CS 2505 Computer Organization I
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CS 2505 Computer Organization I
C Programming
Pointer Accesses to Memory and Bitwise Manipulation
This assignment consists of implementing a function that can be executed in two modes, controlled by a switch specified by a parameter to the function:

The function will access a scrambled quotation, stored in a memory region pointed to by pBuffer. The organization of the memory region is described in detail below. The function will analyze that memory region, and reconstruct the quotation by creating a sequence of WordRecord objects and storing them in an array provided by the caller.
You will also implement a function that will deallocate all the dynamic content of such an array of WordRecord objects:

Part of your score on the assignment will depend on the correctness of this function, and your ability to deallocate any other allocations your solution may perform. This will be determined by running your solution on Valgrind; your goal is to achieve a Valgrind report showing no memory leaks or other memory-related errors:

Case 1 [80%] Untangling Clear Data Records in Memory
Here is a hexdump of a memory region containing a scrambled quotation:
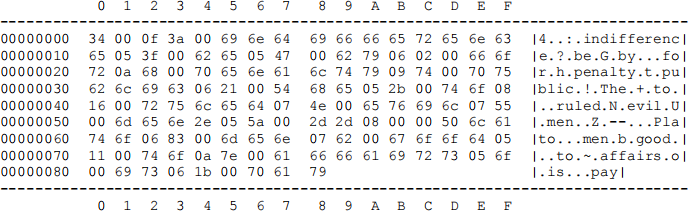
The first two bytes of the memory region contain the offset at which you will begin processing records: 0x0034.
This offset of the first record is followed by a sequence of word records, each consisting of a positive integer value, another positive integer value, and a sequence of characters:
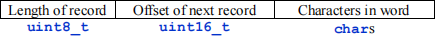
The first value in each record specifies the total number of bytes in the record. Since words are relatively short, this value will be stored as a 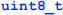 , which has a range of 0 – 255. The record length is followed immediately by a
, which has a range of 0 – 255. The record length is followed immediately by a 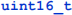 value specifying the offset of the next word record in the list. This is followed by a sequence of ASCII codes for the characters that make up the word. (The term "word" is used a bit loosely here.) There is no terminator after the final character of the string, so be careful about that.
value specifying the offset of the next word record in the list. This is followed by a sequence of ASCII codes for the characters that make up the word. (The term "word" is used a bit loosely here.) There is no terminator after the final character of the string, so be careful about that.
Note that the length of the record depends upon the number of characters in the word, and so these records vary in length. That's one reason we must store the offset for each record.
Since I'm using x86 hardware, integer values are stored in memory in little-endian order; that is, the low-order byte is stored first (at the smallest address) and the high-order byte is stored last (at the largest address). So the bytes of a multi-byte integer value appear to be reversed. For example, if we have in 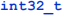 variable holding the base-10 value 85147, the corresponding base-16 representation would be 0x14C9B, and the in-memory representation would look like this:
variable holding the base-10 value 85147, the corresponding base-16 representation would be 0x14C9B, and the in-memory representation would look like this:
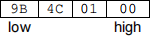
or, represented in pure binary:
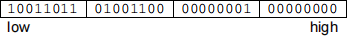
The least-significant byte (corresponding to the lowest powers of 2) is stored at the lowest address, and the most-significant byte (corresponding to the highest powers of 2) is stored at the highest address.
As a programmer, you usually do not need to take the byte-ordering into account since the compiler will generate machine language compatible with your hardware, and that will make use of the bytes in the appropriate manner. But, when you're reading memory displays, you must take the byte-ordering into account.
So, looking at the first two bytes of the memory block, we see that the word record we will process first occurs at relative offset 0x0034 from the beginning of the memory block.
Let's consider how to interpret the hexdump shown earlier:
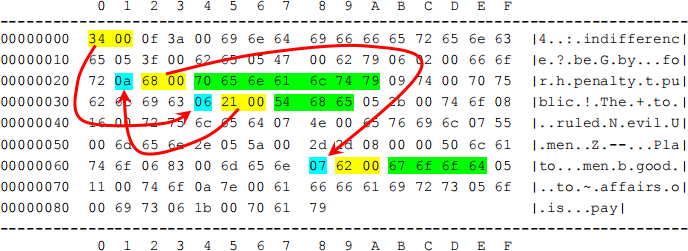
The first word record consists of the bytes:

