CMPSC 448: Machine Learning and AI 2022
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CMPSC 448: Machine Learning and AI
Homework 1
2022
Instruction
This HW includes both theory and coding problems. Please note that:
• You cannot look at anyone else’s code.
• Your code must work with Python 3.5+ (you may install the Anaconda distribution of Python)
• For theory problems, please show all the detailed steps.
• You need to submit a report including solutions of theory problems and snapshot of code and result for coding problem (in PDF format) via Gradescope, and the completed Jupyter notebook via Canvas (please see Deliverables section at the end).
Linear Algebra, Calculus, Probability and Statistics
Problem 1 [20 points] In this problem, you are given two matrices A, B ∈ R2×2 and a vector x ∈ R2
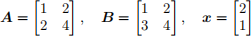
and asked to answer the following questions about them.
(a) What is A × B?
(b) What is x⊤Ax?
(c) What is x⊤x?
![]()
![]() , x =
, x = ![]()
![]()
![]()
(d) What is xx⊤?
(e) What is the projection of x onto the subspace spanned by the columns of A?
(f) Let f : R2 → R be the function given by f(z) = z⊤Az. What is the gradient of f with respect to z , i.e. ∇zf(z)?
(g) For the function f defined above, what is ∇![]() f(z) (the Hessian of f with respect to the vector z ∈ R2)? (h) What is the maximizer of f among all vectors with unit Euclidean length, ∥z∥2 = 1?
f(z) (the Hessian of f with respect to the vector z ∈ R2)? (h) What is the maximizer of f among all vectors with unit Euclidean length, ∥z∥2 = 1?
Problem 2 [10 points] For this problem, we use the following notation for random variables:
• X ∼ N(µ,σ2): X is a Gaussian random variable with mean µ and variance σ2
• X ∼ Bern(p): X is a {0, 1}-valued Bernoulli random variable with expectation p.
• E[X]: the expected value of random variable X
![]()
![]() (a) If X ∼ N(1, 2), then what is E[X]? What is E[X2] − E[X]2?
(a) If X ∼ N(1, 2), then what is E[X]? What is E[X2] − E[X]2?
(b) If X1,X2,...,Xn be independent random variables with Xi ∼ Bern(p),i = 1, 2,...,n, what is the distribution of P![]() Xi?
Xi?
(c) Let assume the sequence {0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1} is independently drawn from Bern(p) (multi- ple flips of a biased coin with probability of being head as p which is unknown). What is the maximum likelihood estimator (MLE) of p? Please show the detailed steps (and mathematical derivations you employ to get the MLE estimator).
Problem 3 [5 points] What is the rank of the following matrix and why?
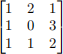
Problem 4 [5 points] Use either numpy.linalg or scipy.linalg to find the eigendecomposition of the following matrix:
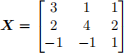
Problem 5 [5 points] For the function f(x) = ln ![]() 1 + e −2x
1 + e −2x![]() , what is it derivative
, what is it derivative 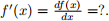
Problem 6 [10 points] Let x ∈ Rd be a vector in d dimensional space and define the vector valued function f : Rd → R by
f(x) = x⊤Ax + b⊤x,
where A ∈ Rd×d is a symmetric matrix and b ∈ Rd is a fixed vector. Using the definition of gradient show that
∇f(x) = Ax + b
Problem 7 [5 points]
(a) What is the maximizer of g : [ −4, 4] → R given by g(x) = ![]() x3 −
x3 − ![]() x2 − 6x +
x2 − 6x + ![]() ?
?
(b) What is R01 g(x)dx for g defined above?
Exploratory Data Analysis with pandas
Problem 8 [40 points] The goal of this problem is to do basic data analysis on a simple data set using pandas package in Python (no machine learning for now). As it has been emphasized in the lectures, we need to have a good understanding of data before training a machine learning model. In this assignment, you are asked to analyze the UCI Adult data set. The Adult data set is a standard machine learning data set that contains demographic information about the US residents. This data was extracted from the census bureau database found at: http://www.census.gov/ftp/pub/DES/www/welcome.html. The data set contains 32561 instances and 15 features (please check the notebook for possible values of each feature) with different types (categorical and continuous).
The data is provided as a csv file and can be loaded into panda’s DataFrame object as shown: data = pd.read_csv('adult.data.csv ')
You are asked to answer following questions about this data set. Please note that you need to use pandas functionalities to answer these questions, rather than implementing pure Python code.
1. How many men and women (sex feature) are represented in this data set?
2. What is the average age (age feature) of women?
3. What is the percentage of German citizens (native-country feature)?
4. What are the mean and standard deviation of age for those who earn more than 50K per year (salary feature) and those who earn less than 50K per year?
5. Is it true that people who earn more than 50K have at least high school education? (education – Bachelors, Prof-school, Assoc-acdm, Assoc-voc, Masters or Doctorate feature)
6. Display age statistics for each race (race feature) and each gender (sex feature).
7. What is the maximum number of hours a person works per week (hours-per-week feature)? How many people work such a number of hours, and what is the percentage of those who earn a lot (> 50K) among them?
8. Count the average time of work (hours-per-week) for those who earn a little and a lot (salary) for each country (native-country). What will these be for Japan?
To answer these questions, you are provided with a Jupyter notebook with questions. Please complete the notebook with you code to answer the questions. You are encouraged to install Anaconda distribution of Python to run the Jupyter notebook or directly use JupyterLab and accomplish this problem.
Deliverables
This homework comes with a data file adult.data.csv, and a Jupyter notebook. You are asked to:
• Submit a PDF file including the answers for theory problems (1-7) and the answer for EDA questions (a snapshot of your code + final answers) via Gradescope.
• The completed Jupyter notebook for EDA problem via Canvas. Make sure your code is running and include enough details about your code.
2022-02-04