MSCI212: STATISTICAL METHODS FOR BUSINESS 2
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
DEPARTMENT OF MANAGEMENT SCIENCE
MSCI212: STATISTICAL METHODS FOR BUSINESS
Task 2

NB: I asked for skewness as an extra, using the [options] button.
Histograms:
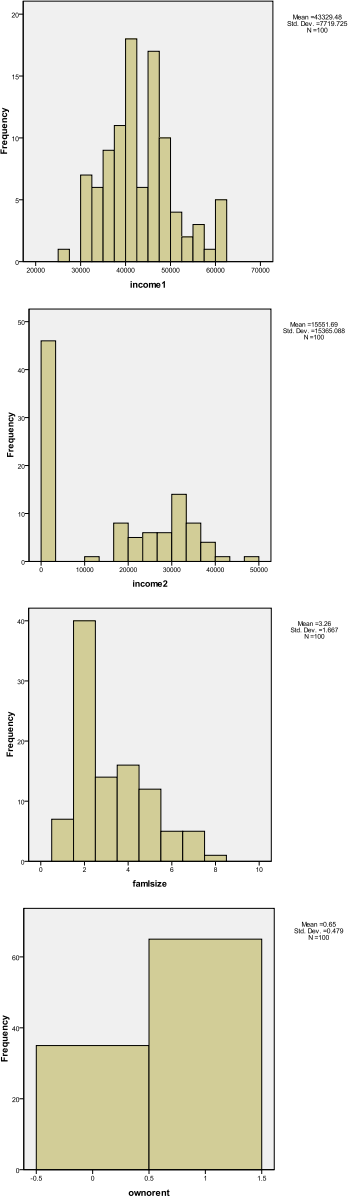
Did you notice that:
![]() The first three distributions are all skewed to the right.
The first three distributions are all skewed to the right.
![]() Approximately 2/3 of families own their accommodation.
Approximately 2/3 of families own their accommodation.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() The distribution of INCOME2 is unusual as it has a large number of zero values – why?
The distribution of INCOME2 is unusual as it has a large number of zero values – why?
![]() Also, not surprisingly, the distribution of INCOME2 is ‘generally located’ to the left of that of INCOME1. In fact, if you look closely at the data, INCOME2 < INCOME1 for every single family – why?
Also, not surprisingly, the distribution of INCOME2 is ‘generally located’ to the left of that of INCOME1. In fact, if you look closely at the data, INCOME2 < INCOME1 for every single family – why?
Task 3
In this case relationships can be best investigated using Scatterplots and/or Boxplots. Which do you think are most effective for this case?
If you select ‘Matrix Scatter’ rather than ‘Simple Scatter’ in the dialog box below (obtained when using <Graphs><Legacy Dialogs><Scatter/Dot> …

…. you will be able to see all the scatterplots and once and decide which are interesting to look at more closely.

This suggests potentially interesting Boxplots, such as:![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
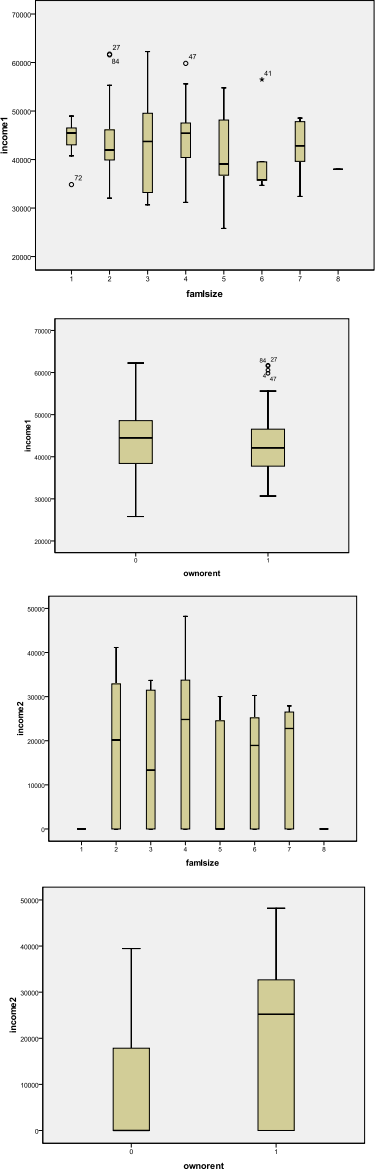
The most noteworthy relationship in my sample is between Income 2 and ownership, with bigger levels of Income2 being associated with owning accommodation. Also, obviously (why?) Income2 seems always to be zero for the smallest family size. You may spot other apparent patterns in your data. Do you think they are real patterns or just chance patterns occurring in your sample but not in others?
Task 4
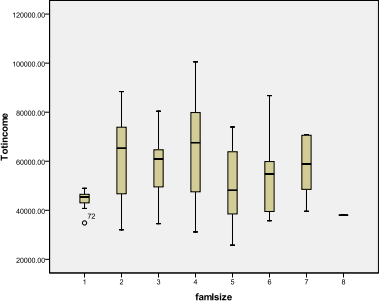
In my sample, Total income seems to be higher for family sizes 2-4 than for sizes 5+. Is it true for your sample? If so, can you think of an explanation why?
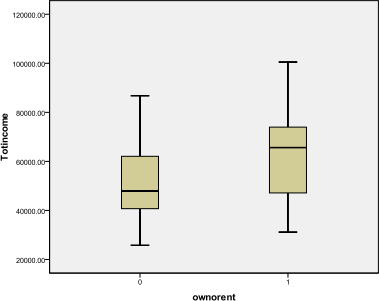
Total Income is also related to ownership, not surprising given the strong relationship with Income2.
Task 5
In practice you would expect/guess (INFER) that the ‘strong’ patterns, particularly those that seemed to be understandable, were also likely to be true of the full dataset (e.g., skewed distributions, relationship between INCOME1 and INCOME2, Family size = 4 has biggest total income, etc). Whereas ‘weaker’ patterns, particularly if not understandable patterns, were less likely to be true of the full dataset, e.g., family size = 6 has the second biggest income, family size = 3 has the third biggest income, etc.
In this case you can obviously check how good you are at inferring by comparing your results with other people’s. You could even examine the full population of 1140 households by going back to the original data file.
2022-01-04