关键词 > FIN7880
FIN7880 2024 Assignment 1
发布时间:2024-05-13
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
FIN7880
Assignment 1
Introduction
You will receive three movie review datasets.
• The first dataset is "movie_train_set.csv" and contains 21,000 reviews, each with a positive (1) and negative (0) sentiment label.
• Use this dataset to train and test your sentiment classification model.
• The second dataset is "movie_test_set_masked.csv" and contains 4,000 reviews.
• Use this dataset to score sentiments of movie reviews of your developed ML models.
• The third dataset is "unlabeledTrainData.tsv” and contains 50,000 unlabeled movie reviews.
• Use this dataset to build the W2V embedding model.
Sample Data

Introduction
• Develop sentiment classification models using the given training data (first dataset).
• Use your best ML classification model to score the sentiment of the 4,000 movie reviews in the evaluation dataset (second dataset).

Problem Description
Before you can train your ML classification model, the text in the movie
review column must be encoded into a numerical format. The following two
approaches are recommended for encoding the movie review.
• Bag of Words:
• Utilize CountVectorizer/TfidfVectorizer to encode the movie review in Dataset 1 and Dataset 2
• Word Embedding:
• Implement Skipgram/CBOW to create a Word2Vec model based on the content of Dataset 3.
• Utilize the Word2Vec model to encode the movie reviews in Dataset 1 and Dataset 2
Evaluation
Your evaluation will be based on the completion of the following tasks:
• Steps used to pre-process the movie reviews
• How to represent the movie reviews in a vector space model using CountVectorizer/TfidfVectorizer and W2V embedding methods
• Train/Test Preparation (e.g., 70/30 split).
• Model training and evaluation (Naïve Bayes, SVM, Logistic Regression, etc.)
• Use of hyperparameters
• Model evaluations (Confusion Matrix, Accuracy, Precision, F1 score, AUC, ROC, etc.)
• Score the sentiment of reviews in the evaluation dataset using your best-trained model.
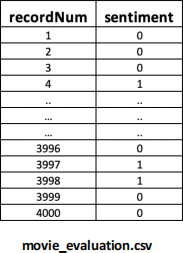
• Save the scoring results to a CSV file named 'movie_evaluation.csv ’ in a proper format.
What should you submit in the Moodle folder?
1. Python Notebook, which has the following steps:
• Prepare data, vectorize text, and train/test/evaluate models.
• Predict sentiment scores for 4,000 reviews in 'movie_test_set_masked.csv ’.
• Save scoring output as 'movie_evaluation.csv ’.
2. CSV File ('movie_evaluation.csv’) with the following format.
• Column1: 'recordNum’
• Column 2: 'sentiment' (predicted sentiment: 0/1)
3. Written Report: - Microsoft PowerPoint format.
Assessment Criteria
1. Preprocessing of the Text [30%]
• Tokenization, stopwords removal, normalization + Python Program [20%]
• Text Vectorization approaches
2. Machine Learning Model {40%]
• Train/testing preparation + Python programs [5%]
• Machine Learning Model Training/Testing + Python programs [25%]
• Machine Learning Model Evaluation Accuracy [10%]
3. Summary of processes and results in written format [30%]
• Discuss the model performance using the different text vectorization approaches
