关键词 > CIS4190/5190
CIS 4190/5190 Final Exam
发布时间:2023-12-15
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CIS 4190/5190 Final Exam
Version A
December 22, 2022
Instructions
. Write your answers on paper with a pen. Write your name, section number (4190 or 5190), and exam version (shown above) prominently on the first page of your answers at the top left.
. No devices or cheat sheet(s) are allowed.
. The exam contains 11 questions, with 80 points total. Questions 1-7 are short answer, and 8-11 are more involved.
. Each point should take approximately 1-2 minutes; if you find yourself spending too much time on one problem, move on and come back to it.
. At the end of 2 hours, you will put down your pens and submit your exam.
Good luck!
1. (12 pts) Consider the following 2D binary classification datasets:
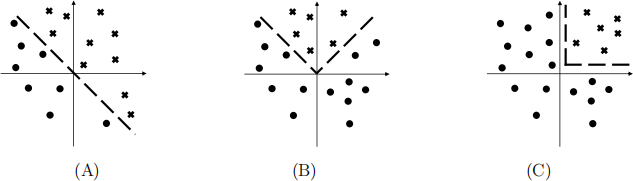
For each of the following model families, indicate which of the above datasets can be perfectly classified by some model in the model family.
(a) (3 pts) Logistic regression
(b) (3 pts) Logistic regression over features ϕ(x) =l1 x1 |x1 | x2]⊤
(c) (3 pts) A decision tree with axis aligned splits—i.e., xi ≤ t, where i ∈ {1, 2} is a feature index and t ∈ R is a real-valued threshold.
(d) (3 pts) Decision tree has oblique splits—i.e., a1 x1 + a2 x2 ≤ t, for some a1 , a2 , t ∈ R.
2. (4 pts) Consider the following 2D datasets:
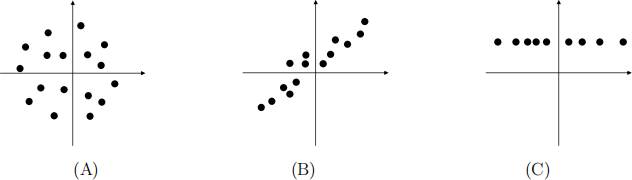
Note that in (C), the points lie on aline. Suppose we run PCA, take only the top principal component, and use it to compress the data.
(a) (1 pt) Which dataset will have the highest reconstruction error?
(b) (1 pts) Which dataset will have the lowest reconstruction error?
(c) (2 pts) For your answer to part (b), what is its reconstruction error?
3. (4 pts) Suppose we use k-means clustering for binary classification as follows. Given a labeled dataset {(①i , gi ![]() to compute centroids ① (1) ,...,① (k) e Rd. Then, for each cluster j e {1,..., k}, we compute the fraction of training examples with positive labels in that cluster:
to compute centroids ① (1) ,...,① (k) e Rd. Then, for each cluster j e {1,..., k}, we compute the fraction of training examples with positive labels in that cluster:
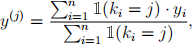
where ki = arg minj∈{1,...,k} I①i — ① (j) I2(2) is the cluster assigned to ①i.
(a) (1 pt) If k = 1, what does the resulting model family look like? (In other words, what functions are possible across all possible datasets?)
(b) (1 pt) If k 一 钝, what does the resulting model family look like? (c) (2 pt) Does increasing k increase, decrease, or not affect variance?
4. (8 pts) Let φ1 and φ2 be two feature maps over inputs ① e Rd , and consider the linear regression models β1(⊤)φ 1 (①) and β2(⊤)φ2 (①) corresponding to φ1 and φ2 , respectively. For each of the following, can the variance of β1(⊤)φ 1 (①) be higher than, lower than, or either higher than or lower than that of β2(⊤)φ2 (①)? Indicate all possibilities. Unless otherwise specified, assume no regularization.
(a) (1 pt) φ1 has strictly more features than φ2 . [Hint: What if the features in φ1 are all the same?]
(b) (1 pt) The features in φ1 are a strict superset of those in φ2 (e.g., φ2 consists of quadratic features, and φ1 consists of quadratic features and some others).
