CSCI 2122 Lab 7: Searching Binary Trees and Constructing Maps
Lab 7: Searching Binary Trees and Constructing Maps
Robert Smith ([email protected])
CSCI 2122 - Winter 2021
1 Introduction
This lab is designed to introduce you to depth-first search (DFS), breadth-first search (BFS), and maps (dictionaries). By the end of this lab, you will be expected to understand how to implement those search algorithms and data structures.
In this lab you are expected to perform the basics of cloning your Lab 7 repository from the GitLab course group. A link to the course group can be found here and your repository can be found in the Lab7 subgroup. See the Lab Technical Document for more information on using git. You will notice that your repository has a file in the Lab7 directory named delete this file. Due to the limitations of GitLab, we are not able to push completely empty directories. Before you push your work to your repository (which should be in the Lab7 directory anyway), make sure to first use the git rm command to remove the extra file. If you do not, your pipeline could fail.
Be sure to read this entire document before starting!
2 Tree and Graph Traversals
In the last lab you were expected to build a binary tree and print the state of that tree in a variety of configurations (in-order, pre-order, post-order, and reverse order). The manner and order in which you move through the trees in order to produce an outcome is referred to as a traversal. Traversals come in many types and throughout your university career in Computer Science you are likely to run into many, especially in your Algorithms Analysis classes. In this lab we will go over, and implement, two of the more well-known traversal algorithms.
In the last lab, you created a binary tree, which consisted of a hierarchal configuration of nodes. Each node consisted of a data pointer, as well as pointers to two potential child nodes. As you inserted data into your binary tree, you followed an algorithm for deciding how to navigate through each node in order to find the correct place to store the incoming data. The rules on the nodes were very specific: once you were in a node, there was no way to go backwards; nodes could only be added as children of nodes who didn’t already have children in the designated place; there was no path through the tree which would have you visit the same node twice. As such, the structure of a binary tree is very restrained, which prevents you from running into more complicated structures, such as nodes which create a path that leads back to a node you’ve visited, which is called a cycle.
A tree is a specific type of structure known as a graph, which is not the bar-chart kind of graph. Graphs are a collection of nodes, also called vertices, which are connected by a series of paths from one node to another, called edges. Graphs, like trees, come in a variety of different types, including directed graphs (you can only travel forward down an edge, but not backward) and undirected graphs (edges can be travelled in both directions). It’s also possible for edges to have weights, which give you the ability to measure things such as distance, or cost, between vertices. Graphs can be visualized as a variety of things, including the time cost it takes to perform a series of tasks, or the cities in a province which are connected by highways. There are many algorithms used for generating valuable data from graphs, but in this lab we are going to restrict ourselves to binary trees and two specific traversals: depth-first search, and breadth-first search.
2.1 Depth-First Search
Depth-first search is performed such that you will travel as deep into the graph as possible, from left-to-right, printing node contents along the way. Printing in depth-first search, in this case, is purely program-specific. You could use a depth-first search (DFS) for a variety of applications in a variety of fields, including:
1. Topological sorting for scheduling algorithms.
2. Solving a sudoku puzzle.
3. Determining if a graph has a cycle in it.
In this lab, you will be tasked with adding a depth-first search function to your binary tree library which prints the contents of each node in the tree in the order determined by the DFS algorithm. To make this task easier to solve, we will use a stack.
We can see in the following diagram the order in which the various nodes should be printed, marked in green:
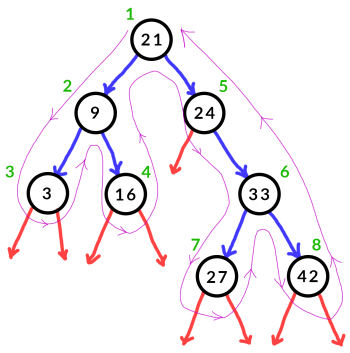
Based on the above diagram, the nodes should be printed in the order 21, 9, 3, 16, 24, 33, 27, 42. In order to facilitate this process, we can use a stack to ensure that we always visit the nodes in the correct order. One thing that we should note about stacks is that they automatically reverse the order of anything that goes in them. That is, if you push the numbers 1, 2, 3, 4, 5, 6 into a stack in order, they will be popped off the stack in the reverse order that they were added, resulting in a popped order of 6, 5, 4, 3, 2, 1. Due to this feature of stacks, it’s important that you push things on in the correct way. When following the steps below, it’s very useful to draw a stack and its contents in order to practice understanding how they work.
