CS544 Module 3 Assignment
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CS544 Module 3 Assignment
Using R code, do the following:
Part 1) 20 points
Initialize the dataset about prime numbers as shown below:
df <- read.csv("http://people.bu.edu/kalathur/datasets/myPrimes.csv")
The resulting data frame of the primes below 10000 along with their last and first digits is as shown below:
|
|

|
|
a) Show the barplot of the frequencies for the last digit.
b) Show the barplot of the frequencies for the first digit.
c) What inferences do you draw from these two plots? (two inferences from each plot)
Part 2) 30 points
Initialize the dataset about the quarter coin productions of the 50 US states by the DenverMint and PhillyMint. The numbers in the dataset (in thousands ) are the number of quarters minted. With the R code for the following:
us_quarters <- read.csv("http://people.bu.edu/kalathur/datasets/us_quarters.csv")
 |
a) For which state were the highest number of quarters produced by each mint? For which state were the lowest number of quarters produced by each mint?
b) What is the value of the total coins in dollars?
c)
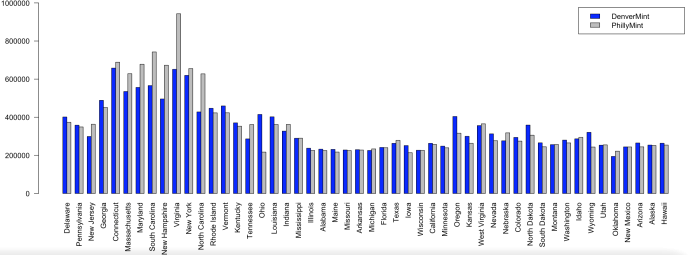 |
Produce the following barplot from the data using the R barplot function with the data for the two mints as a matrix. Write any two striking inferences you can observe by looking at the plot.
d) Show the scatter plot of the number of coins between the two mints. Write any two inferences you can observe looking at the plot.
e) Show the side-by-side box plots for the two mints. Write any two inferences for each of the box plots.
f) Using R code, what states would be considered as outliers for each of the two mints. Use the five number summary function to derive the outlier bounds
Part 3) 20 points
Use the FAANG stocks dataset with the April daily High values initialized as shown below:
stocks <- read.csv("http://people.bu.edu/kalathur/datasets/faang.csv")
a) Show the pair wise plots for all the 5 stocks in the dataset in a single plot.
b) Show the correlation matrix for the 5 stocks in the dataset.
c) Provide at least 4 interpretations of the results.
Part 4) 30 points
Initialize the scores of 100 students as shown below:
scores <- read.csv("http://people.bu.edu/kalathur/datasets/scores.csv")
a) Show the default histogram of the student scores. Save the result of the histogram into a variable. Using only the counts and breaks property of this variable, write the R code to produce the following output. The code for the following output should not refer to the individual scores.
 |
b) Using the breaks option of the histogram, show the histogram and the custom output as shown below so that students in the range (70,90] get an A grade, (50,70] get a B grade, and (30-50] get a C grade. The code for the following output should not refer to the individual scores.
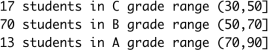 |
Submission:
When the term lastName is referenced, please replace it with your last name.
Create a folder, CS544_HW3_LastName_Last4DigitsBUID and place the following files in this folder.
Provide all R code in a single file, CS544_HW3_LastName_Last4DigitsBUID.R. Clearly mark each subpart of each question.
Provide the corresponding outputs from the R console in a single Word document,
CS544_HW3_LastName_Last4DigitsBUID.doc.
Archive the folder (CS544_HW3_LastName_Last4DigitsBUID.zip). Upload the zip file to the Assignments section of Blackboard.
2021-11-29