关键词 > FIT5047
FIT5047 Semester 1, 2024 Machine Learning Laboratory
发布时间:2024-05-21
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
FIT5047 Semester 1, 2024
Machine Learning Laboratory
FIT5047 – Machine Learning Laboratory (20%)
Question 1: Classification, Decision Trees, Na¨ıve Bayes, k-NN, WEKA (36 marks)
Consider the dataset postoperative-patient-data_simplified.arff available on moodle. This dataset contains health-status attributes of post-operative patients in a hospital, with the target class being whether the patients should be discharged (S) or remain in the hospital (A). Additional documentation regarding these attributes appears in the arff file.
1. Before you run the classifiers, use the weka visualization tool to analyze the data, and report briefly on the types of the different variables and on the variables that appear to be important. (4 marks)
2. Run J48 (=C4.5, Decision Tree), Na¨ıve Bayes and IBk (k-NN) to learn a model that predicts whether a patient should be discharged. Perform 10-fold cross validation, and analyze the results obtained by these algorithms as follows.
Note: Click on the “Choose” bar to select different values of the following parameters for J48 and k-NN (parameter variations of Na¨ıve Bayes are not relevant to this lab):
. J48 – minNumObj (at least two values).
. k-NN (IBk, under lazy in weka) – KNN (at least two values) and distanceWeighting (at least two options).
Explain the meanings of these parameters. You should report on performance for at least two variations in total of the operational parameter minNumObj for J48, and at least two variations of each KNN and distanceWeighting for k-NN (four variations in total for k-NN).
(a) J48 (=C4.5) (3 + 2 = 5 marks)
i. Examine weka’s output (e.g., Decision Tree), and indicate which are the main variables. ii. What is the accuracy of the output produced by weka (e.g., Decision Tree)? Why is it different from the accuracy you would expect by considering only the majority class?
Explain the results in the confusion matrix.
(b) Na¨ıve Bayes (2 + 8 + 3 = 13 marks)
i. Explain the meaning of the “probability distributions” in weka’s output, illustrating it with reference to the BP-STBL attribute.
Note: weka does smoothing when computing probabilities for Na¨ıve Bayes.
ii. Calculate (by hand), from the probability distributions in weka’s output, the probability that a person with the following attribute values would be discharged, and the probability that they would remain in hospital. Show your calculations.
L-CORE = mid
L-SURF = low
L-O2 = good
L-BP = high
SURF-STBL = stable
CORE-STBL = stable
BP-STBL = mod-stable
iii. What is the accuracy of the Na¨ıve Bayes classifier? Explain the results in the confu- sion matrix. What is the prediction of weka’s Na¨ıve Bayes classifier for the patient in item 2(b)ii, and the probability of this prediction?
(c) k-NN (6 + 2 = 8 marks)
i. Find three instances in the dataset that are similar to the patient in item 2(b)ii (you can do this visually), and use the Jaccard coefficient, combined with a distance metric, to calculate (by hand) the predicted outcome for this patient. Show your calculations.
ii. What is the accuracy of the k-NN classifier for different values of k (kNN)? Explain the results in the confusion matrix.
3. (3 + 3 = 6 marks) Draw a table to compare the performance of J48, Na¨ıve Bayes and IBk using the accuracy, recall, precision and F-score measures produced by weka. Which algorithm does better? Explain in terms of these summary measures. Can you speculate why?
Question 2: Classification, Decision Trees, Na¨ıve Bayes, k-NN, WEKA (52 marks)
Consider the dataset tic-tac-toe.arff available on moodle. Each example in this dataset rep- resents a different game of tic-tac-toe (http://en.wikipedia.org/wiki/Tic-tac-toe), where the player writing crosses (“x”) has the first move. Only those games that don’t end in a draw are included, with the positive class representing the case where the first player wins and the negative class the case where the first player loses. The features encode the status of the game at the end, so each square contains a cross “x”, a nought “o” or a blank “b” .
1. Before you run the classifiers, use the weka visualization tool to analyze the data. (2 + 2 = 4 marks)
(a) Which attributes seem to be the most predictive of winning or losing? (hint: if you were the “x” player, where would you put your first cross and why?)
(b) What can you infer about the advantage (or otherwise) of being the first player?
2. Run J48 (=C4.5, Decision Tree), Na¨ıve Bayes and IBk (=k-NN) to learn a model that predicts whether the “x” player will win. Perform 10-fold cross validation, and analyze the results obtained by these algorithms as follows.
Note: When using J48, click on the “Choose” bar to try at least two values of minNumObj (default is 2); and when using IBk, try at least three values of KNN (default is 1).
