COMP5338 Advanced Data Models
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP5338 Advanced Data Models Main Exam Script Semester 2, 2021
Question 1 Short Answer Questions (30 points)
1. [4 points] MongoDB sharding is achieved using two types of external services: a number of configure servers deployed as replica set and a number of Mongos routing processes deployed on various client machines. Describe the benefits ofthis approach.
2. [6 points] All data models need to handle array typed data; Describe how array is handled in MongoDB, Neo4j and in Bigtable.
3. [4 points] Describe how LSM principle is used in Bigtable.
4. [6 points] Name two database systems that support hash partition and describe how hash partitioned is implemented these two systems.
5. [4 points] Write a GeoJSON object representing a rectangle with a rectangular hole inside it. You should make reasonable assumptions on the location and the size of both rectangles.
6. [6 points] Nearest neighbor query is a common spatial query supported by many spatial database management systems and by most spatial indexing structure. Use your own words describe how nearest neighbor query can be supported by grid file and R-tree index. Highlight any similarities in the two approaches.
Question 2 MongoDB Queries, Indexing and Read/Write Concern (25 points)
All parts of this question are related to a MongoDB database with two collections: tweets and users. The tweets collection contains tweet object similar to the data set we have used in labs and in assignments. The question only involves two types of tweet: a general tweet and a retweet. The following are two example tweet objects representing general tweet and retweets respectively. For
simplicity, we omit the _id field
A general tweet object:
{
"id": 1308517931341484032,
"created_at": ISODate("2021-09-22 21:26:00"),
"user_id": 28949616,
}
A retweet object:
{
"id": 1308517931341489067,
"created_at": ISODate("2021-09-23 12:05:43"),
"user_id": 127946336,
"retweet_id": 1308517931341484032,
"retweet_user_id": 28949616,
}
The users collection contains user object. A user object has an id, name and created_at time. Most users follow many other users. The user ids they follow are stored in an array field called following. Below is an example user document. The _id field is omitted.
{
"id": 28949616,
"name": "Nobody",
"created_at": ISODate("2001-03-13 19:33:30"),
"following": [1964768, 62370835, … ]
}
1. [4 points] Write a query to find all retweets a tweet with id 123 created before “2021-10- 13 19:33:30”, sort the retweets by creation time ascendingly.
2. [8 points] For a given tweet with id 123, write a query/aggregation to find the number of retweets made by the tweet user’s follower.
3. [5 points] Assume the following indexes have been created:
db.tweets.createIndex({retweet_id:1, created_at:-1})
db.tweets.createdIdex({id:1})
db.users.createIndex({id:1})
Analyse the index usage ofyour queries in part 1 and part2.
4. [8 points] Assume the collections are stored in a replica set with 3 members. A tweet with id: 123 has 20 retweet_count. The database receives a command to update the retweet_count to 21. The update was completed at t0 on primary; it was completed at t1 in secondary 1; primary receives the acknowledgement from primary 1 at t2; the update was completed at t3 in secondary 2; secondary 1 receives the notification to update its majority agreed copy at t4; secondary 2 receives the notification to update its majority agreed copy at t5; Describe in detail what would return under the following conditions:
a. Read against primary with read concern set to “majority” and the read happens between t1 and t2;
b. Read against primary with read concern set to “local” and the read happens between t1 and t2;
c. Read against secondary with read concern set to “majority” and the read happens in secondary 1 between t3 and t4
