead of two. |
5. [10 points] Suppose we have the following code snippet for OpenMP
|
#pragma omp parallel for for( i = 0; i < 600; i++) compute(i); |
The following figure shows the amount of computations done in compute(i) for each value of i. The code as indicated above uses the default schedule. Modify the code to use better schedule(s) given the information about computations shown in the figure. Add 1-2 lines explaining your logic for picking the schedule(s) that you used.
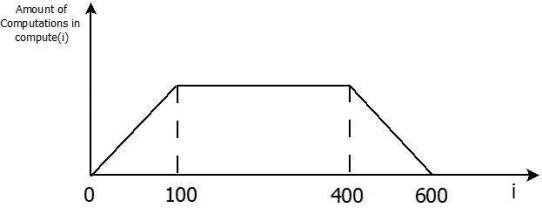
6. [5 points] Assume we are multiplying an 8000x8000 matrix A with vector y. Each element of the matrix and vector is double float. We are parallelizing this multiplication operation using four threads in OpenMP, such that thread 0 will be responsible for the first 2000 elements of the solution vector, thread 1 for the following 2000 elements, and so on. Also assume that each thread will execute on a separate core. Each core has its own private L1 cache. If the cache line has a size 64 bytes. Is it possible for false sharing to occur at any time between threads 0 and 2? Explain.
7. [5 points] We have seen that threads in a warp in CUDA execute instructions in a lockstep. Despite that, there may be scenarios where threads belonging to the same warp can finish before other threads belonging to that same warp. Describe one such scenarios.
8. For the following vector multiplication kernel and the corresponding kernel launch code, answer each of the questions below. Assume Ad, Bd, and Cd have been declared earlier. For each question below, show the steps you used to reach your answer.
|
1 __global__ void vecMultKernel (float* Ad,float* Bd,float* Cd, int n) |
|
2 { |
|
3 int i = threadIdx.x + (blockDim.x * blockIdx.x * 2); |
|
4 |
|
5 if (i < n) { Cd[i] = Ad[i] * Bd[i]; } |
|
6 i += blockDim.x; |
|
7 if (i < n) { Cd[i] = Ad[i] * Bd[i]; } |
|
8 } |
|
9 |
|
10 int vectMult (float* A, float* B, float* C, int n) |
|
11 { |
|
12 /* n is the length of arrays A, B, and C. |
|
13 int size = n * sizeof (float); |
|
14 cudaMalloc ((void **)&Ad, size); |
|
15 cudaMalloc ((void **)&Bd, size); |
|
16 cudaMalloc ((void **)&Cd, size); |
|
17 cudaMemcpy (Ad, A, size, cudaMemcpyHostToDevice); |
|
18 cudaMemcpy (Bd,B, size, cudaMemcpyHostToDevice); |
|
19 |
|
20 vecMultKernel<<<ceil (n / 2048), 1024>>> (Ad, Bd, Cd, n); |
|
|
|
21 cudaMemcpy (C, Cd, size, cudaMemcpyDeviceToHost); |
|
22 } |
a. [3 points] If the number of elements n of the A, B, and C arrays is 10,000 elements each, how many warps are there in each block? Show your calculations to get full credit.
b. [3 points] If the number of elements n of the A, B, and C arrays becomes 100,000 elements each, how many warps are there in each block? Show your calculations to get full credit.
c. [3 points] What is the CGMA of line 5? Show how you calculate it. You can disregard the computations involved in condition evaluation “if (i < n)” .
d. [4 points] Explain the effect of using shared memory in the above code to reduce global memory access.
e. [4 points] If n = 2048, how many warps will suffer from branch divergence in lines 5 and 7? Explain.
f. [3 points] If another kernel is launched in that same program. Will that kernel be able to access the data in Cd? Justify your answer.
9. [5 points] We know that CUDA does not allow synchronization among threads in different blocks. Suppose CUDA allows this. State one potential problem that may arise and explain clearly.
