Assignment (Spring 2020) FY – Introductory Computer Science
Assignment (Jan Start – Semester 2 - 2020)
What is this assignment?
This is a graded assignment for the Spring 2020 semester and it accounts for 15% of the total marks for the Introductory Computer Science module. This assignment provides you an opportunity to practice and assess the Python skills learned during this semester.
Please note that all the files you need are included as hyperlinks in this document, but can also be downloaded from the “Semester 2 Assignment” module in the Canvas page for this course.
What to submit?
You are asked to write Python 3 programs for the assignment questions, appended below.
Please submit your programs as a python (.py) file AND a text (.txt) file (so it is easier for me to check for plagiarism)
Delay in submission will carry a penalty of 10% each day.When is the submission due?
The submission of your work on Canvas is due by Friday 26th June 2020, before 2359 BST. There will be mini-vivas held online. You will be given notice 7 days in advance for these.How is this assessed?
The assessment will include grading of your program submissions and mini-viva. The assessor will assess your solution to the problems and whether you completely understand the submitted solution. Good programming practices will be rewarded during the assessment. These goodpractices include:
• meaningful variable/function naming,
• top down algorithm design,
• intelligent use of programing constructs (loops, conditions, functions, sequences, arrays, plots, etc.),
• empty spaces in the program to enhance readability.
Mini-viva is mandatory and a failure to appear for mini-viva will result in being awarded 0 marks for your submission.
IMPORTANT NOTE on plagiarism
All files will be scanned by a plagiarism checker that specialises in detecting plagiarism in programs. It is particularly good at spotting where a program has been altered by changing names of variables and functions and moving a few lines around. If plagiarism is suspected it will be investigated and, if appropriate, reported. As a guide: you will want to discuss the work with friends. If you discuss the general way in which the problem can be solved, your work will not be considered plagiarised. If you swap specific lines of code with friends and include them in your program, the plagiarism checker is very likely to detect them.
It is your responsibility to ensure that you submit your own work and that you DO NOT share your work with anyone else. Any plagiarism (i.e. copying) found will be dealt with according to the University’s procedures in this regard.
ASSIGNMENT QUESTIONS
QUESTION 1: Caesar cipher [4 marks]
In cryptography, a Caesar cipher is a very simple encryption technique in which each letter in the plain text is replaced by a letter some fixed number of positions down the alphabet. For example, with a shift of 3, A would be replaced by D, B would become E, and so on.
The method is named after Julius Caesar, who used it to communicate with his generals.
ROT-13 ("rotate by 13 places") is a widely-used example of a Caesar cipher where the shift is 13 places for the alphabet letters. For example, with a shift of 13, A would be replaced by N, B would become O, and so on.
ROT-5 ("rotate by 5 places") is an example of a Caesar cipher where the shift is 5 places for the digits.
For example, with a shift of 5, 1 would be replaced by 6, 2 would become 7, and so on.More information about Caesar cipher may be viewed at: https://en.wikipedia.org/wiki/ROT13.
To develop the solution for this question, the key for ROT-13 must be represented by means of a dictionary. Similarly, the key for ROT-5 must be represented by means of a separate dictionary.
Develop a Python program to implement an encoder/decoder which uses ROT-13 for alphabets and ROT-5 for digits.
Note that your program should handle special letters (for example: space, ?, !, #) by not making any change to these letters.
Once you're done, you will be able to decode and read the following secret message:Vagebqhpgbel Pbzchgre Fpvrar nffvtazrag 7563 grez 7!!
Your program should be able to both encode texts written in English and decode texts written in Caesar cipher.
QUESTION 2: word frequency [3 marks]
It is common in document analysis to determine the word frequency (i.e. the count of occurrence of each unique word in the document). Given a text file ‘IntroductoryCS.txt’: https://canvas.bham.ac.uk/courses/42056/modules/items/1475700
Develop a Python program that determines and prints the word frequency of unique words from this file.
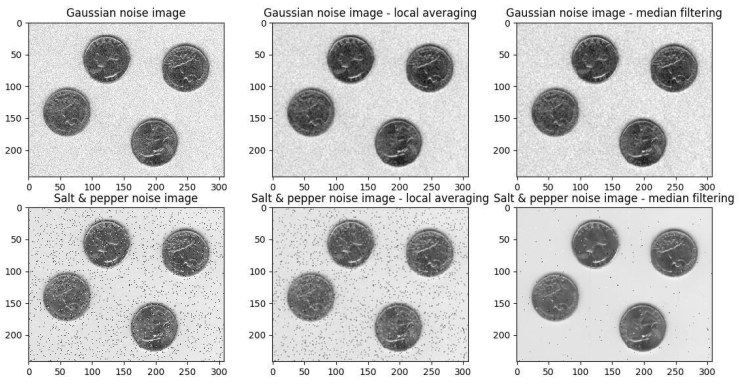
Note that you will need to decide about the use of relevant data structures (e.g., set, dictionary, list) that will serve the purpose to maintain the count and store the unique words.QUESTION 3: image denoising by local averaging and median filtering [8 marks]
It is common for an image to be corrupted by noise of various kinds due to a number of factors.
The image ‘saltpepper.bmp’ is corrupted by salt and pepper noise, it can be downloaded from the link below: https://canvas.bham.ac.uk/courses/42056/modules/items/1475699
The image ‘gaussian.bmp’ is corrupted by Gaussian noise, it can be downloaded from the link below: https://canvas.bham.ac.uk/courses/42056/modules/items/1475698
Recall that an image is a 2D matrix array made up of rows and columns which is represented as a numpy array. Below, two common methods are briefly described which attempt to supress noise by 2D matrix array operations.
(a) Local averaging is a common method to denoise images (i.e. suppress noise) where a small square neighbourhood of odd size (e.g. 3x3, 5x5) around each pixel from the noisy image is taken and the average of this neighbourhood is computed. A new ‘denoised’ image is then formed where each pixel is the average from the local neighbourhood of the corresponding pixel in the noisy image. Note that you will need to have special considerations for the ‘border pixels’ (i.e. pixels close to the border/edge of the image) as the neighbourhood concept may not work precisely for these pixels.
(b) Median filtering is an alternate method to denoise images where a small square neighbourhood of odd size (e.g. 3x3, 5x5) around each pixel from the noisy image is taken and the median value of this neighbourhood is computed. A new ‘denoised’ image is then formed where each pixel is the median from the local neighbourhood of the corresponding pixel in the noisy image. Note that you will need to have special considerations for the ‘border pixels’ (i.e. pixels close to the border/edge of the image) as the neighbourhood concept may not work precisely for these pixels.
More information about median filtering can be viewed at: https://en.wikipedia.org/wiki/Median_filter
Develop a Python program, using matplotlib and numpy, to read both these noisy images (‘saltpepper.bmp’ and ‘gaussian.bmp’) and try to supress the noise using both the local averaging and median filtering methods. Your program should produce results of image denoising similar to below:
2020-06-18