ECS708A MACHINE LEARNING 2021
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Winter Examination Period 2021 — January — Semester A
ECS708A MACHINE LEARNING
Question 1
In this question we explore regression in a problem involving two attributes x and y.
The dataset used for training contains four samples and is shown in Table 1. A second dataset containing two samples and shown in Table 2 is used for validation.

In Table 1, D1 , D2 , D3 and D4 represent the last four digits of your student ID (D1 being the last, D2 the second last, etc).
a) Let X be the design matrix obtained from the training dataset shown in Table 1 and
w be the coefficients of the Minimum Mean Squared Error (MMSE) linear solution y = w0 + w1x. Furthermore, assume that
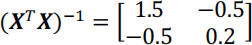
i) Obtain the MMSE coefficients w of the linear model y = w0 + w1x. Show all the steps involved in the calculation of w.
ii) Obtain the Mean Squared Error (MSE) of the linear solution that you have obtained, on both the training and validation sets.
[15 marks]
b) Let us now consider cubic models.
i) We know that the MSE of the cubic model y = - 7 + 10.34x – 2.5x2 + 0.16x3 on the training set shown in Table 1 is MSE < 2. Is this model overfitting?
ii) Assume that the true underlying model is y = 2 + x + n, where n is a sample from a Gaussian distribution with mean 1 and variance 1, and that your training dataset contains 100 samples. What coefficients would you expect to obtain, if you fitted a cubic model to this dataset?
[10 marks]
Question 2
In this question we explore classification in a problem involving two predictor features xA and xB , and two classes, namely ![]() (positive class) and × (negative class). The dataset that will be used in this question is shown in Figure 1.
(positive class) and × (negative class). The dataset that will be used in this question is shown in Figure 1.
a) Consider a family of linear classifiers defined by "!# = 0, where " = [(", (#, ($]! and # = [1, ,#, ,$]! . A sample #% such that "!#% > 0 will be labelled as ![]() , otherwise it will be labelled as × . For the dataset shown in Figure 1:
, otherwise it will be labelled as × . For the dataset shown in Figure 1:
i) Obtain the confusion matrix of the linear classifier defined by " = [2, 0, 1]! .
ii) Given the linear classifier defined by " = [(" , 0, 1]! , where you can calibrate the value (" , what value would you choose for (" if you are required to obtain the maximum specificity for a minimum sensitivity of 0.75?
b) Consider a Bayesian classifier trained on the dataset shown in Figure 1.
i) Would the boundary defined by this classifier be linear?
ii) We want to use this Bayesian classifier to label a set of samples with the same distribution as the samples in Figure 1 but different priors, specifically the prior P(![]() ) = 0.1. How would you modify the Bayesian classifier to use it on this set?
) = 0.1. How would you modify the Bayesian classifier to use it on this set?
[10 marks]
Question 3
In this question we explore clustering. The dataset that we will use in this question is shown in Figure 2.
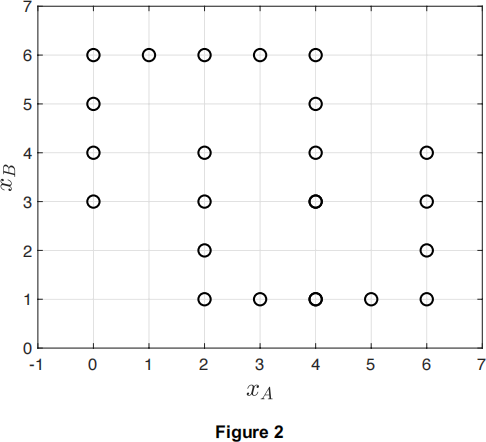
a) Consider the k-means algorithm, where k = 2. The prototypes of the first and second clusters will be denoted by C1 = (xA1 , xB1) and C2 = (xA2 , xB2), respectively.
(i) Consider two clustering arrangements. In the first arrangement C1 = (1, 5) and C2 = (3, 2). In the second one C1 = (3, 5) and C2 = (5, 2). According to the notion of clustering quality in k-means, which arrangement is better?
(ii) If the initial prototypes are C1 = (3, 100) and C2 = (3, 101), what will be the final solution provided by k-means? How many iterations will it take to reach this solution?
(iii) If the initial prototypes are C1 = (3, 100) and C2 = (3, -100), where will the prototypes be after the first iteration of k-means?
[15 marks]
b) Consider the DBSCAN algorithm, where r is the radius and t the threshold. Assume that the threshold value is set to t = 1.
(i) Describe the solutions provided by DBSCAN for r = 0.5, r = 1.5 and r = 2.5. (ii) You are asked to compare the solutions provided by k-means and DBSCAN
using the intra-cluster sample scatter as a quality metric. Would you agree with this approach?
[10 marks]
Question 4
This question concerns neural networks. Consider a dataset consisting of RGB images of size 20 x 20 pixels and a multi-class label that can take on 4 different values. Labels are encoded using one-hot encoding, so that each label is represented by the values [1,0,0,0], [0,1,0,0], [0,0,1,0] and [0,0,0,1], respectively.
a) The first architecture that we will explore is one consisting of just one single fully- connected layer.
i) Use a diagram to describe this architecture.
ii) Determine the number of parameters to be trained.
iii) Is a dataset consisting of 1000 images appropriate to train this network, or would you expect the network to either underfit or overfit?
[15 marks]
b) The second architecture is a convolutional neural network.
i) The first hidden layer is a convolutional layer defined by 10 filters of dimensions 3 x 3 x D. Determine D and the number of feature maps produced by the first layer.
ii) Assuming that each feature map in the first hidden layer has dimensions 20 x
20 and the second layer is a 2 x 2 max-pooling layer, determine the number of feature maps in the second layer and their dimensions.
[10 marks]
2022-01-13