关键词 > CSCI-UA.0480
CSCI-UA.0480-051: Parallel Computing Final Exam 2021
发布时间:2024-06-14
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CSCI-UA.0480-051: Parallel Computing
Final Exam (May 17th, 2021)
Total: 100 points
Problem 1
Suppose we have the following DAG, where each node represents an instruction. The table shows the amount of time taken by each instruction. Assume we are talking about machine level instructions, not high-level instructions.
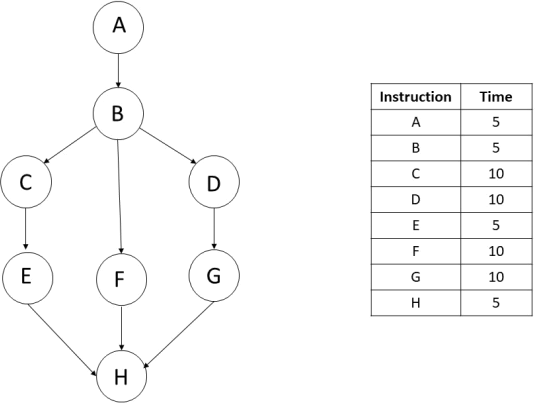
a. [5] Suppose we execute the above DAG on a single core processor. This core executes one instruction at a time and does not support neither hyperthreading nor superscalar capabilities. You can neglect the effect of pipelining too. How long does this core take to finish executing the whole program? To get full credit, show the steps you did to reach the final answer.
b. [5] Repeat the above problem but assume we have four cores. Each one of these cores is like the core described in question “a” above.
c. Suppose we have four cores like problem “b” above. We want to aggregate the instructions in the DAG to form threads. Indicate:
. [3] How many threads you will form?
. [2] Give each thread a unique ID starting from 0.
. [3] Which instructions go into which thread, to get the best speedup?
. [2] Calculate that speedup and show all steps.
d. [5] What is the minimum number of threads that you can form, assuming four-core processor, that gives you the highest efficiency? Show all steps. [Hint: Assume Efficiency = speedup/#threads].
Problem 2
Assume the following three processes in MPI and the operations they do at each time step of the same program. Also assume that the reduction operation is MPI_SUM.
|
Time |
Process 0 |
Process 1 |
Process 2 |
|
0 |
x = 6; y = 7; |
x = 8; y = 9; |
x = 5; y = 6; |
|
1 |
MPI_Allreduce(&x, &y, …) |
MPI_Allreduce(&y, &x, …) |
MPI_Allreduce(&x, &y, …) |
|
2 |
MPI_Allreduce(&y, &x, …) |
MPI_Allreduce(&x, &y, …) |
MPI_Allreduce(&x, &y, …) |
[6] Fill in the following table with values of x and y in each process:
After Step 1:
|
|
Process 0 |
Process 1 |
Process 2 |
|
x |
|
|
|
|
y |
|
|
|
[6] After Step 2:
|
|
Process 0 |
Process 1 |
Process 2 |
|
x |
|
|
|
|
y |
|
|
|
a. [4] Suppose each one of the above processes is parallelized with OpenMP with two threads. So, we have three processes and each one is parallelized with two threads. Will the values you calculated above change? If yes, specify how (no need to recalculate, just specific what factors affect them). If not, explain why not.
b. [4] Suppose that the original program, the one with three processes but no OpenMP, is executed on a single-core processor. Will the values you calculated above change? If yes, specify how (no need to recalculate, just specific what factors affect them). If not, explain why not.
c. [6] If, for some reason, one of the three processes crashes after step 1 but before executing step 2. What will happen to the rest of the program? Justify.
Problem 3
Suppose we have the following code snippet is running on a four-core processor :
1. #pragma omp parallel for num_threads(8)
2. for(int i = 0; i <N; i++){
3. for(intj = i; j < N; j++){
4. array[i*N + j] = (j-i)!;
5. }
6. }
(a) [5 points] How many iterations will each thread execute from the outer loop (line 2)? Justify
(b) [5 points] Will each thread executes the same number of iterations of the inner loop (line 3)? Explain.
(c) [5 points] Is there a possibility that (line 4) is a critical section? Justify.
(d) [24 points, 3 for each entry] For each one of the following scenarios, indicate how many threads will be created and what is the maximum number of threads that can execute in parallel given the code shown above. The number of cores is fixed as indicated at the beginning of this problem.
|
Scenario |
#threads created |
Maximum #threads in parallel |
|
Cores do not support hyperthreading but have superscalar capability |
|
|
|
Cores do not support hyperthreading and do not have superscalar capability |
|
|
|
Each core is two-way hyperthreading and supports superscalar capability |
|
|
|
Each core is four-way hyperthreading and supports superscalar capability |
|
|
Problem 4
[10] GPU Questions:
Choose one answer only from the multiple choices for each problem. If you pick more than one answer, you will lose the grade of the corresponding problem.
1. Suppose a block is composed of 50 threads. How many warps will be created for this block?
a. 1 b. 2 c. 4 d.5 e. Depends on the total number of blocks.
2. A block size cannot be smaller than a warp size.
a. True b. False c. Depends on the compute capability of the GPU.
3. If we have two local variables in the kernel, they will surely go to registers.
a. True b. False c. Depends on the compute capability of the GPU.
4. More than one block can be assigned to the same SM at the same time.
a. True b. False c. Depends on the compute capability of the GPU.
5. If you organize the block as 3D, the performance will always be worse than 1D or 2D blocks.
a. True b. False
6. The program has full control over how many warps will be created for a specific kernel.
a. True b. False
7. Suppose we launch a kernel as follows: kernelname <<<8,8>>>(argument list …); And suppose the kernel has a local variable x. How many instances of x will we have?
a. 8 b. 16 c. 64 d. Depends on whether the block is 1D, 2D, or 3D.
8. Suppose we launch a kernel as follows: kernelname <<<8,8>>>(argument list …); And suppose the kernel has a shared variable x. How many instances of x will we have?
a. 8 b. 16 c. 64 d. Depends on whether the block is 1D, 2D, or 3D.
9. If we do not use if-else in our kernel, then we will surely not suffer from branch divergence.
a. True b. False c. We cannot tell.
10. We can have more than one warp executing in the same SM at the same time.
a. True b. False
