INFR11140 IMAGE AND VISION COMPUTING
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
INFR11140 IMAGE AND VISION COMPUTING
1. THIS QUESTION IS COMPULSORY
Short answer questions. Each question is worth 2.5 marks.
(a) Describe briefly what are vanishing points and vanishing lines in an image. Use a diagram to illustrate your answer.
(b) What linear transformation matrix will rotate an image by 45 degrees?
(c) Consider the binary image A which is convolved with unknown filter F to produce image B = F * A. What filter F was used?

(d) The mean-shift clustering algorithm appears to free the user from the re- sponsibility of choosing the number of clusters. However, this is misleading. Why?
(e) You are designing a vision system for automated maintenance inspection of jet engines for faults that could lead to engine failure. It’s crucial that the system warns maintenance engineers of potential faults to avoid plane crashes. Which of the following is the most appropriate evaluation metric for this system: Accuracy, Precision, Recall, Loss value? Explain your choice.
(f) Explain the process of early stopping in neural network learning, and what it is designed to achieve.
(g) Outline the notion of Bayes error vs Human error for an image recognition problem. How do they relate and how could you estimate each?
(h) Explain the role of interest point detectors vs descriptors in computer vision pipelines.
(i) Why do we need non-max suppression in object detection systems? Illus- trate with a diagram.
(j) Outline the role of transfer learning in CNN-based computer vision, and some hyper-parameters that may need to be tuned to use it effectively.
2. ANSWER EITHER THIS QUESTION OR QUESTION 3
This question is about image formation and low-level vision.
(a) With reference to this schematic of image formation:
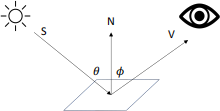
i. Explain the concepts of (1) surface albedo, (2) diffuse (aka Lambertian) reflection, (3) specular reflection.
ii. For diffuse reflection, which viewing and incidence angles leads to max- imum perceived brightness?
iii. For specular reflection, which viewing and incidence angles leads to
maximum perceived brightness?
(b) Consider the 1D image A:
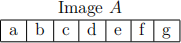
i. Consider applying a width-3 mean filter F twice to image A, where a, . . . , g are variables representing pixel values. Specifically, apply the filter once to produce a smoothed image B = F * A, and then re-apply
the same mean filter again C = F * B. Give an expression for the value of the center pixel of the output image C where mean filter has been applied twice.
ii. Derive a single 1D filter that, when applied once to the image, will produce the same result as applying the above mean filter twice.
(c) Elementary edge detection filters such as 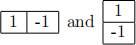 can be used
can be used
to detect vertical and horizontal edges respectively by approximating the gradients 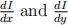 respectively of image I with respect to x and y position. i. Such finite different estimates of image gradient are susceptible to noise in the image. How can we increase robustness to noise in edge detection?
respectively of image I with respect to x and y position. i. Such finite different estimates of image gradient are susceptible to noise in the image. How can we increase robustness to noise in edge detection?
ii. Suppose we want to detect 45 degree diagonally oriented edges. Outline one approach to this that make use of the above operators, and one that does not.
iii. Show that edge detection (and hence operations that depend on edge de- tectors such as Harris) is invariant to additive global brightness changes.
(d) You are using the hough transform algorithm to detect and fit multiple lines in a single image given its edge map as an input. You observe several chal- lenges including inaccurate line fitting (position and orientation estimation), false positive lines returned due to noise in the image, and slow runtime.
i. What parameters of the hough transform can affect these properties of the algorithm?
ii. How might you tune these parameters to solve these problems?
iii. Which tradeoffs may arise in simultaneously solving these problems?
3. ANSWER EITHER THIS QUESTION OR QUESTION 2
This question is about high-level vision and convolutional neural networks.
(a) Consider a convolutional neural network (CNN) with 2 consecutive 5 × 5 convolutional layers, each with stride 1. Answer the following questions numerically as well as with a sketch illustrating your reasoning.
i. How large is the receptive field of a neuron in the 2nd non-image layer of this network?
ii. How large is the receptive field of a neuron in the 2nd non-image con- volutional layer if we now insert a 2 × 2 max pooling between the two convolutional layers?
iii. How large is the receptive field of a neuron in the 2nd non-image con- volutional layer if we now modify the second convolutional layer to use stride 2?
(b) Consider a neural network for recognizing digits [0, ..., 9] that processes 100 × 100 RGB input images, with a 5 × 5 convolutional layers of stride 2 with 16 filters, followed gby lobal max pooling and a fully connected layer. Ignoring, or assuming ‘same’ padding:
i. approximately how many operations (multiplications+additions) are used by the convolutional layer?
ii. approximately how many operations (multiplications+additions) are used by the FC layer?
(c) Suppose you are training a neural network to recognize letters [a, ..., z]. Your neural network uses a softmax output, cross-entropy loss, and 1-hot encoded labels y. Recall that cross entropy loss is defined as L(y, ![]() ) = _y . log(
) = _y . log(![]() ).
).
i. You initialize your weights to mean 0, standard deviation 1e −6 , but accidentally set your learning rate to zero. What predictions ![]() do you expect your network to make after the first epoch? What do you expect your average loss to be after the first epoch?
do you expect your network to make after the first epoch? What do you expect your average loss to be after the first epoch?
ii. After correcting your learning rate bug and training the model, it now converges and predicts ![]() = [0.1, 0.5, 0.4, 0, . . .] on a validation image, whose true label is y = [0, 0, 1, 0, 0, . . .]. What is the loss value for this image?
= [0.1, 0.5, 0.4, 0, . . .] on a validation image, whose true label is y = [0, 0, 1, 0, 0, . . .]. What is the loss value for this image?
iii. Later on, you want to upgrade your system to allow multiple letters to be detected in a single input image. You switch to using multi-hot labels so that, for example y = [1, 0, 1, 0, 0, . . .] would mean that both a and c are present. To save time you reuse the previous architecture and loss and retrain. Why is this problematic? What could you change to solve this problem?
(d) Suppose you are training a neural network to recognize different vegetables for a grocery sorting system
i. Before starting, you have to decide the image resolution to use for data collection. What does this impact? How might you decide the minimum acceptable resolution to use?
ii. You request a dataset of 10,000 carrot and tomato images from the sorting factory. You start prototyping by training a CNN on a small set of 100 images. Training converges, but the training loss is high. A colleagues suggests to solve this by using the full training set size of 10,000 images. Is this approach likely to help? Describe the likely outcome of training with 10,000 images.
iii. Later you manually inspect the data and find that you were given 9990 carrot images and only 10 tomato images. What is likely to happen when training on this data? How can you solve this?
iv. You also discover that your initial train and validation splits were made by splitting the data in its original order, which followed time of collec- tion. The train data is well lit daytime data, and your validation data is poorly lit evening data. What will this do? How can you solve it?
2021-12-24