ECSE 419: TEST HOME 2
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
ECSE 419: TEST HOME 2
Problem 1 :
We discussed in class the column sweep algorithm as it applies to parallelize the following matrix recurrence problem:
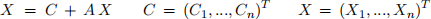
where A was a n × n lower-triangular matrix, C is a column vector and X is a variable column vector. In this problem, you will apply the column sweep algorithm to parallelize the same type of recurrence but matrix A will be a general n × n matrix.
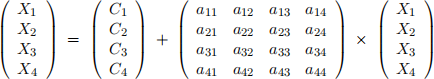
We will use up to n processors operating in SIMD mode (single-instruction/multiple-data).
a) Describe the major steps of the column sweep algorithm as they apply to this problem. Show the memory data structuring of C, A and X that supports this SIMD computation, assuming every processor has its own memory module.
b) What is the speedup and efficiency of the parallel scheme in comparison to a single processor solution. How about the utilization?
c) By careful consideration of the workload, it is possible to reduce the resource requirements by al-locating non-overlapping (in time) computation steps into the same processor. The overall parallel time should remain the same. Describe your processor allocation scheme. How many processors do you need at most.
d) Suppose there are only m processors and n memory modules, respectively, where m < n. Using still the SIMD model, describe how will your computation process and the data structures be mofified. What is the new speedup and efficiency?
Problem 2 : Assume that we use a (n×n×n) 3D grid for a Laplace volume solver. We also use n×n×n processors located on each grid node. Each processor has six routing port registers, RE, RS, RW, RN, RU, RD for data routing to east, south, west, north, up and down processors, respectively. Otherwise, the processors have very simple internal architecture, so that it is cost-effective to use many of them. Moreover, each processor has 16 general registers, standard (unpipelined) arithmetic functional units, and limited memory. Only one processor instruction can be executed per cycle and every instruction takes one computation cycle. Basic processor instructions and formats are:

Simple loop iteration instructions are also needed. We assume bidirectional point-to-point interconnects in the processor mesh.
a) Express in familiar grid notation the main 3D Laplace equation. Write a parallel program in pseudo-code to solve the Laplace equation assuming a 64 × 64 × 64 grid.
b) How many cycles does it take to execute 1000 iterations of this program in the parallel 3D mesh? No convergence test is performed.
c) What is the speedup and efficiency of the parallel processor mesh scheme in comparison to a single processor solution. Assume that we use the same processor types in both cases.
d) Estimate the memory data requirements per processor (only for data) concerning the parallel scheme, as well as the single processor solution.
● Extra Credit. Build a C/C++ program which implements the 3D Laplace solver using a simple initial condition: node (0, 0, 0) set at 10◦C; all other nodes are reset to 0◦C. Your program should emulate the Laplace solver operating sequentially on a single processor. Provide an output listing first for 10 and then 100 iterations. Is there any converging trend of the values in the 3D grid?
Problem 3 – Consider a parallel computer with common controller, P processors and M memory modules where one memory cycle and one processor operation take one time step. Assume each processor has 8 registers. Consider the following loop:
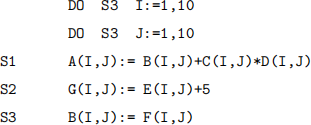
a) What is the minimum time required to execute this loop? explain why. What is the smallest number of processors P and memory modules M that can be used to achieve this time?
b) What speedup SP and efficiency EP can be achieved by this computation?
c) Show an interconnection network structure supporting the above parallel computation.
d) Suppose that E(I,J) is replaced by A(I+1,J) in the above loop. Explain any new inter-iteration dependencies that you may observe in this loop structure. Without much details, discuss the effect of this replacement on your results. If there is such an effect, can you suggest a solution?
Problem 4 :
Consider the following computation loop which updates and relocates a data Array–1 into a data Array–2, conditionally, based on loaded values from Array–3.

We assume a Load/Store instruction set architecture augmented for floating point operations. The machine is one-instruction issue and has an ADD/SUB integer unit, an ADDF/SUBF floating point unit and a branch predict unit. Branch instructions are delayed. There are 2 latency cycles associated with the execution of the floating ADDF/SUBF operations. Also, LD and LF need one load slot and the branches have one branch delay slot. The above loop is supposed to execute 10 iterations in total.
We assume that the branch prediction buffer is initially reset. In all questions below you should include the effect of the branch prediction buffer. Recall, there is no penalty for correct prediction, however, there is a 2 cycle penalty for misprediction. If an instruction is not in the buffer, and turns out to be branch, the penalty depends on whether it is taken or not.
a) Without any loop body optimizations, what is the minimum possible execution time of the above loop for 10 iterations?
b) What is the maximum possible execution time of the loop for 10 iterations?
c) Perform loop body optimizations, without loop unfolding, and then repeat a) above. How are your results affected?
d) If you consider loop unfolding in a) and b), how are your results in this problem going to change.
Problem 5 :
We would like to evaluate a cubic polynomial Ax2 + Bx − C using a LOAD/STORE instruction set architecture. D, A and B are both 32-bit intergers whereas C, and x are floating point numbers. Assume that x is already in register F7 and that the constants A, B, C are in memory locations 1000, 1004, 1008, respectively. The code block below implements the polynomial in LOAD/STORE assembly like language, with comments.
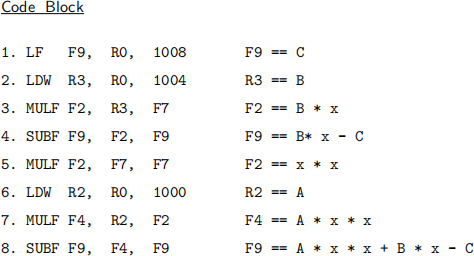
We would like to evaluate the polynomial on the LOAD/STORE pipeline machine, augmented to implement the Tomasulo dynamic pipeline architecture; an example machine is shown in the next Figure.
This machine has 1 Load Buffer (6 registers), 1 Instruction Queue (6 registers), 2 Add/Subtract Units, 2 Multiply/Divide Units, 1 Sore Buffer, 16 FP registers, and 16 Integer Registers. We assume that the latencies of the floating-point addition and multiplication operations are 2 and 6 cycles, respectively. Assume that 2 instructions can be issued at a time. Also, the Reservation Station status and the Register status are shown in the following Charts.
Initially, the buffer contains the following instructions
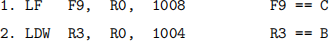
2021-11-26