To perform a DFS on a binary tree, you will need to create a stack. Once the stack is created, the first (root) node of your binary tree should be placed in that stack. At this point we can begin the algorithm. We first check to see if the stack is empty. If the stack is empty, then we have visited every node in our tree and we can stop the algorithm. Every time we are finished processing a node, we will repeat this check.
After we have performed our stack emptiness check, we can move on to processing a node. We will first pop a node off the top of the stack and store it. We can print the contents of the node, then we can add that node’s children to the stack. Be careful with the order in which the children are added! Once we have added the children of the current node to the stack, we have completed processing this node. Check whether the stack is empty, and once all nodes have been printed, we can stop processing.
This algorithm works by placing the nodes we want to process later further down the stack, while placing the nodes we want to process sooner near the top. Since we are using a stack, the nodes will progress downward through a single path as far as possible before running out of “deep” children, at which point it will begin looking at nodes we saw previously in the process (which we saved for later). It’s very useful to draw this algorithm step-by-step to see exactly how the nodes are stored in the stack and why the push order matters.
2.2 Breadth-First Search
Breadth-first search is performed such that you will travel to each node’s immediate neighbours, from left-to-right, printing node contents along the way. Printing in breadth-first search, in this case, is purely program-specific. The breadth-first search (BFS) algorithm is the base for many applications that you use on an everyday basis and you are likely to see it (and modifications of it) throughout your Computer Science career. Some major uses for BFS include:
1. Finding cycles in graphs.
2. Finding peers in peer-to-peer networks by looking for nearest neighbours.
3. Finding shortest paths in graphs (with some modifications).
4. Detecting nearest neighbours and sending network-wide messages in network routing.
5. Determining friends-of-friends on social media sites, such as Facebook.
6. Finding paths on mapping/GPS algorithms in order to determine what the quickest route might be.
In this lab, you will be tasked with adding a breadth-first search function to your binary tree library which prints the contents of each node in the tree in the order determined by the BFS algorithm. To make this task easier to solve, we will use a queue.
We can see in the following diagram the order in which the various nodes should be printed, marked in green:
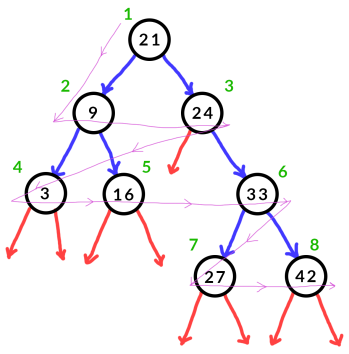
Based on the above diagram, the nodes should be printed in the order 21, 9, 24, 3, 16, 33, 27, 42. In order to facilitate this process, we can use a queue to ensure that we always visit the nodes in the correct order. Since we will be using a queue, we are leveraging the feature that queues let us ”save data for later”, letting us set up an ordering of nodes which coincides with the order in which the nodes were seen. This way we don’t have to rely on a very specific recursive algorithm to figure out the breadth-first ordering (which can be a challenge). Instead we can use a loop and perform a search based on the nodes we’ve seen, slowly making our way farther from the root as we see more and more child nodes.
To perform a BFS on a binary tree, you will need to create a queue. Once the queue is created, the first (root) node of your binary tree should be placed in that queue. At this point we can begin the algorithm. We first check to see if the queue is empty. If the queue is empty, then we have visited every node in our tree and we can stop the algorithm. Every time we are finished processing a node, we will repeat this check.
After we have performed our queue emptiness check, we can move on to processing a node. We will first dequeue a node from our queue and store it. We can print the contents of the node, then we can add that node’s children to the queue. Be careful with the order in which the children are added! Once we have added the children of the current node to the queue, we have completed processing this node. Check whether the queue is empty, and once all nodes have been printed, we can stop processing.
This algorithm works by placing the nodes we want to process next immediately into the queue. This means we will see all of the current node’s children before we see any of their children, meaning we should see each ”layer” of the tree from top to bottom, in order. It’s very useful to draw this algorithm step-by-step to see exactly how the nodes are stored in the queue and why the enqueue order matters.
3 Maps
A map is a data structure which allows you to create a relationship between one piece of data and another. With traditional arrays and lists, you generally correspond an index value (typically an integer in [0, N N 1] for lists of size N) to a stored value, which is held in a block of contiguous memory. This implies there is some ordering to your data, whether it is intentional or not, and it is left up to you how you manage that ordering.
