关键词 > COMP4702/COMP7703
COMP4702/COMP7703 Semester One Examinations, 2023
发布时间:2023-06-07
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Semester One Examinations, 2023
COMP4702/COMP7703
THIS IS A SAMPLE EXAM FOR PRACTICE ONLY.
Part A - Multiple choice questions (2 marks each). Record your answers on the bubble sheet provided.
Question 1.
Which of the following is NOT a supervised learning model?
(a) Gaussian Processes.
(b) Stochastic Gradient Descent.
(c) Random Forests.
(d) K-nearest neighbours.
Question 2.
What is the purpose of the activation function in a neural network?
(a) To initialize the weights.
(b) To introduce L2 regularisation into the model.
(c) To increase the speed of convergence of the learning.
(d) To calculate the output of a neuron as a function of it’s weighted inputs.
Question 3.
A classification model incorrectly predicted 20 out of 100 positive samples and 10 out of 100 negative samples. What is the accuracy of the model?
(a) 0.85.
(b) 0.88.
(c) 0.95.
(d) 0.9.
Question 4.
In logistic regression, the sigmoid function is given by f(z) = (1+e(1) −义 ) . What is the value of f(0)?
(a) 1.0.
(b) 0.766.
(c) 0.5.
(d) 0.333.
Question 5.
When comparing k-means clustering with a Gaussian Mixture Model trained using the EM algorithm (GMM), which of the following statements is true?
(a) k-means clustering is a probabilistic model, while GMM is a deterministic model.
(b) k-means clustering can handle categorical data, while GMM is limited to numerical data.
(c) k-means clustering assumes equal-sized and spherical clusters, while GMM allows for different cluster shapes and sizes.
(d) k-means clustering is an unsupervised learning algorithm, while GMM is a supervised learning algorithm.
Question 6.
Regarding auto-encoders, which of the following statements is incorrect?
(a) Local minima can be a problem in the training of Auto-encoders.
(b) Auto-encoders can be used to perform dimensionality reduction.
(c) Auto-encoders can be used as a generative model.
(d) Auto-encoders are trained in an unsupervised manner, even when labelled data is available.
Question 7.
The main difference between (standard) linear regression and Bayesian linear regression is that:
(a) Linear regression assumes a Dirichlet prior distribution for the model parameters, θ, while Bayesian
linear regression allows for arbitrary priors.
(b) Linear regression calculates a prediction, yˆ for a test input x⋆ , while Bayesian linear regression calculates a posterior predictive distribution, p(y⋆ |y).
(c) Linear regression requires the data to be scaled to have a mean of 0 and a standard deviation of 1, while Bayesian linear regression requires the data to lie strictly in the range [−1, 1].
(d) As the dimensionality of the input data increases, the computational requirements of Bayesian linear regression grow exponentially compared to quadratically for standard linear regression.
Question 8.
Consider training a linear regression model by solving the following optimisation problem:
![]() θˆ = arg min 1 ||Xθ − y||2(2) + λ||θ||2(2)
θˆ = arg min 1 ||Xθ − y||2(2) + λ||θ||2(2)
The regularisation hyperparameter is:
(a) θ .
(b) ![]() .
.
(c) λ .
(d) y.
Question 9.
The two key ideas that are leveraged in convolutional layers in a neural network are:
(a) Parameter sharing and sparse interactions.
(b) Parameter sharing and stochastic updates.
(c) Full connectivity and sparse interactions.
(d) Full connectivity and stochastic updates.
Question 10.
Regarding ensemble methods, which of the following statements is correct?
(a) Ensemble methods use bootstrapped sampling of the training data.
(b) All of the base learners in an ensemble must have an equal number of parameters.
(c) Ensemble methods cannot be used with multi-layer perceptrons as the base learner.
(d) Ensemble methods can only be trained while classical music is played in the background.
Part B - Questions carry the number of marks indicated. Write your answers in the space provided after each part of each question.
Question 1.
Figure 1 (Fig.2.1 in the textbook) shows a scatterplot of data:
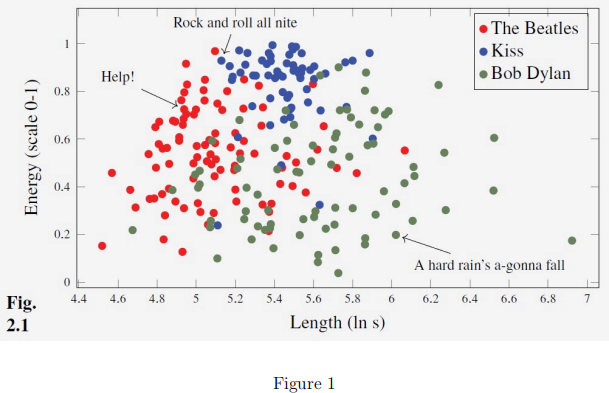
Considering this data as a training set, explain why it is often not possible to train a classifier to obtain 100% (estimated) generalisation performance for a given application. Your answer should mention the issue of estimating the generalisation performance and any assumptions about data used for training and data not used for training. (5 marks)
Question 2.