(c) (1 pt) φ1 and φ2 contain exactly the same features, and we use L2 regularization for β1(⊤)φ 1 (①) but not for β2(⊤)φ2 (①).
(d) (1 pt) The features in φ1 are a strict superset of those in φ2 , and we use L2 regular- ization for β1(⊤)φ 1 (①) but not for β2(⊤)φ2 (①).
(e) (2 pts) We construct φ1 (①) by using principal components analysis on the training inputs {①i ![]() φ2 similarly, but take the top k′ components, where k′ < k.
φ2 similarly, but take the top k′ components, where k′ < k.
(f) (2 pts) We take φ1 (①) to be a bag of words model (i.e., each feature is an indicator (φ1 (①))i = ✶(山i e ①) of whether word 山i is in sentence ①), and take φ2 (①) to be bigram model (i.e., each feature is an indicator (φ2 (①))i = ✶(山i山i(′) e ①) of whether words 山i and 山i(′) occur sequentially in sentence ①).
5. (4 pts) Suppose we use AdaBoost to train an ensemble of logistic regression models over a feature map φ. For each of the following hyperparameters, indicate whether increasing it tends to increase or decrease variance (you should give exactly one answer for each part).
(a) (1 pt) The number of T iterations of AdaBoost (equivalently, the number of base models in the final ensemble)
(b) (1 pt) Assuming we use L2 regularization, the magnitude of λ (recall that the regu- larization term is λ · ∥β∥2(2), where β are the logistic regression parameters)
(c) (1 pt) The number of training examples n (i.e., the training dataset is {(xi , yi ![]() (d) (1 pt) The number of features d (i.e., each feature vector is ϕ(x) ∈ Rd )
(d) (1 pt) The number of features d (i.e., each feature vector is ϕ(x) ∈ Rd )
6. (4 pts) For which of the following algorithms is optimization perfect—i.e., the standard optimizer is guaranteed to find the model that globally minimizes the loss function?
(a) (1 pt) Logistic regression, if the loss is the NLL (a.k.a. cross-entropy loss) (b) (1 pt) Logistic regression, if the loss is the accuracy
(c) (1 pt) Neural network with one hidden layer, if the loss is the NLL
(d) (1 pt) k-means clustering, if the loss is the squared distance to the centroid repre- senting each point, averaged over points
7. (4 pts) Consider a logistic regression model, which has likelihood function
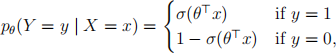
where σ(z) = ![]() is the sigmoid function. Suppose we have already fit the parameters θ , and we want torescale the predicted probabilities. One strategy for doing so is temperature scaling, where we introduce an additional real-valued parameter β ∈ R, and consider
is the sigmoid function. Suppose we have already fit the parameters θ , and we want torescale the predicted probabilities. One strategy for doing so is temperature scaling, where we introduce an additional real-valued parameter β ∈ R, and consider
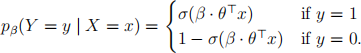
(a) (2 pts) What happens to the classification boundary if we take β → 0 (i.e., very small but not quite zero)? What happens to the predicted probabilities (i.e., what values can they take)?
(b) (2 pts) What happens to the classification boundary if we take β → ∞? What happens to the predicted probabilities?
8. (10 pts) Consider a neural network with one hidden layer:
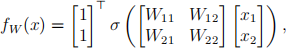
where σ(z) is some nonlinear function.
(a) (4 pts) What is the gradient ∇W fW (x)? In particular, compute each partial deriva- tive ![]() fW (x); then, the gradient is
fW (x); then, the gradient is
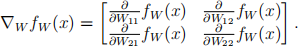
You can leave your answer in terms of σ(z) and σ′ (z) = ![]() σ(z).
σ(z).
(b) (2 pts) What is the gradient ΔW L(W;x,y) of the loss L(W;x,y) = (fW (x) — y)2 ? You do not need to expand fW (x) (but you should expand ΔW fW (x)).
(c) (2 pts) Suppose the parameters satisfy W11 = W21 and W12 = W22. After one step gradient descent (with learning rate η), do theseequalities still hold? In other words, recalling that the gradient descent update rule is
W′ — W — η · ΔW L(W;x,y),
where η e R>0 is the learning rate, show that W1(′)1 = W2(′)1 and W1(′)2 = W2(′)2 .
