CSCI 3366 Problem Set 4: Grammars & Parsing
CSCI 3366 Programming Languages
Problem Set 4: Grammars & Parsing
Due: Tuesday, March 9, 2021, 6PM
(12 Points)
Part 1 (5 points): Re-associating Expressions
We saw in class an example of a parser for arithmetic expressions where every operation was parsed in a right associative way. That is, 2 - 2 - 2 was parsed as 2 - (2 - 2). However, for many operations, the standard mathematical convention is for the operation to be left associative. For example, minus should be left associative, so that 2 - 2 - 2 ought to be parsed as (2 - 2) - 2.
However, we saw that right associativity is easier to parse by default in a recursive descent style. In the next part of this assignment, you will write a parser that handles left associativity by transforming the grammar a version that is suited to recursive descent.
In this part we consider an alternate strategy: re-associating a parse tree so that the operations will be left-associative. For this exercise, we will consider the following simple AST type found in reassoc-src/bin/main.ml
type ast =
| Int of int
| Plus of { op1 : ast; op2 : ast }
| Minus of { op1 : ast; op2 : ast }
| Parens of ast
where the Parens constructor represents parentheses around an expression. (Parentheses are usually omitted during the act of parsing, but since we are going to change the groupings of operations as part of reassociating, it makes sense to include here.)
In reassoc-src/bin/main.ml you must write a function leftAssociate : ast -> ast that takes as input an AST and returns a version in which the Plus and Minus operations have been left-associated. For example, on an input tree of the form
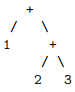
Your code should return the AST corresponding to
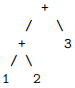
That is, you would convert Plus { op1 = Int 1; op2 = Plus { op1 = Int 2; op2 = Int 3 }} into Plus { op1 = Plus { op1 = Int 1; op2 = Int 2 }; op2 = Int 3 }.
Note that your code should not rearrange operands around the boundaries of parentheses. That is, on the input
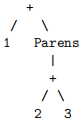
you should return back the same tree.
You should not insert or remove occurrences of the Parens constructor, and your code should only change associativity, not swap the order of arguments or otherwise change the Int values. You probably want to write extra test cases and consider some simple examples in addition to the tests we give you.
To compile and run the unit tests for this part, run:
> cd reassoc-src
> dune exec bin/main.exe test
Part 2 (7 Points): Parsing Mercury
Mercury is a trivial pedagogical “programming” language featuring only integer expressions with binary operators +, -, *, / and % (mod). A REPL implementa-tion of Mercury allows expressions to be entered with or without parentheses. The operators are all left-associative and with the usual precedence. Evalua-tion is straightforward with one important property: Mercury traps division by zero errors. In this problem set, you are required to left-factor a grammar for Mercury’s concrete syntax and write a recursive-descent parser based on the resulting grammar.
The directory mercury-src/bin contains OCaml harness code implementing most of a REPL (parser + evaluator) for the mini-PL Mercury. The files in this directory are:
You should give these files a good once-over before you begin coding. I suggest first looking at token.mli, symbol.mli and then ast.mli.
Once you begin coding, your work will largely be confined to the file parser.ml. In particular, you’re required to implement the single function specified in parser.mli
val parser : Token.t list -> Ast.t
Heads up! The Token module has a lot of tokens that are not used in Mercury. This is because the Token module will be used for other mini-programming languages. The tokens that appear in well-formed Mercury programs are
PLUS | MINUS | TIMES | DIV | MOD | LPAR | RPAR | INTEGER of int | QUIT
To compile and run your implementation of the Mercury REPL:
> cd mercury-src
> dune exec bin/main.exe
Mercury >
To compile and run the unit tests for this part, run:
> cd mercury-src
> dune exec bin/main.exe test
The Parser
Let i denote an integer token. Then the concrete syntax for Mercury is given by the following context-free grammar where E is the start symbol.
V ::= i
E ::= E + T | E - T | T
T ::= T * F | T / F | T % F | F
F ::= V | ( E )
This grammar uses left-recursion to make all operators associate to the left and uses layering to give *, / and % higher precedence than + and -.
In order to write a recursive descent parser for Mercury, you’ll need to left-factor this grammar using the rule:
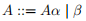
Is replaced by two rules:

For example, when we apply this transformation to the rules for for E, we get:
E ::= T E'
E' ::= + T E' | - T E' | empty
...
where we have introduced a new symbol E' that represents the “tail” of an E string. You will need to similarly transform the rules for T as appropriate.
Once you’ve left-factored the grammar, you can use it as a guide to write a set of mutually recursive functions, each responsible for parsing a portion of the language. Of course, each will need to build an ast as defined in ast.ml, and return a list of pending tokens that remain to be parsed, as in the example parsers we looked at in class. If the sequence of tokens don’t give rise to a well-formed Mercury program, your code can raise an exception using failwith.
There’s one new trick we need to apply in constructing such a parser compared to the example we saw in class. If we think about how to handle parsing E and E' in the transformed grammar above, the function for E will first call the function for T, which will return an AST, call it ast1. Then, it will call the function for E'. In the right associative grammar parsers we saw in class, we would have gotten the AST that E' returns, say ast2, and then returned an AST like:
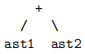
but we can’t do that here because we want the operations to be left-associative. The trick instead is to have the function that parses E' take 2 arguments: tokens, the remaining list of tokens to parse, and ast, the AST that has been constructed so far in the course of parsing the E symbol that led us to E'. The idea is that this second argument is going to accumulate the left-associated tree. In the E' function, if we next find +, we make a recursive call to parse T to get some AST ast', and then we make a recursive call to E', where for the second argument we can pass
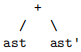
and similarly if the next token we found was - instead. If we find neither a + or a -, then we can just return the ast argument that we’ve been accumulating. If you simulate a few steps of this process in your mind or on paper, you can see that the tree we will build up this way will be left associated.
You will use a similar trick in the function for parsing T after applying the left factoring transform.
Abstract Syntax
The grammar above specifies the concrete syntax of Mercury. The abstract syntax is simpler:
V ::= i
op ::= + | - | * | / | %
E ::= V | E op E
You’ll note there that we are treating the familiar infix operators as though they were ordinary prefix functions. For example, the concrete syntax "2 + 3" would be represented by the application:
Ast.App { rator = Symbol.fromString "+"
; rands = [Ast.Literal 2; Ast.Literal 3]
}
The value of the expression above would be represented by Dynamic.Literal 5.
2021-03-07