ECO-6009A Programming and Data Analytics
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Technical Assignment
Programming and Data Analytics (ECO-6009A)
There are THREE questions in this technical assessment. Please answer all questions. Good Luck!
For the exercises below you will have to load the following packages in R :

Question 1.1. For this exercise we will use the mtcars data set in R that you have seen in lectures. Call in this dataset in R with the data(mtcars) command. Use some of the commands discussed in lecture to study this dataset. [5 marks].
Question 1.2. Using the mtcars data set, let us regress the variable number of miles per gallon for each car (mpg) on displacement (in cubic inches) (disp) which is a measure of the size of the engine and visualise information about this regression model and its residuals. To do this, first fit a linear regression model by regressing mpg on disp using the lm() function in R. Now, assign the output of your regression to an object called fit. Next, see the results in fit using the summary() function. Do your regression results make sense? Next, use the functions add_predictions() and add_residuals() from the modelr package to create two new variables in the data set mtcars itself, called predicted and residuals. [ HINT : Recall from lectures that you will have to use BOTH the dataset mtcars and the regression object fit to work with these functions ]. These are the saved predicted and residual values from your regression. [5 marks].
Question 1.3. Let us now use the graphic capabilities of R to provide a method to interpret residual terms (and determine whether there might be problems with our model). We continue with our earlier example, where we regressed miles per gallon (mpg) on displacement (disp) and saved the predictions and residuals (called predicted and residuals, respectively) of this regression in the dataset mtcars. Now take the dataset mtcars and write a command to quickly look at the first 7 rows of the actual (values of mpg), the predicted values, and the residual values.[5 marks].
Question 1.4. Now call the ggplot2 library and with mpg on the Y axis against disp on the X axis, plot the actual values of mpg and the predicted values of mpg from the earlier regression. Note that you may have to call geom_point() twice to achieve this in your ggplot command. Use a different shape for points showing the predicted values of mpg. [ HINT : You can use shape = 1 within geom_point() to do this ]. [5 marks].
Question 1.5. The earlier graph in Question 1.4. is on track, but it is difficult to see how our actual and predicted values are related. Let us connect the actual data points with their corresponding predicted values using the command geom_segment(). geom_segment() makes use of the following aesthetics : geom_segment(aes(x = ---, y= ---, xend = --- , yend = ---)). So you can use something like : geom_segment(aes(x = disp, y = mpg, xend = disp, yend = predicted)) to connect the actual values of the Y variable (mpg) with the predicted values of the Y variable. [5 marks].
Question 1.6. Now make a few final adjustments to the graph in Question 1.5. : Clean up the overall look with theme_bw(). This will change the background of the graph in Question 1.5. to white. Also fade out the connection lines between actual and predicted values of the Y variable (mpg) by adjusting their alpha value to 0.2. You can do this inside the geom_segment() function call. Also add the regression line of mpg against disp to your diagram with geom_smooth(). Recall that you can add these pieces, viz., theme_bw(), geom_segment() and geom_smooth() to the ggplot() command earlier in problem by using +. [5 marks].
Question 1.7. Finally, we want to make an adjustment to highlight the magnitude of the residuals, i.e., we want to see how extreme these residuals are. There are MANY options to do this. One way is to highlight high residuals (based on their absolute value) by coloring them (in red). You can use the option scale_color_continuous(low = "black", high = "red") to do this. Type ?scale_color_continuous() and look at the help for this command and figure out what the function scale_color_continuous() does. Then use scale_color_continuous(low = "black", high = "red") to highlight the residuals as mentioned above, so low (absolute) value of residuals should be coloured black and high absolute value of residuals should be coloured red with intermediate values getting a shade of colour between black and red. Use the command or ggplot layer guides(color = FALSE) to remove the colour legend. [ HINT : If you want to you can take a look at the hint provided in Question 1.8 below which may also help you in answering this question ]. [5 marks].
Question 1.8. The plot in Question 1.7. is great, but we can do better by adding more (visual) information on residuals (in the graph). One way to to this would be to colour and size residuals by how extreme the residuals are. So now we will use both colour and size to pinpoint large residuals (instead of just colour as we did in Question 1.7. above). To do this, use the following bit of code (note that this code is incomplete and you will have to add in additional code to get an actual graph). Note the use of scale_color_gradient2(low = "blue", mid = "white", high = "red") below. What insights about your data do you gain from this exercise? [5 marks].
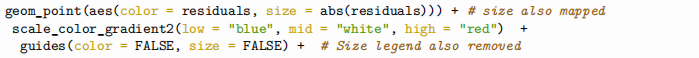
Question 1.9. Plotting one independent variable against a dependant variable is all well and good, but the whole point of regression is usually to investigate the effect of multiple vari-ables. Let us crank up the complexity and get into multiple regression, where we regress one dependant variable on two or more other explanatory or predictor variables. For this ques-tion, regress miles per gallon (mpg) on horsepower (hp), weight (wt), and displacement (disp). Repeat exactly the procedure(s) outlined in Question 1.2. to first run a linear regression of mpg on hp, wt and disp and then storing the predictions and residuals in the data set mtcars.[HINT : Remember that you need to start with a clean slate and you should run data(mtcars) to call in the data set mtcars again and clear all the extra columns that you have created in the earlier exercises.] [5 marks].
Question 1.10. Let us now study the residuals from the regression in Question 1.9. Let us create a relevant residual plot by using just ONE of our predictors, displacement (disp). We wil start by plotting the actual and predicted values of the Y variable, or mpg, against this explanatory variable, disp. For this exercise, we will not plot the actual regression line. So, just plot the actual and the predicted values of mpg, and join the actual and predicted values of mpg using the code that you have seen earlier in Question 1.5. Again, we can make all sorts of adjustments using the residual values. Apply the same changes to this plot as in Questions 1.7. to 1.8. - using red color to indicate high values and blue color to indicate low values (and white color to indicate medium values) of the residuals. You do not have to map the absolute size of the residuals in your graph.[5 marks].
Question 2. Using the diamonds dataset explore the distribution of the variable price (which shows the price, in US dollars, of a diamond) using a histogram. Use geom_histogram() to do this. Comment on the choice of a suitable binwidth for the histogram. What interesting features do you find for the distribution of price. Now examine a few ways of exploring the distribution of price by the variable cut (a categorical variable, which shows the cut of a diamond). What does your exploration reveal? Comment on the suitability of this exercise, i.e, does looking at the distribution of price by cut lead to any meaningful insights about the data? [20 marks].
Question 3. In the ggplot2 library the gg stands for the “Grammar of Graphics”. What is the “Grammer of Graphics”? How does knowledge of the “Grammar of Graphics”" aid in effective visualization of data? [30 marks].
2021-11-26