ECN21007 Statistics and Econometrics
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Data Provided: Statistical tables
DEPARTMENT OF ECONOMICS
Statistics and Econometrics
SECTION A
Answer all parts of all questions in this section
1 A collector has a collection of coins with a diameter that is normally distributed with mean equal to 2 cm and standard deviation equal to 0.8928.
(a) Can you find the median? If yes, what is it? In any case, explain. [4 marks]
(b) What is the probability that in the collection there is a coin with a diameter at most equal to 3 cm (round to 2 decimal places)? [6 marks]
2 According to a random survey on drug use, 50% of males have never used marijuana, 20% have used marijuana once, and 30% have used marijuana twice. Based on these data, what is the expected number of times in which males use marijuana for samples of size 100? Explain. [4 marks]
3 Consider the following data in the Table below of automobile accidents in a recent year in a developed country, reporting counts of who survived (Survived) and who died (Died) according to whether they wore a seatbelt (Y=Yes, N=No).
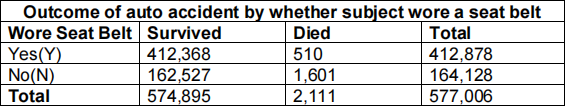
Estimate the probability that an individual did not wear a seatbelt and died (round to 5 decimal places). Explain. [4 marks]
4 For a distribution that has a Mode and that is skewed to the right:
a) Mean>Median>Mode.
b) Mean>Median=Mode.
c) Mean=Median>Mode.
d) Mean<Median=Mode.
e) Mean=Median=Mode.
f) None of the above.
[2 marks]
SECTION B
Answer ONE of the two questions in this section
5 Using a sample of 125 countries, a researcher investigates variation in consumer expenditure on clothing across countries. She obtains the following results.

where the dependent variable is the natural logarithm of a country’s expenditure on clothes in millions of dollars, Ln income is the natural logarithm of a country’s national income in billions of dollars, and Education is the average number of years of education of the population in a country. Americas, Africa and Asia-Oceania are dummy variables for which continent the country is found on.
(a) Provide an interpretation of all estimated coefficients. [7.5 marks]
(b) Perform appropriate tests to determine the statistical significance of each estimated coefficient individually. [7.5 marks]
(c) A good that is a necessity has an income elasticity of demand less than 1. Test whether clothing is a necessity. [5 marks]
(d) State the Stata command used to create the dependent variable, if the data set contains a variable measuring expenditure on clothing that is called Clothexp. [2 marks]
(e) Looking at the dataset used, you observe that a number of the countries in the data set are European. Explain why the researcher did not include a dummy variable for Europe in her regression. [4 marks]
(f) Explain why the researcher might worry about the existence of heteroskedasticity in these results, explaining what heteroskedasticity means. [6 marks]
(g) Explain what is meant by the term multicollinearity. Why might this regression equation potentially suffer from a problem of multicollinearity, and from the estimated results above does it look as though it was actually a problem? [8 marks]
6. A researcher has a dataset containing data on a sample of working-age individuals from each country in the EU. She wants to investigate factors that influence individuals’ health. She obtains the following results.
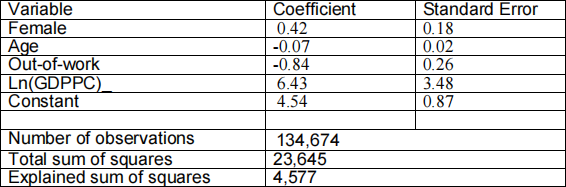
where the dependent variable is the self-reported health of the individual, measured on a scale from 1 to 7, where 7 is the most healthy, Female is a dummy variable indicating women, Age measures the individual’s age in years, Out-of-work is a dummy variable indicating that the individual is not working, and Ln(GDPPC) is the natural log of GDP per capita in the individual’s EU country (she wanted to look at the effect of income on health but her data set did not contain the individual’s own income, so she used this measure of GDP per person at the country level as a proxy for individual income).
(a) Provide an interpretation of all estimated coefficients. [7.5 marks]
(b) Perform appropriate tests to determine the statistical significance of each estimated coefficient individually. [7.5 marks]
(c) Calculate the R2 for this regression. What does the R2 tell you? Are you surprised by the value of R2? Explain your answer. [6 marks]
(d) Provide one likely reason why the standard error on the Ln(GDPPC) variable is relatively high. [4 marks]
(e) Which of the explanatory variables used in the analysis is most likely to be endogenous? Explain your answer. [4 marks]
(f) Why did the researcher not want to exclude income from her equation altogether? Answer this question with reference to the likely effect on the out-of-work coefficient from omitting income altogether from the estimated equation. [7 marks]
(g) Briefly explain the benefits of using a proxy variable (as the researcher does here, using Ln(GDPPC)) as a proxy for income. [4 marks]
2022-01-26