ECE C147/C247, Winter 2026 Neural Networks & Deep Learning Homework #1
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
ECE C147/C247, Winter 2026
Homework #1
Neural Networks & Deep Learning
1. (25 points) Linear algebra refresher.
(a) (12 points) Let Q be a real orthogonal matrix.
i. (3 points) Show that ∥Qx∥2 = ∥x∥2 for all x ∈ R n .
ii. (3 points) Recall that ⟨x, y⟩ denotes the standard Euclidean inner product (dot product) x T y. Show that inner products are preserved under Q, i.e., ⟨Qx, Qy⟩ = ⟨x, y⟩.
iii. (3 points) Suppose λ ∈ C is a complex eigenvalue of Q. Show that its complex conjugate λ is also an eigenvalue of Q.
iv. (3 points) {u1, . . . , uk} ⊂ R n is an orthonormal set if u T i uj = 1 when i = j and 0 otherwise. Show that Q maps orthonormal sets to orthonormal sets.
(b) (8 points) Let A ∈ R m×n be a matrix.
i. (4 points) Show that AT A and AAT are symmetric and positive semidefinite.
ii. (4 points) Explain why AT A and AAT have the same non-zero eigenvalues.
(c) (5 points) True or False. You do not need to justify your answer. For incorrect answers, partial credit may be awarded if you justify your reasoning.
i. Every symmetric matrix A ∈ R n×n has n eigenvectors that are mutually orthogonal and can be scaled to have unit norm.
ii. For matrix B ∈ R n×n , if BT B = 0, then B = 0.
iii. Two matrices with the same eigenvalues must have the same rank.
iv. If x is an eigenvector of the matrix CT C with eigenvalue λ > 0, then Cx = 0.
v. If matrix D is square and invertible, then all its singular values are strictly positive.
2. (25 points) Probability refresher.
(a) (10 points) A machine produces items sequentially. Each item is defective independently with probability p. Items are inspected one at a time, and inspection stops as soon as a defective item is found. (All answers must be in terms of {p, n, k} where applicable).
i. (2 points) What is the probability that inspection stops at the n th item?
ii. (2 points) What is the probability that at least n items are inspected?
iii. (2 points) What is the probability that exactly k non-defective items are inspected before the process stops?
iv. (2 points) Given that inspection stops at the n th item, what is the probability that the first n − 1 items are all non-defective?
v. (2 points) Given that at least n items are inspected, what is the probability that the n th item is defective?
(b) (10 points) A random variable X takes values {−1, +1} with
P(X = +1) = π, P(X = −1) = 1 − π.
The noisy observation is Y = X + N, where N ∼ N (0, σ2 ) is independent of X.
i. (3 points) Write the conditional PDFs fY |X(y | X = +1) and fY |X(y | X = −1).
ii. (4 points) Using Bayes’ rule, express P(X = +1 | Y = y) in terms of π, y, and σ.
iii. (3 points) For a detector that decides X = +1 by observing Y , derive the expression for the equivalent threshold γ ⋆ on Y such that P(X = +1 | Y = y) ≥ 0.5 if and only if y ≥ γ ⋆ . The threshold γ ⋆ must be expressed in terms of π and σ.
(c) (5 points) A deck contains 5 red cards and 5 black cards. Three cards are drawn uniformly at random without replacement. Let Xi = 1 if the i th card drawn is red and Xi = 0 otherwise, for i = 1, 2, 3. Let X = X1 + X2 + X3.
i. (2 points) Compute E[Xi ] for any i.
ii. (2 points) Compute Cov(Xi , Xj ) for i = j.
iii. (1 point) Compute E[X] using linearity of expectation.
3. (10 points) Multivariate derivatives. (Note: You may use results from the matrix cook-book without proof - and therefore several of these questions should be straightforward with no need to show any work).
(a) (1 points) Let x ∈ R n , y ∈ R m, and A ∈ R n×m. What is ∇xx T Ay?
(b) (1 points) Let x ∈ R n , y ∈ R m, and A ∈ R n×m. What is ∇yx T Ay?
(c) (1 points) Let x ∈ R n , y ∈ R m, and A ∈ R n×m. What is ∇Ax T Ay?
(d) (1 points) Let x ∈ R n , A ∈ R n×n , and let f = x T Ax + b T x. What is ∇xf?
(e) (1 points) Let A ∈ R n×n , B ∈ R n×n and f = tr(AB). What is ∇Af?
(f) (2 points) Let A ∈ R n×n , B ∈ R n×n and f = tr(BA + AT B + A2B). What is ∇Af?
(g) (3 points) Let A ∈ R n×n , B ∈ R n×n and f = ∥A + λB∥ 2 F . What is ∇Af?
4. (10 points) Deriving least-squares with matrix derivatives.
In least-squares, we seek to estimate some multivariate output y via the model
yˆ = Wx
In the training set we’re given paired data examples (x (i) , y (i) ) from i = 1, . . . , n. Least-squares is the following quadratic optimization problem:
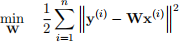
Derive the optimal W.
Where W is a matrix, and for each example in the training set, both x (i) and y (i) ∀i = 1, . . . , n are vectors.
Hint: you may find the following derivatives useful:
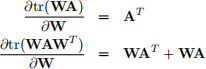
5. (10 points) Regularized least squares
In lecture, we worked through the following least squares problem
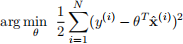
However, the least squares has a tendency to overfit the training data. One common technique used to address the overfitting problem is regularization. In this problem, we work through one of the regularization techniques namely ridge regularization which is also known as the regularized least squares problem. In the regularized least squares we solve the following optimization problem
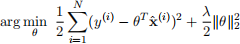
where λ is a tunable regularization parameter. From the above cost function it can be observed that we are seeking least squares solution with a smaller 2-norm. Derive the solution to the regularized least squares problem, i.e Find θ ∗ .
6. (20 points) Linear regression.
Complete the Jupyter notebook linear regression.ipynb. Print out the Jupyter notebook as a PDF and submit it to Gradescope.
2026-01-21