Intelligent Systems (CMPUT 366)
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Computing Science Department
CMPUT 366 - Fall 2021
Problem Set
Unit 2 - Learners
Intelligent Systems (CMPUT 366)
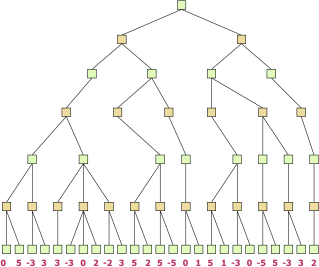
1. Consider the trees below representing zero-sum two-player games. Write the values of x that allow Minimax search with Alpha Beta pruning to prune the dashed nodes. You should write the word ‘None’ if no value of x allows the nodes to be pruned. You should assume that the search algorithm visits the children from left to right.

2. The tree below represents a zero-sum two-player game where the green nodes (root of the tree) are max’s nodes and yellow nodes are min’s nodes. Assuming a left-to-right ordering of visit, prune the branches that Alpha Beta pruning would prune. This example created by Ariel Felner.
3. Consider the following training set of a regression problem, where given a value of x one wants to predict the value of y with the hypothesis hw (x) = wx + b.
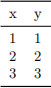
a) Given that w = b = 0 and α = 0.1, what are the values of w and b after the first iteration of gradient descent?
b) For α = 0.1 the algorithms takes approximately 300 iterations to converge to values of w and b for which further gradient updates will not decrease the Mean Squared Error of the model. What happens if we reduce the value of α to 0.01. Do you think it will converge with more or fewer iterations than when α = 0.1? What is the difference between the solution encountered with α = 0.1 and with α = 0.01?
c) Linear regression learns a linear function of the input values x. Explain two ways we could learn a non-linear function of the input values.
4. Consider the classification problem given by the training data below. In this problem we are trying to classify images of dogs while considering only three binary features: ears, fur, and hat. The column y gives the labels: 0 for an image without a dob and 1 for an image with a dog. For example, the first image contains no ears, fur, nor hat and it is labelled as ‘not dog,’ while the last image in the data set contains ears, fur, and hat and it is labelled as ‘dog’. Considering the training set below, answer the following questions.

a) Is this problem linearly separable? Justify your answer.
b) What if we modify the training so that [1, 1, 0] has the label of 1 instead of 0 and [1, 1, 1] has the label of 0 instead of 1, is the problem linearly separable?
c) How many hidden layers does a neural network need for solving the problem given by the data set above where the instance [1, 1, 0] has the label of 1 instead of 0 and [1, 1, 1] has the label of 0 instead of 1.
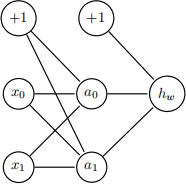
5. Consider the XOR problem shown in the table below. One of your classmates is trying to train a neural network to learn the mapping of x0 and x1 values to the labels in the training data.
Your classmate told you that their model is unable to learn the correct mapping from the input values to the output values. Suspecting they were using a model with no hidden layers, you asked them to
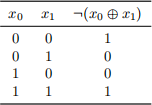
draw the model they have implemented. Your classmate then draws the following model on the back of a napkin and they mention that they initialize all weights of the model with the value of zero. Suddenly you understand why their model is unable to learn the XOR function. Explain to your classmate why the weights can’t be initialized with the same value.
6. Jorge, the capybara, needs your help to compute the Q(s, a) values for the problem below. Jorge starts in position (1, 1) (see the figure below). The states with a dashed squared and with the letter G have only the action “Out” available. All other states have the actions up (U), down (D), left (L), and right (R) available. Once Jorge applies the “Out” action it goes to a terminal state in the Markov decision process.
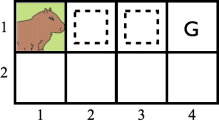
The table shows the experiences Jorge has collected by following an ∈-greedy policy. Assuming that Q(s, a) = 0 for all s and a, γ = 1 and α = 0.5, what are the values of Q(s, a) after processing the experience shown in the table below with Q-Learning.
7. Sarsa is an on-policy algorithm that employs an ∈-greedy policy to gather experience by interacting with the environment. Sarsa then learns an optimal ∈-greedy policy by interacting with the environment.
If the value of ∈ decreases over time and eventually converges to ∈ = 0, then Sarsa is able to learn

an optimal policy for the problem. Q-Learning also uses an ∈-greedy policy to gather experience by interacting with the environment. However, instead of learning an ∈-greedy policy, Q-Learning learns a greedy policy directly. What are the negative effects if Q-Learning also employed a greedy policy to drive its behavior while interacting with the environment?
2021-12-24