CSC 466 Knowledge Discovery from Data | Prof. Foaad Khosmood
Snakes on a Train
Nope, not a sequel to the much hyped film of a similar name, but this independent cheapo rip-off sure as hell took advantage of its publicity. It's quite a dull film really with a bit of gore now and then, but it didn't have the budget to pull off the film effectively. An admirable but average effort. (from Rotten Tomatoes)

Objective
● Get familiar with the Natural Language Tool Kit (NLTK 3.0)● To use different libraries to do Machine Learning
● Use NLTK’s Naive Bayes classifier to determine the language of a word.
Partnerships
● None. This lab is individual work only
NLTK
The Natural Language Tool Kit (NLTK) is a set of Python libraries, routines, and corpora for Natural LanguageProcessing. It has great content through a unified Python-based interface and allows some very powerful work to be done with very little code. It is very large and complex. There’s a whole O’Reilly book written about it (freely available here ). The book is excellent, easy to read and assumes no knowledge of Python. While we won’t be using any of the deeper computational linguistic routines that it offers, the pre-processing and machine learning interfaces are very useful to us.
Installing NLTK
NLTK python package can be installed from the website . There is a larger (I think about 400MB) portion that has many corpora and lexical resources bundled into it. Many of these are famou benchmarked data used by linguists and computational data analysts. That part of the package is not normally installed until the “nltk.download()” routine is run. The menu driven system allows you to select and install all the corpora or just the ones desired. NLTK and all the corpora are already installed on Frank .It’s not a bad idea to install the package on your own machine too, if you have the dependencies. For one thing, the GUI interface for it would be accessible. For the purposes of this class, however, everything you need is on Frank, and GUI is not necessary.
Exercise A: Explore NLTK’s corpora
NLTK has a large number of great natural language corpora, and it’s own method of obtaining important information from them. Not only is there great variety, but these are actually gold standards. For example, many of them are already word tokenized and sentence tokenized, or placed in different categories (labeled) by actual experts.Read Chapter 2-2.1 of the NLTK book. As you read, run the code in blue boxes, and experiment with the corpus you are examining. There’s no need to do any of the graphs and plots as most of you will be logged into Frank using ssh and will not have a GUI.
Make sure you understand how to get corpus fileids, words, sentences, and other pre-made resources NLTK offers for some of the corpora.
Exercise B: Text pre-processing and frequency distributions
NLTK has a great frequency distribution support. Follow these directions for a demonstration:1. Start a new python script. Name the file labB.py . Get all the non-punctuation words from Jane Austen’s Emma (in the Gutenberg corpus).
import sys, os, random, nltk
from nltk.corpus import gutenberg
from nltk.corpus import stopwords
emma = gutenberg.words('austen-emma.txt')
2. Make them all lower case, and remove the English stop words (very common words like “to”, “a” and “I”) from the list.
emmaWords = [e.lower() for e in emma if e[0] not in "-!?;:\"\'.," and
e.lower() not in stopwords.words('english')]
3. Obtain the frequency distribution of the remaining words using nltk.FreqDist(). How many distinct tokens are there? What is the most frequent word?
fdist = nltk.FreqDist(emmaWords)
print("Total number of samples: ",fdist.N(),"Most frequent
word:",fdist.max())
Experiment with other methods of the FreqDist() class (Table 1.2 of NLTK book).