Maps, on the other hand, provide a mechanism for storing data in a mapping, which is generally represented as a key → value pair. The key determines what you want to use as an indexing for the value, which is the data you want to store. A simple example of a mapping might be fruit and the their color, so you may find the apple → red, orange → orange, grape → purple mappings that adhere to those rules. This means that rather than store values by index, we can store them by some key.
However, this requires a bit of extra storage. Storing these keys and values is not as simple as an array or a list. Since the keys are not necessarily numerical, it’s not as easy as jamming the keys and/or values into a list and hoping that they work. Instead, we have to come up with a way of being able to access our keys reasonably quickly while also insert them in a way that makes it easy to store and organize those key/value pairs.
Luckily, we already have a data structure which is capable of performing this task for us: a binary tree. Since our binary tree stores a function for comparing data types in order to determine exactly where they should be stored relative to the root note (and they are generally stored in order from left-to-right), we should be able to take advantage of this data type to create and manage a map.
For this lab, you will be using your binary tree program to create a tree map, which will we call a dictionary. A tree map holds a series of Pairs (a data type you will need to define), where each Pair contains a first and second void pointer. The first pointer will be used as your key and the second pointer will be used as your value. Every time a key/value pair is added to your dictionary, you will create a new Pair to hold that data, then store it in your binary tree by following the regular rules of the binary tree. You will need to provide a custom compare method which is capable of comparing the keys of two Pairs, but this functionality should already exist as a part of the base binary tree implementation from Lab 6. In order to better facilitate the proper management of data in the binary tree, it will be necessary for you to have included the ability for your binary tree to overwrite existing nodes with new data. You are required to write this function as a part of the Search contract in this lab.
Unlike previous labs, you do not have to make copies of every piece of data in your dictionary. It is acceptable in this contract to deal with pointers without the need of memcpy. As long as you manage your pointers properly, the dictionary should not break!
3.1 Initializing a Dictionary
Initializing your dictionary is similar to the binary tree. You will need to pass in a function pointer for a compare function and a print function. When you initialize the tree (which will act as the data storage structure for the dictionary), you will need to tell it to hold the Pair type, and give it the size of a Pair so it is able to create/store that data structure appropriately. Once the binary tree is initialized and stored in the Dictionary, you can return a pointer to the Dictionary you have created.
3.2 Inserting into a Dictionary
To insert a value into a dictionary, you will need to provide two void pointers: the first is the key and the second is the value. The key is the data which will be used to retrieve the value later (see Retrieving a Value below). When the key and value are passed into the function, you will need to create a Pair to hold those values, and then insert them in into the underlying binary tree. The binary tree should operate normally, using its custom compare function to determine whether or not a given Pair should be stored left or right of a given node based on a comparison between their first (key) pointers. If the provided key already exists in the dictionary, its value shouldbe updated to reflect the newly provided value.
For the purposes of testing your dictionary, the test files in the GitLab repository will use strings (char*) as a key, and the compare function will compare them character-by-character using strcmp to determine if they should be inserted in the left or right child of any given node (negative comparison results are left, and equal or positive comparison results are right).
3.3 Retrieving a Value from a Dictionary
To retrieve a value from a dictionary, you will need to provide the key whose associated value you would like to retrieve. When the function is called, you will need to manually iterate through the Dictionary’s binary tree and compare the provided key against each applicable node. Starting at the root node, compare the key to the root node’s key using the binary tree’s compare function. If they are equal, then return a pointer to that node’s value. If the key is less than the node’s key, repeat this process on the left child node. If the key is greater than the node’s key, repeat this process on the right child node. If you attempt to repeat this process on a node pointer which is NULL, you should return NULL. Repeat this process until a value is returned or you run out of nodes to check.
3.4 Retrieving a List of all Keys from a Dictionary
To retrieve a list of all keys from a dictionary, you will need to perform a left-to-right search on the binary tree and store each key in a list. In the case of this lab, the list of keys should be stored in an array list and they should be in sorted order based on a left-to-right ordering from the binary tree. You will need to create an array list, then perform that traversal, adding each key to the list as it is found. Once the traversal has completed, you should return the array list. You may find it useful to create a recursive helper function to populate your array list in a simple manner.
