Homework 4 Multiple Regression with Interactions
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Homework 4
Multiple Regression with Interactions
Due on 4/10/2025
Background of the Data Set
Human overpopulation is a growing concern and has been associated with depletion of Earth’s natural resources and degradation of the environment. This, in turn, has social and economic consequences such as global tension over resources such as water and food, higher cost of living and higher unemployment rates. The data in `fertility.sav` were collected from several sources (e.g., World Bank) and are thought to correlate with fertility rates, a measure directly linked to population. The variables are:
· country: Country name
· region: Region of the world
· fertility_rate: Average number of children that would be born to a woman if she were to live to the end of her childbearing years and bear children in accordance with age-specific fertility rates.
· educ_female: Average number of years of formal education (schooling) for females
· infant_mortality: Number of infants dying before reaching one year of age, per 1,000 live births in a given year.
· contraceptive: Percentage of women who are practicing, or whose sexual partners are practicing, any form of contraception. It is usually measured for women ages 15–49 who are married or in union.
· gni_class: Categorization based on country’s gross national income per capita (calculated using the World Bank Atlas method)
- Low: Low-income economies; GNI per capita of $1,025 or less;
- Low/Middle: Lower-middle-income economies; GNI per capita between $1,026 and $3,995;
- Upper/Middle: Upper middle-income economies; GNI per capita between $3,996 and $12,375;
- Upper: High-income economies; GNI per capita of $12,376 or more.
· high_gni: Dummy variable indicating if the country is has an upper-middle or high income economy (low- or low/middle-income = 0; upper/middle or upper income = 1)
In this homework, we would like to understand whether formal education for females (educ_female) and country’s gross national income per capita (gni_class) have significant effects on fertility rate (fertility_rate). Specifically, we want to construct three models:
Model 1: continuous explanatory covariate only (educ_female)
Model 2: continuous and categorical explanatory covariates (educ_female + gni_class)
Model 3: continuous, categorical explanatory covariates, and their interactions (educ_female + gni_class + educ_female*gni_class)
Section 1: Canvas Online Submission
In this section, we will focus on testing the three models and selecting the best model.
1. The following is the ANOVA output of the three models:
|
ANOVAa |
||||||
|
Model |
Sum of Squares |
df |
Mean Square |
F |
Sig. |
|
|
1 |
Regression |
140.906 |
1 |
140.906 |
180.293 |
<.001b |
|
Residual |
95.348 |
122 |
.782 |
|
|
|
|
Total |
236.254 |
123 |
|
|
|
|
|
2 |
Regression |
163.237 |
3 |
54.412 |
89.425 |
<.001c |
|
Residual |
73.016 |
120 |
.608 |
|
|
|
|
Total |
236.254 |
123 |
|
|
|
|
|
3 |
Regression |
165.757 |
5 |
33.151 |
55.489 |
<.001d |
|
Residual |
70.497 |
118 |
.597 |
|
|
|
|
Total |
236.254 |
123 |
|
|
|
|
|
a. Dependent Variable: fertility_rate |
||||||
|
b. Predictors: (Constant), educ_female |
||||||
|
c. Predictors: (Constant), educ_female, gni_3class=Middle, gni_3class=Upper |
||||||
|
d. Predictors: (Constant), educ_female, gni_3class=Middle, gni_3class=Upper, edu_gni_mid, edu_gni_upper |
||||||
Based on the output, which of the following interpretations is correct?
a) All the three models are significant because all the p-values are less than 0.05.
b) Model 3 is the best because it is more complex than the other models.
c) Model 1 is the best because it only contains a continuous covariate.
2. To test whether the interaction between `educ_female` and `gni_3class` has a significant effect, the null hypothesis is
a) H0: δ1 = 0
b) H0: δ2 = 0
c) H0: δ1 = δ2 = 0
d) H0: γ1 = γ2 = δ1 = δ2 = 0
3. The following is the Model Summary output:
|
Model Summary |
|||||||||
|
Model |
R |
R Square |
Adjusted R Square |
Std. Error of the Estimate |
Change Statistics |
||||
|
R Square Change |
F Change |
df1 |
df2 |
Sig. F Change |
|||||
|
1 |
.772a |
.596 |
.593 |
.88405 |
.596 |
180.293 |
1 |
122 |
<.001 |
|
2 |
.831b |
.691 |
.683 |
.78005 |
.095 |
18.350 |
2 |
120 |
<.001 |
|
3 |
.838c |
.702 |
.689 |
.77294 |
.011 |
2.108 |
2 |
118 |
.126 |
|
a. Predictors: (Constant), educ_female |
|||||||||
|
b. Predictors: (Constant), educ_female, gni_3class=Middle, gni_3class=Upper |
|||||||||
|
c. Predictors: (Constant), educ_female, gni_3class=Middle, gni_3class=Upper, edu_gni_mid, edu_gni_upper |
|||||||||
Which of the following statements is correct based on the output?
a) It cannot be concluded that Model 2 is significantly better than Model 1.
b) The best model is Model 2 because Model 3 is not significantly better than Model 2 but Model 2 is significantly better than Model 1.
c) The best model is Model 3 because it has the largest R2.
4. Which of the following conclusions about the test result shown in the last question is correct?
a) The model with interaction terms significantly improves the model fit.
b) It is necessary to model the three groups of `gni_3class` with different slopes.
c) It is necessary to model the three groups of `gni_3class` with different intercepts.
d) It is not necessary to form separate regression models for different groups of `gni_3class`.
Section 2 : SPSS (Upload)
In this section, we only focus on Model 3. For each of the following questions, report the relevant output and answer the questions.
Recall that Model 3 includes a continuous variable (`educ_female`), a categorical variable (`gni_class`), and their interaction.
1. Before we analyze the data, we would like to reduce the number of levels for `gni_class` from 4 to 3. Specifically, we would like to merge the levels, Low/Middle and Upper/Middle, to a new level called “Middle”. Please name the new variable as `gni_3class`. Take a screenshot of your updated data set after the new variable is created and paste it here.
2. Next, create the dummy variables for `gni_3class` and paste a screenshot here.
3. Finally, create the interaction terms for `educ_female*gni_3class` and paste a screenshot here.
Let’s set `gni_3class = Low` as the reference group. Model 3 can then be written as
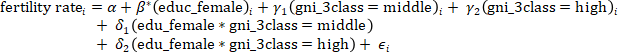
4. Fit the data with Model 3 and write down the estimated model.
5. Write the individual model for each of the three `gni_3class` groups.
6. Interpret the following estimates:
a. The estimated intercept
b. The estimated slope associated with `educ_female`,
c. The estimated slope associated with `gni_3class = Middle`
d. The estimated slope associated with `educ_female* gni_3class = Upper`.
7. Test the significance of δ1. State the hypotheses, report the test statistic and the p-value, and interpret the result.
8. Conduct the omnibus test. State the hypotheses, report the test statistic and the p-value, and interpret the result.
2025-04-17