d. Read against secondary with read concern set to “local” and the read happens on secondary 2 between t3 and t4
Question 3 Neo4j Data Modeling and Query (25 points)
All parts of this question are related with a graph representing units offered in a university and their prohibited and prerequisite relationships. A sample graph is show in Figure 1. Each node in the graph represents a unit. They all have the same label: Unit. A unit can have PROHIBITED or PREREQUISITE relationship with other nodes. Both types ofrelationships have directions. The graph shows that INFO1110 is the prerequisite of COMP2123 and INFO1905 is prohibited with COMP2123. Most units in the graph have the following properties: code (which is shown in the graph), title and semesters. Below is an example of the properties of a unit with code “INFO1110”:
{ "code": "INFO1110",
"title": "Introduction to Programming",
"semesters": ["S1","S2"]
}
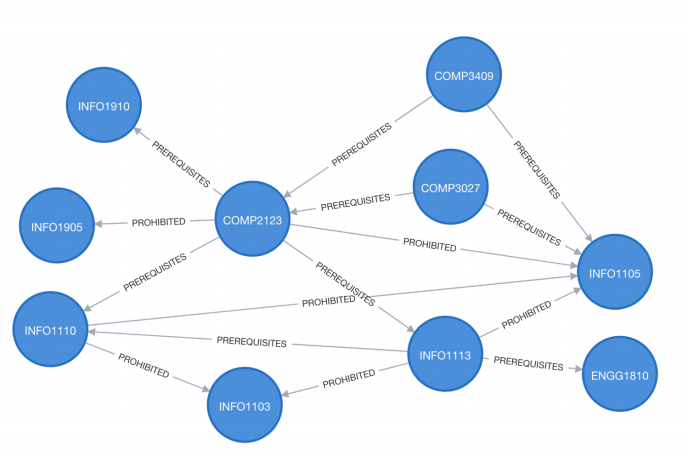
Figure 1 Sample University Unit Graph
1. [6 points] Write a query to find the unit and its prerequisite unit pair that do not run in the same semester print out the pair of unit codes. If a unit runs in one semester (e.g. COMP2123 runs in S2), but its prerequisite unit runs in both semesters (e.g. INFO1110 runs in both S1 and S2), they are considered as running in the same semester.
2. [5 points] Write a query to find the unit that appears in most other units’ prohibited lists. In the above sample graph. INFO11105 appears in the prohibited list of three other units: INFO1113, COMP2123 and INFO1110. It will be the returned as the result ofthis query.
3. [8 points] Write a query to augment the graph with new units. The data of all new units are stored in a json file “units.json” formatted as an array ofjson objects. Each object represents a unit. Below is an example object for unit DATA3404:
{
"code": "DATA3404",
"title": "Scalable Data Management",
"cp": 6,
"semesters": ["S1"],
"prohibited": ["INFO3504","INFO3404"],
"prerequisites": ["DATA2001", "ISYS2120","INFO2120"]
}
4. [6 points] The current graph assumes an OR logic operation among all prerequisites of a unit. For instance, DATA3404 has three units listed as prerequisite. It means DATA2001 OR ISYS2120 OR INFO2120. Students only needs to complete one of the prerequisite units before they are allowed to enroll in DATA3404. This assumption is not realistic as some unit requires completion of two or more prerequisite units. Describe a way to represent such information in the graph. You may change the current design.
Question 4 Dynamo (20 points)
Suppose we have a Dynamo cluster with 6 nodes: n0~n5. The tokens assigned to each nodes are as follows:
n0: 0, 82; n1: 25; n2: 12, 70; n3: 61; n4: 35; n5: 44,90
The maximum ring space value is 99. The cluster has a replication factor of 3; the size of preference list is 4; A table about web pages is stored in this cluster, with keys equal to the page’s
URL.
1. [4 points] Suppose the hash value of key “www.cnn.com” is 65. What is the preference list ofthis key?
2. [2 point] Suppose key “www.amazon.com” has two versions of with the following vector clocks: ([n5, 10], [n3,1]), ([n5,11], [n3,2]). During the period, all nodes except n5 has been temporarily unavailable. What is the possible range of this key’s hash value?
3. [2 points] If a read query receives two responses with the above vector clocks, which version would it return?
4. [2 points] If n5 is coordinate the next update of key “www.amazon.com”, what would be the vector clock ofthe new version?
5. [5 points] Write a vector clock that is the descendant ofthe two vector clocks: ([n4,4], [n5,1]), ([n4,2],[n3,2])
6. [5 points] Describe the key range stored in n0. This should include key range that n0 serve as coordinator and key range n0 serve as replica.
2021-12-23