3.5 Determining if a Key Exists in a Dictionary
To determine if a key exists in a dictionary, you will accept a key and use it to perform a binary search on the underlying tree. If the binary search returns true, then this function should also return true.
4 Lab 7 Function Contracts
In this lab you will be responsible for fulfilling two lab contracts: the Search contract, and the Dictionary contract. Each contract is designed to test you on some of the things you’ve learned throughout the instruction portion of this lab.
All contracts must be completed exactly as the requirements are laid out. Be very careful to thoroughly read the contract instructions before proceeding. This does not, however, preclude you from writing more functions than you are asked for. You may write as many additional functions as you wish in your C source files.
All contracts are designed to be submitted without a main function, but that does not mean you cannot write a main function in order to test your code yourself. It may be more convenient for you to write a C source file with a main function by itself and take advantage of the compiler’s ability to link files together by accepting multiple source files as inputs. When you push your code to Gitlab, you don’t need to git add any of your extra main function source files.
For those of you who are concerned, when deciding which naming conventions you want to use in your code, favour consistency in style, not dedication to a style that doesn’t work.
The contracts in this document are worth the following points values, for a total of 10.
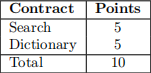
4.1 Search
4.1.1 Problem
You will be adding additional functions to your bintree.c and bintree.h files from Lab 6.
4.1.2 Preconditions
You are required to modify your previous program for handling binary trees by adding four additional functions. Your new program consists of bintree.c, which should contain all of your function implementations, and bintree.h, which should contain your structure definition, any necessary typedefs, and all of your forward function declarations. When you compile, you will need to include the source file in your command in order to ensure the functions exist during the linking process. You may include any additional helper functions as you see fit. Since you are dealing with pointers, you will need to check all of your pointers to ensure they are not null. Trying to perform operations on null will lead to segmentation faults or other program crashes at run-time.
Your BinaryTree is a typedeffed structure, but as long as the type works with all of the function contracts listed below, you’re still free to design your struct however you’d like.
The details of the additional Binary Tree functionality are described in the Tree and Graph Traversals section of this document. The bool type referenced in this contract is found in <stdbool.h>. You are expected to do basic error checking (such as checking for null pointers and correct index boundaries).
Your bintree program must include the following functions, in addition to the bintree functions required in Lab 6:
|
Requirement
|
Conditions
|
|
Function
|
void bintree print breadth first(BinaryTree*)
|
|
Input Parameters
|
A pointer to a BinaryTree.
|
|
Return Value
|
None.
|
|
Notes
|
This function should accept a BinaryTree and print the content of its nodes in the order
described earlier in this lab, using a depth-first search.
|
|
Requirement
|
Conditions
|
|
Function
|
void bintree print depth first(BinaryTree*)
|
|
Input Parameters
|
A pointer to a BinaryTree.
|
|
Return Value
|
None.
|
|
Notes
|
This function should accept a BinaryTree and print the contents of its nodes in the order
described earlier in this lab, using a breadth-first search.
|
|
Requirement
|
Conditions
|
|
Function
|
bool bintree insert replace(BinaryTree*, void*)
|
|
Input Parameters
|
A pointer to a BinaryTree and a void pointer representing an element.
|
|
Return Value
|
True if the element was successfully inserted into the BinaryTree. Otherwise false.
|
|
Notes
|
This function should insert in the same manner as the normal insert function, with the extra
functionality being that if a node already contains the provided element (based on the
BinaryTree’s currently stored compare function), it should overwrite that element with the
data held by the incoming element’s pointer. This will be useful for updating values in your
dictionary in the next contract.
|
|
Requirement
|
Conditions
|
|
Function
|
bool bintree insert replace recursive(BinaryTree*, BinaryTreeNode*, void*)
|
|
Input Parameters
|
A pointer to a BinaryTree, a pointer to a BinaryTree node, and a void pointer representing
an element to be inserted.
|
|
Return Value
|
True if the element was successfully inserted into the BinaryTree. Otherwise false.
|
|
Notes
|
This function should be called by the bintree insert replace function to aid in the
recursive traversal process. This function will do the majority of the traversal and will print
the values accordingly.
|
4.1.3 Postconditions
Your program should be capable of producing Binary Tree ( bintree) structures. All of the functions should be capable of executing without crashing. Failure states should be handled by return values. If a function with a void return type fails, it does not need to be reported.
4.1.4 Restrictions
None.
