MTH6102: Bayesian Statistical Methods 2020
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
MTH6102 (2020)
MTH6102: Bayesian Statistical Methods
Question 1 [12 marks].
A box contains m = 5 balls, of which r are red and the rest black. The unknown quantity is r.
|
Our prior distribution is that each value r = 0, 1, . . . , m has equal probability. We are told that twice, a ball was taken out and immediately replaced, and both times the ball was red. (a) Write down the likelihood for the observed data. What is the maximum likelihood estimate for r? (b) Derive the normalized posterior distribution for r. What is the posterior mean for r? (c) Find the posterior predictive probability that if another ball is taken from the box, it is black. |
[4] [5] [3] |
Question 2 [34 marks].
A biased coin with probability q of landing heads is repeatedly tossed until the first head is seen. The number of tails X before the first head is modelled as a geometric distribution with probability mass function P(X = x) = q(1 - q) . The experiment was repeatedx n times and x1 , x2 , . . . , xn tails were observed.
(a) Write down the likelihood for q. Show that the maximum likelihood estimate for q is
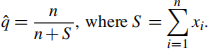
(b) Find the Fisher information and hence the asymptotic variance for ![]() .
.
(c) A Beta(α0 ,80 ) distribution is chosen as the prior distribution for q. Show that the posterior distribution is Beta(α1 ,81 ), where you should determine α 1 and 81 .
(d) We have n = 5 and observed data x1 , . . . , xn = 4, 2, 5, 6, 3.
(i) What is the maximum likelihood estimate ![]() ? (ii) Find an approximate 95% confidence interval for q.
? (ii) Find an approximate 95% confidence interval for q.
[6] [5] [6]
[3] [4]
(iii) Before seeing the data, our probability distribution for q has mean 0.4 and standard deviation 0.2. Find values of α0 and 80 corresponding to this belief. What
is then the posterior distribution for q? What is the posterior mean?
(iv) Comment on the posterior mean compared to the maximum likelihood estimate
and the prior mean for this example. No further calculations or formulae are needed here.
[8]
[2]
Question 3 [26 marks].
We want to estimate a single unknown parameter 9 in a certain model. Assume that in R we have defined a function log post to calculate the log of the unnormalized posterior density as a function of 9. This function and the data y being analysed are not shown in the code extract below. The posterior density is p(9 | y). Consider the following R code:
nb = 1000
nm = 10000
theta = vector(length=nm)
s = 0.4
theta0 = 2
log post0 = log post(theta0)
for(i in 1:(nb+nm)){
theta1 = rnorm(1, mean=theta0, sd=s)
log post1 = log post(theta1)
if(log(runif(1)) < log post1-log post0){
theta0 = theta1
log post0 = log post1
}
if(i>nb) theta[i-nb] = theta0
}
stheta = sort(theta)
stheta[nm/2]
stheta[nm*0.025]
stheta[nm*0.975]
Except where stated, an explanation in words is all that is needed for this question.
|
(a) What is the name of the algorithm that the code is carrying out? (b) Explain what the command theta1 = rnorm(1, mean=theta0, sd=s) is doing in the context of the algorithm. |
[3] [4] |
(c) Explain what the command if(log(runif(1)) < log post1-log post0) is doing in the context of the algorithm. In your answer, include a formula involving p(9 | y) that
|
the code is implementing. (d) What are the efects on the behaviour of the algorithm of making the variable called s smaller? What are the efects of making it larger? (e) What is the purpose of the variable called nb? (f) When the code has run, what will the vector theta contain? (g) In statistical terms, what will the command stheta[nm/2] output? (h) In statistical terms, what will the last two lines of code output? |
[5]
[4] [2] [2] [2] </ |
2021-12-25