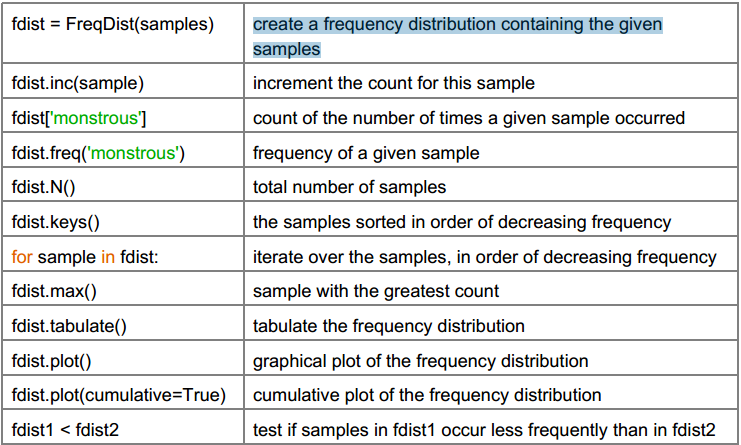
4. Find out what the total number of occurrences of the word “time” is in the corpus. Find also the frequency.
print("The number of 'time' words in sample: ",fdist['time'],
"Frequency: ",fdist.freq('time'))
Exercise C: NLTK’s built-in Naive Bayes classifier
For this exercise, we would like to use NLTK’s NB classification system to identify real English words and not fake ones. The “documents” in this exercise are words. The labels are True (for real word) or False. This classifier works best with binary features.
[Note: the provided code snippets below should help you do this exercise, but you are responsible for putting them together in one functioning Python script called labC.py and turning it in.]
1. Use the emmaWords list from Exercise B to form (document, label) tuples for all the words we have from Emma. The label should be “True”.
labeled = [(e,True) for e in emmaWords]
2. Generate some fake words by randomly picking [a-z] characters to form strings of a random length (up to 20 characters). Generate the same number of words as the real words. Generate tuples for them as well where the label is “False”.
maxWordSize = 20
charSet = "abcdefghijklmnopqrstuvwxyz-_"
#generate a fake word
def fakeWord():
retString = []
length = random.randint(1,maxWordSize)
for letter in range(length):
retString.append(random.choice(charSet))
return ''.join(retString)
fakewords = [fakeWord() for i in range(len(labeled))]
labeled.extend([(e,False) for e in fakewords])
3. Shuffle all the tuples
random.shuffle(labeled)
4. Extract features from all tuples
a. Use character trigrams as features. For every word, generate all character trigrams (all combinations of 3 consecutive characters that appear in the word).
b. Since the features are binary, their value will just be True if present.
def getFeatures(inWord):
features = {}
if len(inWord) < 3:
return features
elif len(inWord) == 3:
return {inWord: True}
for window in range(len(inWord)-2):
featureName = inWord[window:window+3]
features[featureName] = True
return features
5. Make training and test sets (2:1) ratio
allDocs = [(getFeatures(w[0]),w[1]) for w in labeled]
splitPoint = len(allDocs) // testRatio
testSet, trainingSet = allDocs[:splitPoint], allDocs[splitPoint:]
6. Call the Naive Bayes training on the training set
classifier = nltk.NaiveBayesClassifier.train(trainingSet)
7. Call the NB built-in accuracy function
print("Accuracy: ",nltk.classify.accuracy(classifier,testSet))
8. Find the most informative features (features that help the classifier the most) using the
built-in NLTK function for this.
print(classifier.show_most_informative_features(20))
Exercise D: Recognizing languages using a multi-class NB classifier
For this exercise, we will use NLTK’s udhr (Universal Declaration of Human Rights) corpus. Just like Exercise C, we will primarily operate on words. Instead of having just two classes (fake word or real word), we now have 14: one for each language in our languages list.The classifier is supposed to solve this problem: Given a single word, which (Latin-1 encoded) language does it belongs to?
A full implementation of a program that does this work is available on Frank (/lib/466/langDemo.py). It is only about 46% accurate which is not high but also not trivial, considering there are only two features and there are 14 languages / labels: Spanish, Welsh, Somali, Romani, Norwegian, Afrikaans, Basque, Danish, Dutch, Finnish, French, German, English, Italian.
Your job is to improve the performance through better feature selection, if possible. Do not change the classifier itself. Do not change anything other than the langFeatures() function.
1. Run the current script and record the average accuracy achieved.
2. Rename the script to labD.py . Change the script to increase the accuracy. Again measure average accuracy by running the classifier 5 times and taking the average.
3. The output should have two lines like this example:
The original script average accuracy (5 trials): 0.5998765
The new script average accuracy (5 trials): 0.6213499
$
(You can hard-code the “original script” accuracy. No need to run it every time).
Assignment
● Submit your labC.py and labD.py in a file called lab5.tar.gz● The highest 3 average accuracies achieved on labD will receive another 1% extra credit to go toward general grade.
2019-05-08