POLS0013: Measurement in Data Science Assessment Part II - ‘Coursework’ 2025-2026
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Assessment Part II - ‘Coursework,
2025-2026
POLS0013: Measurement in Data Science
Instructions
• Part 2 of the assessment on POLS0013 is due on Monday 12th January 2026 at 2pm. Please follow all designated SPP submission guidelines for online submission as detailed on the POLS0013 Moodle page. Standard late submission penalties apply.
• It should be submitted via the ‘POLS0013 Assessment 2- 1500 word coursework (45%)’ links on the course Moodle page. You will need to click the ‘Add submission’. The ‘Submission Title’ should be your candidate number, and you should upload your document into the box provided.
— Please remember to state ONLY your candidate number on your coursework (your candidate number is made up of four letters and one number e.g. ABCD5). Your name and/or student number MUST NOT appear on your coursework.
• This is an assessed piece of coursework for the POLS0013 module; collaboration and/or discussion of the coursework with anyone is strictly prohibited. The rules for academic misconduct apply and any cases of suspected plagiarism of published work or the work of classmates will be taken seriously.
• As this is an assessed piece of work, you may not email/ask the course tutors questions about the coursework. You also must not post questions about answering this assignment, or your code, on the Moodle forum.
• Along with the instructions themselves, the dataset for the ‘coursework’-component can be found in the POLS0013 page on Moodle in the folder “Data for Coursework”.
• The word count for this part of the assessment is 1500 words. There are no allowances above this hard limit This does not include your R script appendix, figures or tables.
— When answering, do not include the question text in your submission, as these would go towards your word count.
— Remember to state your word count on the essay title page. If not included, the turnitin word count (which counts R code) will be used to decide on word penalties.
• Please submit your type-written (numbered) answers in the style of the seminar tasks, but do not include any R-code or raw R output. Answers should be written in complete sentences. Be sure to answer all parts of the questions posed and interpret the results.
• Create an appendix section at the end which contains all the R code needed to reproduce your results. Failure to include the R code will incur a 10 point penalty. Note that your R script file should be neatly presented and easy to follow, including comments indicating the question being addressed.
— Do not include all the code you tried, or that you corrected afterwards: only the code relevant to the answers provided should be included and clearly annotated and structured.
• Round all numbers to at least three digits after the decimal point.
• Assign every table and figure a title and a number and refer to the number in the text when discussing a specific figure or table. Figures and tables should be placed close to where they are mentioned in the text, not in the appendix.
• Together, the questions are worth 90 points. 10 points are reserved for clarity of presentation.
• Some final advice: packages not working is likely due to your R being outdated. It is strongly recommended that you re-download R (and update any packages you plan/have to use) before starting the assessment.
Data Description
You will be working with Wave 20 of the British Election Study that was fielded in June 2020 in England, Scotland and Wales. The data is called bes20 and contains the variables listed in the table below. Further information on the measurement scales for some items is provided after the table. You can load it as follows:
load ( "bes20.rda")
You can use any additional R packages you want, but you will need the following:
# install.packages("ltm")
library (ltm)
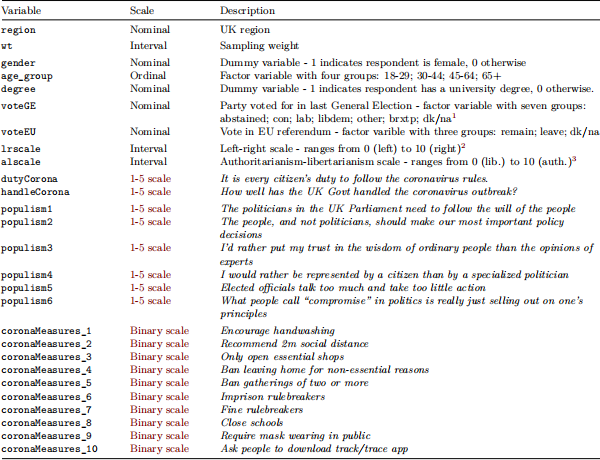
1-5 Scale Nearly all items specified as having a 1-5 response scale have the answer categories 1 = Strongly disagree, 2 = Disagree, 3 = Neither agree nor disagree, 4 = Agree and 5 = Strongly agree. The only exception is variable handleCorona where the answer categories are 1 = Very badly, 2 = Fairly badly, 3 = Neither well nor badly, 4 = Fairly well and 5 = Very well. You should treat all of these as continuous.
Binary scale All items specified as having a binary scale were preceded by the statement “To tackle coronavirus Britain should” and have the answer categories 0 = No and 1 = Yes.