(a) J48 (=C4.5) (2 + 3 + 14 + 3 = 22 marks)
i. Examine the Decision Tree and indicate the main variables.
ii. Trace the Decision Tree for the following game. What would it predict? Does this predic- tion make sense?
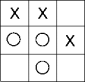
iii. What is the first split in the Decision Tree? Calculate (by hand) the Information Gain obtained from the first split in the tree. Show your calculations.
iv. What is the accuracy of the Decision Tree? Explain the results in the confusion matrix for the best option you tried.
(b) Na¨ıve Bayes (7 + 3 = 10 marks)
i. Calculate (by hand), from the probability distributions in weka’s output, the predicted probability of a win and of a loss for the game in item 2(a)ii. Show your calculations.
ii. What is the accuracy of the Na¨ıve Bayes classifier? Explain the results in the confusion matrix. What is the prediction of weka’s Na¨ıve Bayes classifier for the game in item 2(b)i, and the probability of this prediction?
(c) k-NN (6 + 2 = 8 marks)
i. Find three instances in the dataset that are similar to the game in item 2(a)ii, and use the Jaccard coefficient, combined with a distance metric, to calculate (by hand) the predicted outcome for this game. Show your calculations.
ii. What is the accuracy of the k-NN classifier? Explain the results in the confusion matrix.
3. (5 + 3 = 8 marks) Draw a table to compare the performance of J48, Na¨ıve Bayes and IBk using the accuracy, recall, precision and F-score measures produced by weka. Which algorithm does better? Explain in terms of these summary measures. Can you speculate why?
Question 3: Regression (2 + 1 + 5 + 1 + 3 = 12 marks)
Consider the dataset abs.arff available on moodle. This dataset contains continuous-valued eco- nomic attributes of a country, with the target variable being the unemployment rate. Additional documentation regarding these attributes appears in the arff file.
1. Perform a linear regression (Choose → functions → LinearRegression in weka) to learn a linear model of the unemployment rate as a function of the other variables. You can use the default parameters given in weka. What is the resultant regression function?
2. Using the resultant regression function, calculate by hand the Absolute Error for the year 1986.
3. Calculate (by hand) the Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) obtained by the regression function between the years 1986 and 2006 (to avoid “?” values). You can use the excel spreadsheet abs.xlsx provided on moodle. How is MAE different from RMSE? (do these functions emphasize different aspects of performance?)
4. Use your model to predict the Unemployment-Rate for the year 2010.
5. How would you impute missing values for the All-Ords-Index for the years 1981-1983 and for the Housing-Loan-Interest-Rate for the years 1981-1985? Justify your answer. (Answers without justifications will receive no marks)
Rerun weka to build a new regression model (using your imputed values). How does the new regression model compare to the previous one? What is the RMSE and MAE of the new model?
Submission instructions:
1. Before the lab, upload to moodle your solution to Question 1, in a zip file named MLlab- StudentID-Q1.zip, where StudentID is your Student ID number. There is a dedicated submission site for Question 1 labeled “Question 1 – BEFORE THE LAB” .
2. At the end of the lab, upload your final solution to Question 1 in a zip file named MLlab- StudentID-Q1final.zip to the site labeled “Question 1 – Final submission” . Make sure you indicate clearly any differences between your new submission and the original submis- sion. No further versions of Question 1 will be accepted.
3. On Friday, May 24, before 23:55, upload to moodle your answers to the remaining questions, in a zip file named MLlab-StudentID-Q2Q3.zip. There is a dedicated submission site for the Questions 2 and 3.
4. Multiple submissions of Question 2 and 3 are allowed until the deadline, and drafts will be deemed submitted at the deadline.
Important:
. The lab will be on campus under exam conditions. You must attend your assigned lab, and you are not allowed to communicate with your classmates during the lab.
. Only typed textual explanations will be accepted. Scanned or handwritten explanations will be automatically rejected, and will receive no marks.
. You should have completed at least Question 1 when you attend the lab, and you must be available for questions from your tutor during the lab. However, you can still modify your submission of this question until the end of the lab. Make sure you indicate clearly any differences between your new submission and the original submission.
. You may be interviewed about your work in order to determine your mark for this lab. The purpose of the interview is to ascertain that you are knowledgeable about the work you are submitting. Inability to properly explain your work will result in loss of marks.
Late submission policy:
Question 1 must be submitted before the lab; failure to do so will result in a mark of 0 for this question. 10% of the maximum mark for Questions 2 and 3 will be deducted for every calendar day their submission is late.