In the textbook by Chris Bishop, the following Figure is presented:
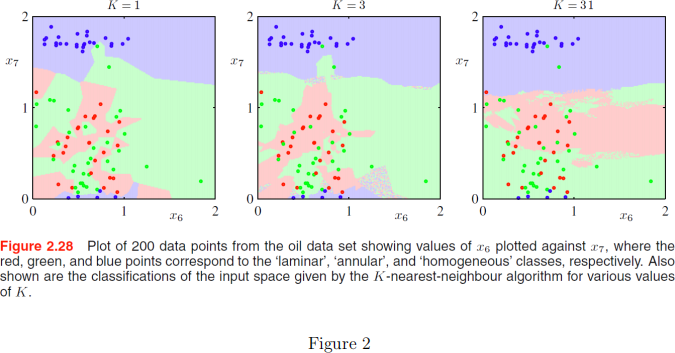
(a) Considering the plot for K=1, choose a pair of data points of different colours and explain specif-
ically how the technique calculates a prediction as we move along the line connecting the two points. (3 marks)
(b) Explain the overall shapes of the decision boundaries in the plot for K=1 in terms of how kNN classification works. (3 marks)
(c) Describe how the shape of the decision boundaries changes as K increases from 1, to 3, to 31. (2 marks)
(d) There are two green data points located towards the top of the plots. Referring to these points, explain how the K-nearest-neighbour algorithm can be said to be robust to noise for large values of K. (3 marks)
Question 3.
Figure 3 shows pseudocode for a generative adversarial network:

(a) What does L() represent in the pseudocode? (2 marks)
(b) How do we generate a sample (i.e. a data point) from the model (i.e. what calculations are performed in the Sample part of the pseudocode)? (3 marks)
(c) A machine learning researcher suggests to you that you could modify the algorithm to introduce separate learning rates, γc and γg to update the critic and generator respectively. Discuss any possible advantages or disadvantages that you see with making this change. (5 marks)
Question 4.
In the course textbook, the following Figure is presented:
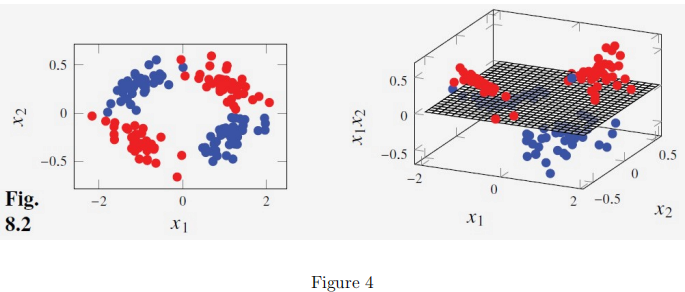
Explain how this Figure illustrates that it can be useful to transform the input data for a classification problem to a higher-dimensional feature space. (5 marks)
Question 5.
(a) For a supervised machine learning model, explain why the error on the training set Etrain is not a
good estimate of the error of the model on new (unseen) data, Enew . (3 marks)
(b) The generalisation gap is defined as ![]() new −
new − ![]() train , where
train , where
![]() new = ET [Enew (T)]
new = ET [Enew (T)]
and
![]() train = ET [Etrain (T)]
train = ET [Etrain (T)]
for a specific training set, T. Explain what we would need to do to estimate the generalisation
gap in practice (assuming a reasonably large pool of data is available). (3 marks)
(c) Explain why the method in (b) is a good idea. (3 marks)
Question 6.
(a) Given the following matrices:
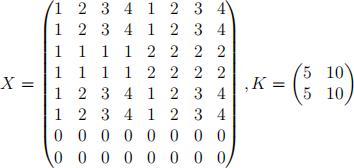
where X is the 8 × 8 input data (e.g. pixel values) and K is a 2 × 2 kernel, perform a convolution operation on X using K (stride of 2).
(Note: only show your working for one kernel position and the complete result). (3 marks)
(b) Perform 4 × 4 max. pooling on matrix X (stride of 4). (2 marks)
Question 7.
Give a short explanation for how the k-means clustering algorithm works. You can use notation, pseudocode or draw a diagram to assist in your explanation. (5 marks)
