关键词 > STAT441/841
STAT 441 / 841 Statistical Learning-Classification
发布时间:2021-11-01
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Statistical Learning-Classification
STAT 441 / 841, CM 762
Assignment 3
1. a) Write a program to fit an RBF network. In implementing RBF, you need to cluster the data and find the center and spread of each cluster. You don’t need to implement a clustering algorithm yourself. You can use any clustering al-gorithmand any clustering routine in any programming language based on your preference.For example you can use ’kmeans’ in Matlab.
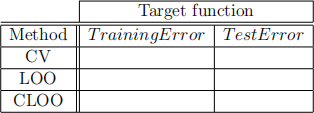
b) Use the Ionosphere dataset (Ion.mat) . Use the Vanilla cross validation (ie. use 80% of data as training set and 20% as test set), Leave one out cross validation, and Leave one out cross validation as expressed in (1) (The method explained in Question 5 shows how LOO can be performed without iteration.) and find the optimum number of basis function for each model. Compute the test error in each case and complete the following table.
In this table
CV is vanilla cross validation
LOO is leave one out cross validation
CLOO is Leave one out cross validation as expressed in (1).
2. Support Vector Machine
a) Write a function [b, b0] = HardM arg(X, y) which takes a d × n matrix X and n × 1 vector of target labels y and returns: a d × 1 vector of weights b and a scalar offset b0, corresponding to the maximum margin linear discriminant classifier.
b) Write a function [b, b0] = Sof tM arg(X, y, γ) which takes an additional scalar argument γ and returns b and b0 corresponding to the maximum soft margin linear discriminant classifier.
c) Write a function [yhat] = classify(Xtest, b, b0) which takes a d × m matrix Xtest, a d × 1 vector of weights b, and a scalar b0, and returns a m × 1 vector of classifications yhat on the test patterns.
d) For each of the datasets linear, noisylinear, and quadratic on Piazza solve for each kind of discriminant function: [bh, b0h] = HardM arg(X, y), [bs, b0s] = Sof tM arg(X, y, 0.5), produce a 2D plot of the training data and the two hypotheses corresponding to bh, b0h and bs, b0s and report the mean misclassification error (i.e., the sum of misclassification errors divided by the number of data points) that each of the two hypotheses obtained on the training data and on the test data.
Hand in a plot and two tables for each dataset.
Note 1 : Your function must be able to handle arbitrary d, n, γ, and m.
Note 2: You cannot use a builtin SVM function. You need to implement SVM yourself. In implementing SVM, you need to solve a quadratic program. You can use a built in function for solving the quadratic programming.
3. Let 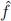 be an estimator of the quantity f, show that its mean-squared error can be decomposed as follows:
be an estimator of the quantity f, show that its mean-squared error can be decomposed as follows:
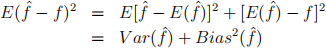
4. Given a set of data points {xi}, we can define the convex hull to be the set of all points x given by
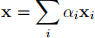
where αi ≥ 0 and 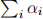 = 1. Consider a second set of points {yi} together with their corresponding convex hull. By definition, the two sets of points will be linearly separable if there exist a vector
= 1. Consider a second set of points {yi} together with their corresponding convex hull. By definition, the two sets of points will be linearly separable if there exist a vector 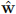 and a scaler w0 such that
and a scaler w0 such that 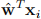 + w0 > 0 for all xi, and + w0 < 0 for all yi.
+ w0 > 0 for all xi, and + w0 < 0 for all yi.
Show that if their convex hulls intersect, the two sets of points cannot be linearly separable.
5. Leave-one-out cross validation. Consider the model yi = f(xi) +  i. When f(xi) = β0 +
i. When f(xi) = β0 + 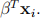 The parameters of this model can be found by ordinary least square (OLS). Let H be the hat matrix associated with OLS(we solved similar model and had the concept of hat matrix in RBF network). Show that
The parameters of this model can be found by ordinary least square (OLS). Let H be the hat matrix associated with OLS(we solved similar model and had the concept of hat matrix in RBF network). Show that
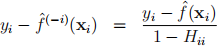
where Hii denote the i-th diagonal element of H; and 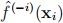 denotes estimating
denotes estimating 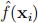 using an
using an 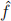 that is obtained without using the i-th observation. Thus show that the leave-one-out cross validation can be computed without iteration.
that is obtained without using the i-th observation. Thus show that the leave-one-out cross validation can be computed without iteration.
