关键词 > CS342
CS342: Machine Learning
发布时间:2023-11-28
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Latent Factor Models with Kernels
CS342: Machine Learning
November 2023
I. INTRODUCTION
In the lectures, we showed that mapping data into a new feature representation can help to perform classification and clustering tasks more accurately. We also showed that in many cases, such a change of basis may result in very high-dimensional feature vectors, which can be difficult to store and process with limited computing and memory resources. To solve this issue, we introduced the kernel trick. Specifically, to map a dataset X 2 Rn 根d into a new feature space using the mapping function φ( ·), we can use the kernel trick to compute matrix K = φ(X)φ(X)T = ZZT without explicitly computing Z = φ(X).
In the lectures, we also explained how PCA can be used to find the principal components (PCs) of a dataset to represent the data in a low dimensional space, which can facilitate classification and clustering tasks. In this coursework, we will use the kernel trick and PCA to attempt to classify all data points of a 2-class dataset by using a single decision stump. We will focus on two types of kernels:
1) Homogeneous Polynomial: (xi , xj ) = (〈xi , xj))d , where d > 0 is the polynomial degree.
2) Radial Basis Function (Gaussian): (xi , xj ) = exp ( — jj xi — xj jj 2 ,, where = ![]()
Gaussian function centered at xj .
A. Preliminaries
In PCA, given a dataset X 2 Rn 根d with n data points of d dimensions, we are interested in finding matrices Z 2 Rn 根k and W 2 Rk 根d that can be used to reconstruct X 2 Rn 根d as accurately as possible. Matrix W 2 Rk 根d contains the k = d PCs of the dataset X, where the PCs are organized as the rows of W and each PC has d dimensions. In the lectures, we covered
X = UΣVT , ( 1)
where V contains the eigenvectors of XTX. Hence, VT = W. We can then compute the cth PC using the elements in U and Σ as follows:
wc = σ![]() 1XTuc , (2)
1XTuc , (2)
where σc is the cth singular value and uc is the cth column of U.
II. METHODS
A. Dataset
The dataset for this coursework is the Circles Dataset, which is available on the CS342 webpage. The dataset contains only two classes and 500 samples. It is a synthetic dataset widely used in ML to design and test models. Each sample is represented by a 2d feature vector. The first two columns of the Citcles.data file represent the two features, while the third column is the class,i.e., class 1 or class 2. Figure 1 depicts all samples of this dataset.
B. Making the dataset linearly separable
We want to determine if our data is linearly separable after mapping it to a new feature representation using a mapping function φ( ·) and projecting the new feature representation onto its top PCs. In other words, we want to first perform a change of basis and then use PCA on the new data points to determine if they can be linearly separable. To confirm if the dataset can be made linearly separable, we will use a single decision stump. The steps of this process are listed next:
1) Map the data to a new feature representation.
2) Perform PCA on the new feature representation.
3) Project the new feature representation onto the minimum number of top PCs needed to classify all data points correctly using a single decision stump.
Because mapping of our data to a new feature representation may result in very high-dimensional feature vectors, we want to use the kernel trick to avoid having to explicitly compute Z = φ(X), where Z is the new feature representation. We also want to use the kernel trick to avoid having to explicitly use the PCs of Z = φ(X) to project the new data points onto a number of their top PCs. In other words, we want to project Z = φ(X) onto its top PCs without having to explicitly compute Z or explicitly use the PCs. The tasks to complete for this coursework are listed next:
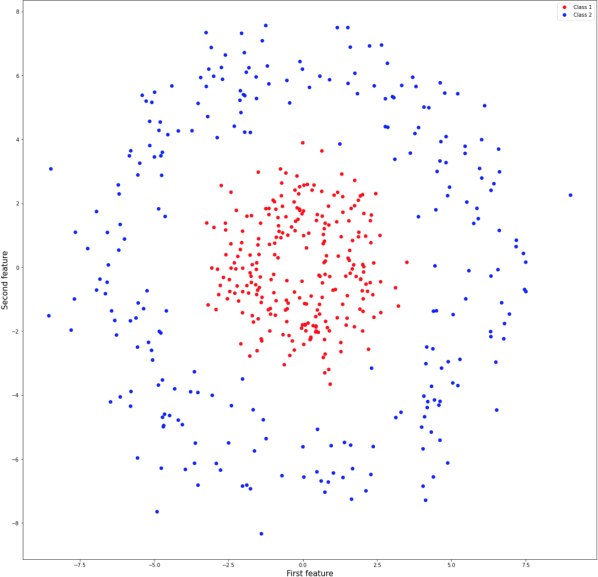
Fig. 1: The Circles Dataset with two clases.