(d) (2 pts) Based on your answer, briefly explain why initializing the weight matrix to
zero (i.e., W11 = W12 = W21 = W22 = 0) is a bad idea.
9. (10 pts) Consider two binary random variables X1 , X2 .
(a) (3 pts) There are three possible Bayesian networks over these two random variables; draw all three of them.
(b) (3 pt) For each possible Bayesian network, indicate whether it can represent joint distributions of the form p(X1 = x1 , X2 = x2 ) = p(X1 = x1 )p(X2 = x2 ).
(c) (3 pt) For each possible Bayesian network, indicate whether it can represent an arbitrary joint distribution p(X1 = x1 , X2 = x2 ).
(d) (1 pt) We say two Bayesian networks are equivalent if they can represent exactly the same class (a.k.a. subset) of possible joint distributions. Indicate which pairs of Bayesian networks you drew are equivalent.
10. (10 pts) In class, we learned that recurrent neural networks (RNNs) can be viewed as reusing the same parameter across layers. In this problem, we will examine the gradients of RNNs via a toy example.
(a) (4 pts) Consider a neural network y = fθ (x), where x e R, y e R, and θ e R2 , where
fθ (x) = θ2 σ(θ1 x),
for some nonlinear function σ(z). What is the gradient Δθ fθ ![]() fθ (x)
fθ (x) ![]() fθ (x)]⊤ ? You can leave your answer in terms of σ and σ′ , where σ′ (z) =
fθ (x)]⊤ ? You can leave your answer in terms of σ and σ′ , where σ′ (z) = ![]() (z).
(z).
(b) (4 pts) Consider a neural network y = hβ (x), where x e R, y e R, and β e R, where
hβ (x) = βσ(βx),
with σ is as before. What is the gradient Δβ hβ (x) = ![]() hβ (x)?
hβ (x)?
(c) (2 pts) Note that letting θ =lβ β]⊤ , then we have hβ (x) = fθ (x). Using this fact, express the gradient Δβ hβ (x) in terms of Δθ fθ (x). [Hint: Use the chain rule to compute ![]() f[β β]⊤ (x).] Check to make sure your answer is consistent with the previous parts!
f[β β]⊤ (x).] Check to make sure your answer is consistent with the previous parts!
11. (10 pts) Consider the following Markov decision process with states S = {s1 , s2 ,..., sn } and actions
A = {a1 = move left, a2 = move right}.
The transitions are deterministic: Suppose the agent is currently in state si. Then, taking action a1 transitions the agent to state si−1 (unless i = 1, in which case it stays in s1 ), and taking a2 transitions it to si+1 (unless i = n, in which case it stays in sn ). Finally, the rewards are
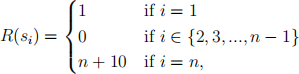
the discount factor is γ = 1, the time horizon is T = n, and the initial state is s1. Suppose we are running a reinforcement learning algorithm, and it knows all the MDP transitions, as well as the rewards for all states except sn.
(a) (2 pts) Write down the optimal policy—i.e., the action π* (si ) ∈ A to take for each i. What is its cumulative expected reward?
(b) (2 pts) Suppose we act randomly in this MDP—i.e., choose action a ∼ Uniform({a1 , a2 }) i.i.d. on each step. What is the probability of reaching state sn (from initial state
s1 ) in a single rollout within the time horizon?
(c) (2 pts) Suppose that our current estimate the reward of sn to be R(sn ) = 0. Write down the optimal policy ˆ(π)(si ) ∈ A for each i for this estimate.
(d) (2 pts) Recall that an ϵ-greedy policy acts randomly with probability ϵ and optimally based on the current estimate (given in part (c)) with probability 1−ϵ . What is the probability that an ϵ-greedy policy based on ˆ(π) reaches sn (from initial state s1 ) in a single rollout within the time horizon?
(e) (2 pts) Based on your above answers, briefly explain why random exploration (in- cluding ϵ-greedy) will perform poorly for learning the unknown reward R(sn ).
