CISC-235 Data Structures W21
CISC-235 Data Structures W21
Assignment 2
February 18, 2021
How to Submit
You need to submit your python code for all questions. You must comment your code. Name your folder as your netid-A2, zip the folder and upload it to OnQ. Check whether your code is runable before submitting.
1 Binary Search Tree: 5+5+10 points
Binary search tree (BST) is a special type of binary tree which satisfies the binary search property, i.e., the key in each node must be greater than any key stored in the left sub-tree, and less than any key stored in the right sub-tree.
See a sample binary search tree below:
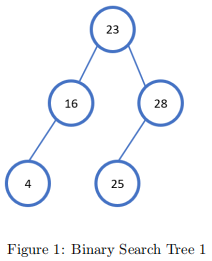
Your task is to create a class named BinarySearchTree satisfying the following requirements (you can create more methods/attributes if needed):
1) Must have an insert function (i.e., insert a new node). You may assume that the values to be stored in the tree are integers.
2) Must have a getTotalHeight function that computes the sum of the heights of all nodes in the tree. Your getTotalHeight function should run in O(n) time.
3) Must have a getWeightBalanceFactor function. The weight balance factor of a binary tree is a measure of how well-balanced it is, i.e., how evenly its nodes are distributed between the left and right subtrees of each node. Note that, WeightBalanceFactor is different from the balance factor introduced in lecture.
More specifically, weight balance factor of a binary tree is the maximum value of the absolute value of difference between the number of nodes in left subtree and in right subtree for all nodes in the tree.
For example, given the binary search tree shown in Figure 2, your function should return 2. Why? We need to calculate the difference between the number of nodes in left and right subtree for all nodes in the tree. For root node 6, this value is 1 (3 nodes in right subtree - 2 nodes in left subtree). Similarly, for node 4, 9, 5, 8, 7, we have the difference at each node being 1, 2, 0, 1, 0. Thus the return value, is 2, which is the max of 1, 1, 2, 0, 1, 0 .
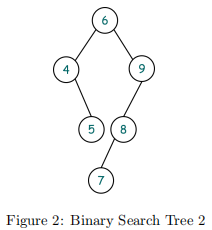
4) You also need to write test code for the three requested functions. You can use the following code https://www.geeksforgeeks.org/print-binary-tree-2-dimensions/ to print the structure of your tree before and after inserting a new node.
Note, you can also write your own method to print a tree.
2 A Simple Search Engine: Background
You probably use Google at least 10 times a day to dig through the vast amount of information on the web. But do you know how search engines store web pages and retrieve the most relevant web pages given a query? In this assignment, we will be trying out one technique that is used by most search engines via building an index of the words on a page. For each word we encounter on a web page, we will count how many times the word appears in the page and keep a list of all locations for each word (the locations can help search engines locate words). For instance, given the following text: “A data structure is a way to store and organize data” If we scan the text and index all words in the text (start from position 0, letters are lower cased), we will have Table 1.
Table 1: Word Index Table for “A data structure is a way to store and organize data”
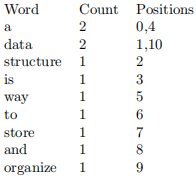
The key idea of search engines is to identify the most relevant documents to a given search query. A search query is a sequence of words representing what you would like to search for, e.g., ”how to sort dict in Python”.
2.1 AVLTreeMap: 20 points
Your first task is to implement a new data structure named AVLTreeMap. AVLTreeMap is just an AVL tree in disguise, where each node in the tree con-tains a “key-value” pair. We know that AVL tree is a special type of search tree. Similarily, in AVLTreeMap, the position of each node is determined based on the key. The key can be an integer or a string, and the value paired with each key can be a string or a list.
1) Each node has left and right child, key, value, and height of the node for adjusting tree structure.
2) Must have a get(key) function that returns the value if the given key exists in the AVL tree. Return null if the key isn’t in the tree, or the associated value if it is.
3) Must have a put(key, value) function (i.e., insert a new key-value pair into the tree). Your put function should adjust the structure in order to maintain a valid AVL trees, i.e., perform rotations if needed and update node height if needed. You can assume that we do not have key-value pairs with the same key.
4) Create an AVLTreeMap by inserting the following key-value pairs in order: 15-bob, 20-anna, 24-tom, 10-david, 13-david, 7-ben, 30-karen, 36-erin, 25-david. Use the above AVLTreeMap test your get and put function.
2.2 WebPageIndex: 20 points
Write a WebPageIndex class that will contain the index representation of a web page. This class will help you transfer a web page (text file in this assignment) into an AVLTreeMap, where each key refers to each word appearing in the document, and each value represents a list containing the positions of this word in the file.
Your WebPageIndex class should satisfy the following requirements (you can create more instance variables/functions if you want):
1) Implement a _ _init_ _(self, file) function that initilizes an instance of Web-PageIndex from a txt file. Must have an attribute specifying the path of the file used for initilizing the WebPageIndex instance. Lower case all words appearing in the input file.
2) Implement a getCount(s) function that returns the number of times the word s appeared on the page.
3) Test your WebPageIndex class using data/doc1.txt.
2.3 WebpagePriorityQueue: 30 points
Your task is to write a heap-based implementation of a PriorityQueue named WebpagePriorityQueue. It should contain an array-based list to hold the data items in the priority queue. Your WebpagePriorityQueue should be a maxheap. The most relevant web page given a specific query will have the highest priority value so that this web page can be retrieved first.
Your WebpagePriorityQueue class should satisfy the following requirements (you can create more instance variables/functions if you want):
1) Must have an initilization function which takes a query (string) and a set of WebpageIndex instances as input. This function will create a max heap where each node in the max heap represents a WebpageIndex instance. The priority of a WebpageIndex instance is defined as the sum of the word counts of the page for the words in the query. For instance, given a query “data structures”, and a WebpageIndex instance, the prior-ity value of this web page should be: sum(number of times “data” appears in the page + number of times “structures” appears in the page).
2) Must contain an attribute specifying the query string that determines the current WebpagePriorityQueue.
3) Must have a peek function. Return the WebpageIndex with the highest priority in the WebpagePriorityQueue, without removing it.
4) Must have a poll function. Remove and return the WebpageIndex with the highest priority in the WebpagePriorityQueue.
5) Must have a reheap function which takes a new query as input and reheap the WebpagePriorityQueue. This is required as the priority value of each web page is query-dependent.
2.4 Implement a simple web search engine: 10 points
Create a python file named ”processQueries.py”. This script implements a sim-ple web search engine.
First, implement a function named readFiles, which takes a folder path as input, and returns a list of WebPageIndex instances, representing the txt files in the given input folder.
In the main function, given a query file (each line represents one search query), create a WebpagePriorityQueue instance to process queries in the query file in a loop. For every subsequent search query, use the new query to re-heap your collection of WebPageIndex instances in the created WebpagePriori-tyQueue instance. Then prints out the matching filenames in order from best to worst match until there are no matches(no words in the query appear in the txt file) or the user specified limit (e.g., return at most 3 matched files) is reached.
Test your web search engine using the provided data folder and query file.
2021-03-04