The length of the first record is 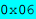 or 6 in base-10, which means that the string is 3 characters long, since the length field occupies 1 byte and the offset of the next record occupies 2 bytes. The ASCII codes are
or 6 in base-10, which means that the string is 3 characters long, since the length field occupies 1 byte and the offset of the next record occupies 2 bytes. The ASCII codes are  , which represent the characters "The". The offset of the next record is
, which represent the characters "The". The offset of the next record is 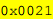 .
.
The second word record consists of the bytes:

The length is 0x0a (10 in base-10), so the string is 7 characters long (the ASCII codes represent "penalty"), and the next word record is at the offset 0x0068. And so forth... The complete quotation, with word record offsets, is:

To indicate the end of the sequence of word records, the final word record specifies that its successor is at an offset of 0, which is invalid (since that's the offset of the pointer to the first word record).
For case 1, your function will be passed the value CLEAR for the parameter Fmt.
You will use the WordRecord data type to represent a parsed word record:
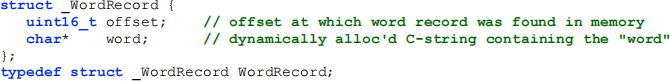
You will create one of these  variables whenever you parse a word record, and place that
variables whenever you parse a word record, and place that 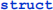 variable into an array supplied by the caller of your function.
variable into an array supplied by the caller of your function.
Case 2 [20%] Untangling Mildly Encrypted Data Records in Memory
Read the posted notes on bitwise operations in C, and the related sections in your C reference.
For this case, your function will be passed the value ENCRYPTED for the parameter Fmt.
The memory region pointed to by pBuffer will be formatted in exactly the same way as for case 1, except that the bytes that represent the offset of the next record and the characters in the word will have been "masked":
Each of the ASCII codes in the word field has been XORed with a mask formed by taking the number of characters (bytes) in the word, and reversing the nybbles of that value (remember, the length of the character sequence is stored as a one-byte value). Each byte of the offset field has been XORed with the unmasked first byte in the word. You must "unmask" the masked bytes in order to properly display the quotation.
Part of the assignment is for you to determine what operation(s) you can use to perform this unmasking. We will not answer any questions about how to do that, except to say that you should consider the properties of the various bitwise operations available in C. This is a good opportunity for you to discover the value of the Boolean algebra rules covered in Discrete Mathematics.
Aside from the issue of unmasking the encrypted bytes, the logic of this part is identical to the handling without encryption, so we will not repeat the detailed description given there. However, we will give you an example illustrating what must be done:

The first word record begins at offset 0x0025, and contains the bytes: 
The length of the word is 0x02, so the mask is 0x20. XORing that with each byte of the string yields:  which represents the character string "It".
which represents the character string "It".
And, XORing the first byte of the word with the bytes of the offset yields:  which is the offset of the next record. In this case, the encrypted quotation decodes to:
which is the offset of the next record. In this case, the encrypted quotation decodes to:

Testing and Grading
A tar file is posted for the assignment containing testing/grading code:

Create Untangle.c and implement your version of it, then compile it with the files above. Read the header comments in c07driver.c for instructions on using it.
The test driver produces two output files:
The second file cannot be viewed in most text editors. However, you can use the hexdump utility to display the contents in a form that's almost identical to the examples shown earlier in this specification: hexdump -C Data.bin
The grading script automates the entire process of running the tests, including Valgrind. If Valgrind detects any errors at all when your solution is tested, we will assess a penalty of 10% of the project score. We will also assess the penalty if your
2021-11-23