4.1.5 File Requirements
This contract requires you to provide a C source file named bintree.c and a C header file named bintree.h. Your header files should contain your forward declarations, struct definitions and typedefs, as well as any library imports (includes) you may need. Always protect your header with a define guard. Your source files must not contain any main functions when you submit, or your program will fail during marking.
In addition to the C files, you will also be required to make a Makefile for the search program. Your program will be compiled by executing make. Your Makefile should produce the following files:
1. bfs (compile using bfsM.o)
2. dfs (compile using dfsM.o)
3. search (compile using searchM.o)
4. search.o
All .o files designed for testing and compilation are located in CI/objects/search.
Your source, header, and make files should be placed in the Lab7/search/ directory in your GitLab repository.
4.1.6 Testing
To test your code, you can compile your source files with the searchM.o object file, the bfsM.o object file, and the dfsM.o object file, all found in CI/objects/search. Your programs can then be executed as normal. The object files contain a main function, so you do not need to provide your own. Using a Makefile for compiling these files together can save you a lot of time.
4.1.7 Sample Inputs and Outputs
We provide a complete output file, but do not use it for comparison in the pipeline. The main object files for this program will test your various functions on a Binary Tree. Your code should minimally be able to complete the test main function in the object file, but you may find it more convenient to test your functions with your own main function first. Writing your own main function for testing purposes can be extremely helpful.
4.2 Dictionary
4.2.1 Problem
You must create a structure and set of functions for managing a dictionary.
4.2.2 Preconditions
You are required to write a program for handling a dictionary. This consists of dictionary.c, which should contain all of your function implementations, and dictionary.h, which should contain your structure definition, any necessary typedefs, and all of your forward function declarations. When you compile, you will need to include the source file in your command in order to ensure the functions exist during the linking process. You may include any additional helper functions as you see fit. Since you are dealing with pointers, you will need to check all of your pointers to ensure they are not null. Trying to perform operations on null will lead to segmentation faults or other program crashes at run-time.
The details of the dictionary functionality are described in the Maps section of this document. The bool type referenced in this contract is found in <stdbool.h>. You are expected to do basic error checking (such as checking for null pointers and correct index boundaries).
Your dictionary program must include the following structs (typedef-ed appropriately):
|
Structure Name
|
Fields
|
Functionality
|
|
_Pair (typedef Pair)
|
void* first
void* second
|
Contains the first value of a pair (key).
Contains the second value of a pair (value).
|
|
_Dictionary (typedef Dictionary)
|
BinaryTree* tree
|
Contains the binary tree for storing your
Pairs in BinaryTreeNodes.
|
Your dictionary program must include the following functions:
|
Requirement
|
Conditions
|
|
Function
|
Dictionary* dict initialize(int (*)(void*, void*), void (*)(void*))
|
|
Input Parameters
|
A function pointer to an int(void*, void*) comparison function and a function pointer
to a void(void*) print function.
|
|
Return Value
|
The pointer to a fully initialized Dictionary.
|
|
Notes
|
This function should create a Dictionary which is holding a fully initialized BinaryTree.
|
|
Requirement
|
Conditions
|
|
Function
|
bool dict insert(Dictionary*, void*, void*)
|
|
Input Parameters
|
A pointer to a Dictionary, a void pointer to a key, and a void pointer to a value.
|
|
Return Value
|
True if the key/value pair was successfully added to the dictionary. Otherwise false.
|
|
Notes
|
This function should create a Pair where first=key and second=value, then
insert it in the correct location of the underlying binary tree.
|
|
Requirement
|
Conditions
|
|
Function |
void* dict get(Dictionary*, void*) |
|
Input Parameters
|
A pointer to a Dictionary and a void pointer to a key.
|
|
Return Value
|
A void pointer representing the value associated with the key.
|
|
Notes
|
This function should search through the underlying binary tree for a node which contains
the provided key and then return its associated value as a void pointer.
|
|
Requirement
|
Conditions
|
|
Function |
ArrayList* dict key list(Dictionary*, int) |
|
Input Parameters |
A pointer to a Dictionary and an integer representing an allocation size. |
|
Return Value
|
An array list where the elements stored are the keys of the dictionary in left-to-right order.
|
|
Notes
|
Each key should be allocated an amount of space equal to the provided size integer.
|
|
Requirement
|
Conditions
|
|
Function
|
bool dict contains(Dictionary*, void*)
|
|
Input Parameters
|
A pointer to a Dictionary and a void pointer to a key.
|
|
Return Value
|
True if the key is present in the dictionary. Otherwise false.
|
|
Notes
|
None.
|
4.2.3 Postconditions
Your program should be capable of producing Dictionary ( Dictionary) structures. All of the functions should be capable of executing without crashing. Failure states should be handled by return values. If a function with a void return type fails, it does not need to be reported.