1) Show mathematically how we can apply PCA on Z = φ(X) without explicitly computing Z. Also show mathematically how to project the data points in Z = φ(X) onto any number of its top PCs without explicitly using the PCs, i.e., without explicitly using matrix VT = W or any of its elements. Your answer should include:
a) All equations to prove these two aspects mathematically.
b) The names of all variables used in your equations.
To complete this Task, recall how SVD works and the relation between the PCs and U and Σ (see Eq. 2).
2) Based on the answer to Task 1, choose the kernel (Homogeneous Polynomial or Gaussian) and the corresponding hyper- parameters that can be used in conjunction with PCA to make the data linearly separable after projecting it onto the top PCs. To select the most appropriate kernel and its hyper-parameters, you should answer the following questions:
a) What kind of projection can be achieved with the Homogeneous Polynomial kernel and with the Gaussian kernel? b) How can one relate the kernel width (σ) to the data available?
c) What is the influence of the degree (d) of a Homogeneous Polynomial kernel?
These questions should also be used to guide your justifications to your kernel selection. Note that PCA requires data to be centered. Hence, you will need to center the data Z = φ(X). There are two ways to center the data Z = φ(X):
. ![]() (xi ) = φ(xi ) -
(xi ) = φ(xi ) - ![]() d-ata points in the dataset.
d-ata points in the dataset.
. Kij = (xi , xj ) - ![]() the centered kernel matrix K and n is the total number of data points in the dataset.
the centered kernel matrix K and n is the total number of data points in the dataset.
When centerieng Z = φ(X), keep in mind the objectives of Task 1.
3) Determine the minimum number of top PCs of Z = φ(X) that are needed to classify all data points in Z = φ(X) correctly using a single decision stump.
4) Provide the splitting rule of the decision stump fitted and justify the metric used to fit the stump.
5) If the answer to Task 3 is up to 3, plot the projected data points in Z = φ(X) clearly labelling the axes of your plot to indicate the top PCs plotted.
III. DELIVERABLES
Submit on Tabula your code as a single Jupyter file and all the requested discussions as a PDF. Please make sure that the submitted code works correctly, is well-organized, and has the necessary comments to understand it. The breakdown of marks is as follows:
. Task 1:
– Mathematical proof of how to apply PCA on Z = φ(X) without explicitly computing Z. 15 marks.
– Mathematical proof of how to project the data points in Z = φ(X) by using any number of top PCs without explicitly using the PCs, i.e., without explicitly using matrix VT = W or any of its elements. 25 marks.
. Task 2:
– Kernel selection and corresponding hyper-parameters. Please make sure to answer the questions listed in this task to justify your selection. Note that you may use validation to select hyper-parameters, however, make sure that the selected hyper-parameters are the most appropriate for the whole dataset. 15 marks (5 marks per question).
– Correct implementation of PCA with the selected kernel. 15 marks
. Task 3: minimum number of top PCs of the new data that are needed to classify all data points correctly using a single decision stump. 10 marks
. Task 4: Decision stump implemented correctly with classification results and justification of metric used to fit the stump.
5 marks
. Task 5: Explanations if the data can be plotted in 1D, 2D or 3D (5 marks) and the correct plot (5 marks). If the data can be made linearly separable data by using 4 or more dimensions, then simply explain that in your answer.
A total of 5 marks are available for the organization and explanation of your code (in the form of comments added to the code) and for the organization and presentation of your discussions in the PDF. The Jupyter notebook should be clearly and logically structured, any discussions should be well-written and adequately proofread before submission.
Note that only full marks can be awarded to Tasks 2-5 if the answers to Task 1 are correct. If the implementation of any code is correct from a programming point of view, but the code implements wrong answers, or the discussions are based on wrong answers, then only up to 50% of the total marks can be awarded to any Task that depends on the answers to Task 1.
The standard department late penalties and plagiarism policies are in effect. Note that there are several ready-to-use imple- mentations of kernel-based latent factor models, including PCA in Python. You must implement your own solutions and must not use these libraries. Your code from Lab 5 may be used as a starting point to complete this coursework. See Appendix A for more details.
A. READY-TO-USE IMPLEMENTATIONS TO SOLVE THE COURSEWORK
Libraries that implement basic operations may be used for the coursework, for example:
. mean, variance, centre data
. plot matrices, data points
. matrix and vector multiplications, additions, inverse, transpose
. implementation of argmax and argmin
. computation of Euclidean distance
. SVD - singular value decomposition
Libraries that implement the main solutions must not be used for the coursework:
. the linear version of PCA,
. the non-linear version of PCA, a.k.a. Kernel-PCA
If you are not sure whether to use a ready-to-use implementation, please email the module organizer to double-check.
