关键词 > MATH3333
MATH 3333 3.0 - Winter 2022-23 Assignment 4
发布时间:2024-05-17
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
MATH 3333 3.0 - Winter 2022-23
Assignment 4
Due date: April 10, 2022
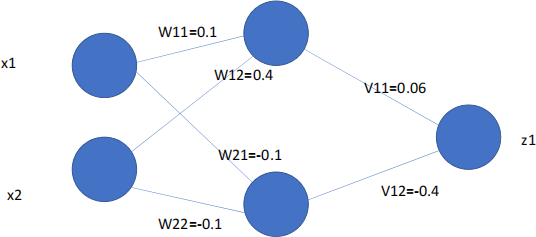
Question 1: The following igure shows a neural network with two inputs, one hidden layer with two hidden neurons and one output. (For simplicity, we omit the intercept terms here.) We initialize the parameters as follows: w11 = 0.1, w12 = 0.4, w21 = -0.1, w22 = -0.1, v11 = 0.06, v12 = -0.4. Given one observation x1 = 1, and x2 = 0, and the observed output t1 = 0, update the network parameter w11 , using the learning rate λ = 0.01.
Question 2: Principal component method can be used to summarize the data in a lower dimension. Suppose each observation in the data set Xi has two features Xi1 , and Xi2 . We wish to use the principal component method to present the data in one dimensional space. We have the following data set.
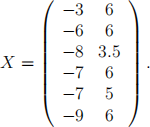
Calculate the irst principal component for the irst observation.
Question 3: ID3(S, A) is an important algorithm in the construction of decision tree. The set S denote the collection of observations. The set A denote the collection of predictors. In this question, let A = fX1 , X2 g. Let S be the following data set:
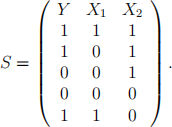
We would like to build a classiication tree for the response variable Y.
❼ What is the misclassiication error rate if we do a majority vote for Y without splitting X1 or X2 ?
❼ What is the misclassiication error rate if we split the data set based on X1 = 1 versus X1 = 0? What is themisclassiication error rate if we split the data set based on X2 = 1 versus X2 = 0?
❼ Should we split the tree based on the predictor X1 or X2 or not split the tree?
❼ Decision tree is very sensitive to the data set. If there are small changes in the data set, the resulting tree can be very diferent. Ensemble method can overcome this problem and improve the performance of the decision tree? Use two or three sentences to describe what ensemble method is and name three ensemble methods that can be used to improve decision trees.
Question 4: One of the hierarchical cluster algorithms is agglomerative (bottom up) pro- cedure. The procedure starts with n singleton clusters and form hierarchy by merging most similar clusters until all the data points are merged into one single cluster. Let the distance between two data points be the Euclidean distance 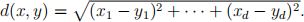 Let the distance between two clusters A and B be minx=A,y=B d(x, y), the minimum distance between the points from the two clusters. There are 5 observations a, b, c, d and e. Their Euclidean distances are given in the following matrix:
Let the distance between two clusters A and B be minx=A,y=B d(x, y), the minimum distance between the points from the two clusters. There are 5 observations a, b, c, d and e. Their Euclidean distances are given in the following matrix:
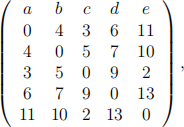
For example, based on the matrix above, the distance between a and b is 4. Please derive the four steps in the agglomerative clustering procedure to construct the hierarchical clustering for this dataset. For each step, you need to specify which two clusters are merged and why you choose these two to merge.
Question 5: Analyze the German data set from the site:
https://archive.ics.uci.edu/ml/datasets/statlog+(german+credit+data). Apply the support vector machine analysis and the random forest analysis on the dataset. Please randomly se- lect 800 observations as the training set and use your two models to predict the default status of the remaining 200 loans. Repeat this cross-validation one thousand times and calculate the average misclassiication errors of the two models.
Question 6
The idea of support vector machine (SVM) is to maximize the distance of the separating plane to the closest observation which are referred as the support vectors. Let g(x) = w0 + w1 x1 + w2 x2 = 0 be the separating line. For a given sample x = (x1 , x2 ), the distance of x to the straight line g(x) = 0, is
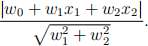
❼ Let the separating line be x1 + 2x2 - 3 = 0, and the given observation is x = (1.5, 1.5). Calculate the distance of the observation to the separating line.
❼ In the linear SVM, the dot product 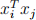 is an important operation which facilitates the calculation of the Euclidean distance. Let the nonlinear mapping of the sam- ple from the original space to the projected space be φ. In nonlinear SVM, the dot product between the images of the mapping φ(xi ) and φ(xj ) are calculated by the ker-nel function K(xi , xj ) = φ(xi )T φ(xj ). Suppose in the original space xi = (xi1, xi2) and xj = (xj1, xj2). The nonlinear mappings are
is an important operation which facilitates the calculation of the Euclidean distance. Let the nonlinear mapping of the sam- ple from the original space to the projected space be φ. In nonlinear SVM, the dot product between the images of the mapping φ(xi ) and φ(xj ) are calculated by the ker-nel function K(xi , xj ) = φ(xi )T φ(xj ). Suppose in the original space xi = (xi1, xi2) and xj = (xj1, xj2). The nonlinear mappings are 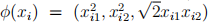 and
and 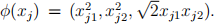 Calculate the kernel function K(xi ; xj ): If it is a poly-nomial kernel function, determine the degrees of the polynomial kernel function.
Calculate the kernel function K(xi ; xj ): If it is a poly-nomial kernel function, determine the degrees of the polynomial kernel function.
Question 7 You don’t need to submit this question on Crowdmark. This question is only for your practice.
In the following table we have the playlist of 10 Spotify users. There are 5 artists A, B, C, D and E. If the user chooses the artist, the corresponding entry will be 1, otherwise, it will be zero.
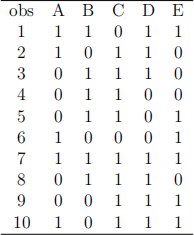
a) Suppose A is the antecedent and B is the consequent. Calculate the conidence of B and the lift of A on B. Based on the lift value, do you recommend B to the user after the user has played artist A? Why?