4.2.4 Restrictions
None.
4.2.5 File Requirements
This contract requires you to provide a C source file named dictionary.c and a C header file named dictionary.h. Your header files should contain your forward declarations, struct definitions and typedefs, as well as any library imports (includes) you may need. Always protect your header with a define guard. Your source files must not contain any main functions, or your program will fail during marking.
In addition to the C files, you will also be required to make a Makefile for the dictionary program. Your program will be compiled by executing make. Your Makefile should produce both a dictionary.o file and a dictionary executable file by compiling your code with the dictM.o file located in CI/objects/dictionary. Your source, header, and make files should be placed in the Lab7/dictionary/ directory in your GitLab repository.
4.2.6 Testing
To test your code, you can compile your source files with the dictM.o object file found in CI/objects/dictionary. Your program can then be executed as normal. The object file contains a main function, so you do not need to provide your own when you submit to GitLab. Using a Makefile for compiling these files together can save you a lot of time.
4.2.7 Sample Inputs and Outputs
A sample output is provided, but is not used in a comparison when executing your pipeline. The main object file for this program will test your various functions on a Dictionary. Your code should minimally be able to complete the test main function in the object file, but you may find it more convenient to test your functions with your own main function first.
4.2.8 Compare and Print Functions
The compare function and print function passed into your initialize function are written as follows:
This means that, in practical terms, the test main function expects you to create a Dictionary which holds a Pair type. Both the compare and print functions expect to be given Pair pointers.
5 Submission
5.1 Required Files
Each file must be contained in the directory listed in the structure requirement diagram below. These files include:
1. bintree.c
2. bintree.h
3. dictionary.c
4. dictionary.h
5. Makefile (for search)
6. Makefile (for dictionary)
You may submit other files that your Makefile needs to function correctly. Note that the above files are simply the minimum requirements to pass the pipeline. Any additional files will not count against you.
5.2 Submission Procedure and Expectations
Your code will be submitted to your Lab 7 GitLab repository using the same method as outlined in the Lab Technical Document. Refer to that document if you do not remember how to submit files via the GitLab service. A link to your repository can be found in the Lab7 subgroup of the CSCI 2122 GitLab group here.
As mentioned in the Lab Technical Document, we will provide you with a CI/CD script file which will help you test your submissions. The .yml file containing the CI/CD test script logic, and any other necessary script files, are available in your repository at all times. You are free to view any of the script files to help you understand how our marking scripts will function. We make extensive use of relative path structures for testing purposes, which is why strict adherence to directory structure and file contents is such a necessity. Also remember to check your pipeline job outputs on the GitLab web interface for your repository to see where your jobs might be failing.
Remember to follow the instruction guidelines as exactly as possible. Sometimes the pipeline scripts will not test every detail of your submission. Do not rely on us to perfectly test your code before submission. The CI/CD pipeline is a great tool for helping you debug major parts of your submissions, but you are still expected to follow all rules as they have been laid out.
5.3 Submission Structure
In order for a submission to be considered valid, and thus gradable, your git repository must contain directories and files in the following structure:
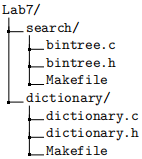
As with all labs, accuracy is incredibly important. When submitting any code for labs in this class, you must adhere to the directory structure and naming requirements in the above diagram. Failure to do so will yield a mark of 0. That said, in this lab, your directory structure requirement is to minimally have these files, but you may have more as you require.
Remember to remove Lab7/delete_this_file from your repository using git rm to avoid any pipeline failures.
5.4 Marks
This lab is marked out of 10 points. All of the marks in this lab are based on the successful execution of each contract. Any marking pipeline failures of a given contract will result in a mark of 0 for that contract. Successful completion of the various contracts will award points based on the following table:
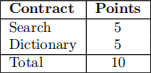
2021-03-10
This lab is designed to introduce you to depth-fifirst search (DFS), breadth-fifirst search (BFS), and maps (dictionaries). By the end of this lab, you will be expected to understand how to implement those search algorithms and data structures.