Question 1 - Measuring Populism in the British Population [50 points]
Mudde & Kaltwasser (2013) defined populism as follows:
“Populism is defined as a thin- centred ideology, which is based not only on the Manichean distinction
between ‘the pure people, and ‘the corrupt elite,, but also on the defence of popular sovereignty at any cost. ”
By ‘thin-centered’, they mean that it does not, by itself, imply a particular political leaning and therefore can be ‘attached’ to any kind of other political ideology; left wing, right wing or even centrist for example. According to this definition, populist ideology can be operationalised by the following three dimensions:
a. adherence to a binary view pitting the ‘people’ against the ‘elites’;
b. whether the ‘people’ are seen as inherently more virtuous than the ‘elites’;
c. belief that the legitimate authority to make decisions for the collective lies with the people. Answer the following:
1. Have a look at the question wordings for all of the variables with names starting with populism in the table above. Briefly discuss how these six items may help us to measure the degree to which someone adheres to the ‘populist ideology’. In particular, comment on which, if any, of the three dimensions of populism listed above can these survey items be linked to. Note that you do not need to use or refer to any further academic literature here.
2. Create a subset of the data keeping only those observations with no missing values in any of the six populism variables. Construct an equal weight index, divide the index by a number such that the weights are between 0 and 1, and plot its distribution in a histogram. Describe the measure by answering the following questions:
• What is the range of the measure? What do the maximum and minimum values correspond to, respectively?
• What are the units of the measure?
• What assumptions are made in the construction of the measure?
3. Fit a linear regression (with lm) regressing the equal weight index on dummy variables for each UK region and include a weight=wt argument so that you are using the survey weights. Present the results in a table or figure. Describe how the populism index is distributed across regions.
4. Now fit another linear model with the equal weight index as dependent variable and dummies for party voted for in the last general election (voteGE), dummies for vote in the 2016 EU referendum (voteEU), as well as age_group, gender and degree as independent variables. Again, remember to include the option weights=wt. Present the results in a table and interpret them, considering both substantive and statistical significance. What kinds of respondents report, on average, more or less adherence to a populist ideology, according to our measure?
5. Create another subset including only the populism variables from the already subsetted data you created in 1.2. Calculate and plot the pairwise correlations between all six indicators and comment on what you observe.
6. Use prcomp() to do principal components analysis on the six populism items. Present the coefficients of the first two principal components in a table and try to provide an interpretation for both.
7. Provide a screeplot and report the proportions of variance explained by each principal component. Explain what we learn from this.
8. Create a plot with, on the x-axis, the values from the equal weight index and, on the y-axis, the scores from the first principle component. Use what you see in the plot to discuss which measurement strategy between the two is more useful and/or efficient for measuring people’s adherence to the populist ideology.
Question 2 - Measuring Support for Anti-Corona Measures [40 points]
Answer the following:
1. Create a new subset from bes20, this time only keeping those observations with no missing values in all of the ten coronaMeasures_ items. Calculate, for each of the ten items, the share of respondents who indicated support for the measure. Present these either in a table or plot of your choice. Describe what you observe.
2. We will adopt an unsupervised scale measurement strategy, specifically by estimating an Item Response Theory (IRT) model.
• Briefly explain which family of measures IRT models belong to and what this means for the assumed relationship between target concept and measure.
• Why is IRT, as opposed to Factor Analysis (EFA), an appropriate modelling choice in this case?
• List one similarity and two dissimilarities between IRT and PCA in terms of their implementation and output.
3. Create another subset including only the coronaMeasures_ items with non-missing values as variables. Fit a binary IRT model with one latent factor with the function ltm(). Present the coefficients in a table, where one column should contain all α,s and the other one all β,s. Interpret and compare the values in the table. In particular, focus on the items that have the lowest and highest β and α coefficients.
4. Use factor.scores.ltm() to recover the latent variable estimates and include these as a new variable in the data you created in 2.1. Create an equal weight index by summing up all coronaMeasures_ items. Then, plot the scores on the y-axis against this equal weight index on the x-axis. Add the line of a linear binary model to the plot. Briefly comment on what you see and discuss why this justifies, or not, the use of the latent variable estimates as opposed to a simple equal weight index as our measure.
5. Now, plot the latent variable estimates on the y-axis against the variables handleCorona and dutyCorona on the x-axis, respectively. Once more, add the line of a linear binary model to each plot. Briefly comment on what you see and whether this can help us to interpret what the latent factor scores mean.
6. Fit a linear regression with the latent factor scores as the dependent variable and lrscale and alscale as independent variables. Once more, include weights = wt. Present the model results in a table and interpret them in terms of substantive and statistical significance.
7. Finally, further subset the data created in 2.1 to only include those observations with no missing values in the coronaMeasures_ and populism items. Re-create the equal-weight populism index from Question 1.2. Plot these against the factor scores obtained with the IRT model and add the line of a binary linear regression. What do you make of what you observe?
2025-12-20