StatComp Project 2 (2020/21): Scottish weather
StatComp Project 2 (2020/21): Scottish weather
Finn Lindgren
This document can either be accessed in html form on (https://finnlindgren.github.io/StatCompLab/), as a vignette in StatCompLab version 0.9.0 or later, with vignette("Project02", "StatCompLab"), or in pdf format on Learn.
1. You have been assigned a project02-username repository on https://github.com/StatComp20/. Use git to clone the repository (either to https://rstudio.cloud or your own computer) in the same way as the lab02-username repository in Lab 2. Do not confuse your own repository with the project02-template repository.
2. The repository contains three template files; modify these, and keep their names:
• a template RMarkdown document, report.Rmd, that you should expand with your answers and solutions for this project assignment,
• a template my_code.R for long-running analysis code
• a template my_functions.R file where you can place function defintions needed by report.Rmd and/or my_code.R
3. Code that display results (e.g. as tables or figures) must be placed as code chunks in report.Rmd.
4. Code in the template files includes an example for how to save and load results of long-running calculations
5. A my-setup code chunk is included in report.Rmd that runs the function definitions from my_functions.R.
6. Two appendix code chunk are included that displays the code from my_functions.R and my_code.R without running it.
7. Use the styler package Addin for restyling code for better and consistent readability works for both .R and .Rmd files.
The assignment is submitted by pushing your work to the github repository before your submission deadline. Make it a habit to commit&push to github regularly, e.g. at least at the end of every coding session.
Make sure you include your name, student number, and github username in both report.Rmd, my_functions.R, and my_code.R. When submitting, also include a generated html version of the report, with filename report.html. Normally, generated images are automatically included in the html file itself; otherwise they need to be added to the repository as well.
The submission deadline is Friday 9 April 2021, at 16:00 (Edinburgh time). See the Assessment page on Learn for extensions and late submission penalty details.
The project will be marked as a whole, between 0 and 40, using the marking guide posted on Learn.
1 Scottish weather data
The Global Historical Climatology Network at https://www.ncdc.noaa.gov/data-access/land-based-station-data/land-based-datasets/global-historical-climatology-network-ghcn provides historical weather data collected from all over the globe. A subset of the daily resolution data set (see https://www.ncdc.noaa.gov/ghcn-daily-description) is available in the StatCompLab package (from version 0.7.0) containing data from eight weather stations in Scotland, covering the time period from 1 January 1960 to 31 December 2018. Some of the measurements are missing, either due to instrument problems or data collection issues. See Tutorial07 for an exploratory introduction to the data, and techniques for wrangling the data.
Load the data with
data(ghcnd_stations, package = "StatCompLab")
data(ghcnd_values, package = "StatCompLab")
The ghcnd_stations data frame has 5 variables:
• ID: The identifier code for each station
• Name: The humanly readable station name
• Latitude: The latitude of the station location, in degrees
• Longitude: The longitude of the station location, in degrees
• Elevation: The station elevation, in metres above sea level
The station data set is small enough that you can view the whole thing, e.g. with knitr::kable(ghcnd_stations). You can try to find some of the locations on a map (google maps an other online map systems can usually interpret latitude and longitude searches).
The ghcnd_values data frame has 7 variables:
• ID: The station identifier code for each observation
• Year: The year the value was measured
• Month: The month the value was measured
• Day: The day of the month the value was measured
• DecYear: “Decimal year”, the measurement date converted to a fractional value, where whole numbers correspond to 1 January, and fractional values correspond to later dates within the year. This is useful for both plotting and modelling.
• Element: One of “TMIN” (minimum temperature), “TMAX” (maximum temperature), or “PRCP” (precipitation), indicating what each value in the Value variable represents
• Value: Daily measured temperature (in degrees Celsius) or precipitation (in mm)
2 Climate trends
2.1 Monthly trends
In Tutorial07, you looked at annual averages. Now, aggregate the data to monthly averages instead, and estimate the long-term temporal trend in TMIN for each month, for each weather station. (You can use a for-loop to iterate over the months when estimating the trend.)
Collect the results into a suitable data structure, and draw a figure that shows how the climate trend varies across the year, for each station (use facet_wrap() or similar).
Discuss the results.
2.2 Seasonally varying variability
Is the temperature variability the same for each month of the year?
Choose a weather station, and for each month, perform a randomisation test for whether the the variance of the daily TMIN residuals from the monthly averages is larger than the overall residual variance. Define the residuals as 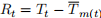 , where
, where 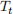 is TMIN at time
is TMIN at time  , and
, and 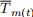 is the average temperature in the month of time
is the average temperature in the month of time  .
.
Present and discuss the results.
3 Spatial weather prediction
3.1 Estimation
Choose a weather station, and make code for estimating a linear model that uses daily TMAX at the other weather stations as covariates for TMAX at the chosen station. Present and discuss the result of estimating a separate model for each month of the year.
Organise your code so that you can easily change the input data without having to change the estimation code. You’ll need to be able to run the estimation for different subsets of the data.
Hint: Start by considering what structure would be easiest to have the data in, and then use combinations of filter(), select() and related functions to achieve that. The pivot_wider can be used to create one data column for each station.
3.2 Assessment
For each month, use 10-fold randomised cross-validation to estimate the expected Absolute Error and Dawid-Sebastiani scores for the TMAX predictions at the chosen station.
Present and discuss the result.
2021-03-19