Project 2 Machine Learning Algorithm Implementation
This project may be done in groups of 3 with members in any section.
Digital Democracy Project
The Digital Democracy project is a Cal Poly built 3-year long research project where a prototype system was built that allowed all state-level legislative proceedings to be available in text transcriptions, and be searchable, alertable and clippable. It began in California and expanded to Florida, New York and Texas. It is the first and only time in US where all legislative speeches in state legislatures are transcribed.
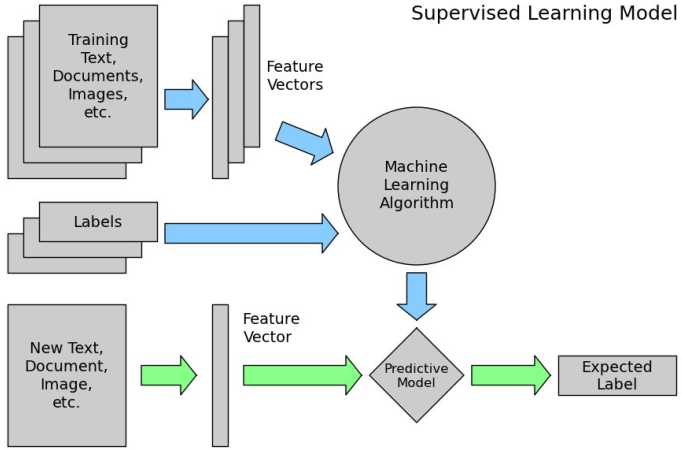
For this class, we are using just a fraction of the enormous volume of data produced by the project to do supervised and unsupervised machine learning exercises. We will use text of the speeches and try to use clustering to find interesting things about them, and also use supervised learning to predict labels about them (mainly committee where they were spoken).
Content data
The data is available on Frank.ored.calpoly.edu in the following directory: /lib/466/DigitalDemocracy You will find three files:
● committee_utterances.tsv is the main data file, its content is described below
● DDDataSet_3.tsv is additional data that can be used for speaker attribution
● readme.txt contains a guide to all the fields for both of the above files
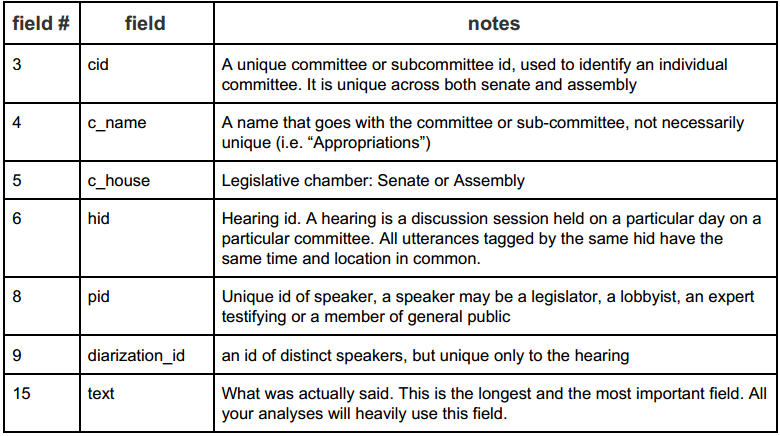
There are many fields, but only a few are necessary to know.
Part I: Clustering
1. Use K-means to do clustering on the data on just the text field (15).
1.1. Write a program called clusterDD that must run on Frank. It must take in a command line input file (can be committee_utterances.tsv or a subset of it) and have no other access to the data. You must anticipate all of committee_utterances.tsv or a small subset perhaps missing some committees entirely. Do not make any assumptions. Language is up to you. You may use as many files and organization as you want. This program will return a list of cluster id’s (0,1,2…) and number of items in each.
1.2. You must write your own version of k-means algorithm without any external packages.
1.3. You must have a function called getFeatures(one-record) where a single text field is passed in and a vector of features (to be defined by you) are returned. You must write this from scratch, no other feature-extracting functions or routines are allowed. You must use this one function for all feature-extraction purposes. Feature extraction is about topic of discussion. We want to discover the topics, from the text, and see if they correspond to committees
1.4. Compare and report on how close your clustering algorithm works in comparison to one by SciKitLearn package given the same parameters and the same features derived by getFeatures().
1.5. Compare and report on how well your clustering output matches the pre-defined committees. For each cluster, explain how it matches up with one or more committees. Are there clusters that are unexpected (i.e. have nothing to do with committees?) If so, explain why they are so.
Part II: Decision Trees
2. Use a Decision Tree algorithm to classify the text fields or hearings by committee.
2.1. Write a program called decisiontreeDD that must run on Frank.
2.1.1. It must take in a command line input file (can be committee_utterances.tsv or a subset of it) and have no other access to the data.
2.1.2. It must also take a flag “-h” where if specified, the input items are entire hearings (all text fields from the same hearing), rather than a single utterance record. You must make sure to have at least two hearings from the same committee and place on in training, the other in text for this to work.
2.1.3. You must anticipate all of committee_utterances.tsv or a small subset perhaps missing some committees entirely. Do not make any assumptions. Language is up to you. You may use as many files and organization as you want.
2.1.4. This program will print some meta data about the experiment (number of labels, an overall number of input records broken down by training and test, labels (committees)), an overall accuracy, and a per committee performance listing of (accuracy, precision, recall, F1 score).
2.2. You must write your own decision tree algorithm
2.3. You must have a getFeatures() function just like before in clustering, or you may use the same one.
2.4. Discuss your results in a report.
Part III: Speaker Attribution
3. Use a supervised machine learning experiment to predict the name of the speaker given their text. You may define a value N > 50 where only the N speakers with the most number of words are classified. You may use any algorithm or package. Write a report on your findings.Deliverables
● README file with every team member’s names, and an explanation and test output of your programs and showing your accuracy, precision, recall and F1 score for parts II and III.、● All your software and related files. No input files.
● A PDF document called "report.pdf" containing every team member's name and containing 3 sections with full explanations of the above requirements.
● everything compressed in project2.tgz submitted via Polylearn. (use tar -czvf)
2019-05-08