MAST30027 Modern Applied Statistics
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
MAST30027 Modern Applied Statistics
Question 1 (10 marks) The Poisson distribution has the probability density function (pdf)
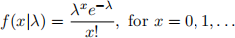
(a) Show that the Poisson distribution is an exponential family, identifying the parameters θ and φ as well as the functions b(θ) and a(φ).
(b) Obtain the canonical link. Show your work.
(c) Obtain the variance function. Show your work.
Question 2 (8 marks) Let X1, ··· , Xn be independent random variables from a Poisson distri-bution with the pdf given in Question 1.
(a) What is the log-likelihood for this example?
(b) What is the Fisher information for this example?
(c) Find the MLE of λ and its asymptotic distribution.
Question 3 (18 marks) The Fiji Fertility Survey gives data on the number of children ever born to married women of the Indian race classified by duration since their first marriage (grouped in six categories), type of place of residence (Suva, other urban and rural), and educational level (classified in four categories: none, lower primary, upper primary, and secondary or higher). The dataset has 70 rows representing 70 groups of families. Each row has 5 entries giving:
● duration: marriage duration of mothers in the group (years),
● residence: residence of families in the group (Suva, urban, rural),
● education: education of mothers in the group (none, lower primary, upper primary, sec-ondary+),
● nChildren: number of children ever born in the group (e.g. 4), and
● nMother: number of mothers in the group (e.g. 8).
Examine the R code and output below, and then answer the questions that follow. First, we can summarise data as a table as follows.

(a) For modelA, assuming Poisson responses, what is the log-likelihood of the fitted model, and the log-likelihood of the full (saturated) model?
(b) Assuming Poisson responses, which is better, modelA or modelB? Give two (quantitative) reasons for your answer.
(c) Give the std. error for educationlower in the case where we allow for overdispersion.
(d) Allowing for overdispersion, do you prefer modelC or modelD, and why?
(e) What formula has been used to calculate the F statistic in the second analysis of deviance? What are the degrees of freedom for the F statistic?
Question 4 (15 marks) The National Institute of Diabetes and Digestive and Kidney Diseases conducted a study on 768 adult female Pima Indians living near Phoenix. The purpose of the study was to investigate factors related to diabetes. The dataset can be found in the the dataset pima. The dataset contains the following variables:
● test: test whether the patient shows signs of diabetes (coded 0 if negative, 1 if positive)
● pregnant: Number of times pregnant
● glucose: Plasma glucose concentration at 2 hours in an oral glucose tolerance test
● diastolic: Diastolic blood pressure (mm Hg)
● triceps: Triceps skin fold thickness (mm)
● insulin: 2-Hour serum insulin (mu U/ml)
● bmi: Body mass index (weight in kg/(height in metres squared))
● diabetes: Diabetes pedigree function
● age: Age (years)
Examine the R code and output below, and then answer the questions that follow. There are missing observations for many variables, which have all been recorded as zeros. These are removed first.
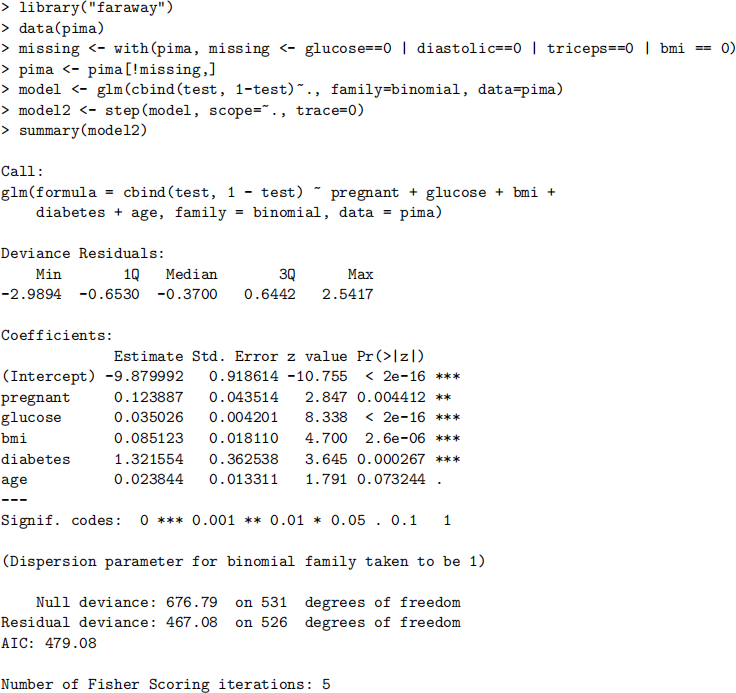
(a) Under the model2, give an estimate of the probability of the patient showing positive signs of diabetes when pregnant = 1, glucose = 99, bmi = 27, diabetes = 0.25, age = 25.
(b) Odds are sometimes a better scale than probability to represent chance. The odds o and probability p are related by
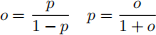
In a binomial regression model with a logit link we have
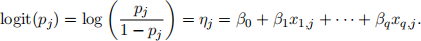
That is log
where oj are the odds for the j-th observation.
By what proportion do the odds of testing positive for diabetes change for a woman with a BMI at 27.87 compared with a woman with a BMI at 36.90, assuming that all other factors are held constant? Give a 95% confidence interval for this difference.
Question 5 (18 marks) Consider a random sample X1, ··· , Xn satisfying Xi 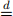 pois(θ) i.e.,
pois(θ) i.e., 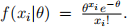 To assess an estimator
To assess an estimator 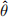 = t(X1, ··· , Xn) of θ we use the loss function
= t(X1, ··· , Xn) of θ we use the loss function 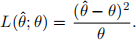 We assume a gamma prior pdf θ gamma(β,
We assume a gamma prior pdf θ gamma(β, 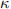 ) with known β and , i.e.
) with known β and , i.e. 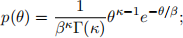 θ > 0.
θ > 0.
(a) Show that the Bayes estimator under the given loss function is
(b) What is the posterior distribution of θ. Show your work.
(c) Find a closed form for
Question 6 (7 marks) You only have access to uniform random number generator. For a random X, f(x) 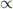 log(1 + x) if x ∈ [0, 2], and 0 else. Provide a rejection sampling algorithm (or pseudocode) to sample X. Your algorithm should be the most efficient algorithm (i.e., one that minimises the probability of rejection).
log(1 + x) if x ∈ [0, 2], and 0 else. Provide a rejection sampling algorithm (or pseudocode) to sample X. Your algorithm should be the most efficient algorithm (i.e., one that minimises the probability of rejection).
Question 7 (6 marks) Consider a Metropolis-Hastings (MH) algorithm where you propose θn from a Normal(θo, 1) distribution (where θo is the current sample) and accept with probability min(1, 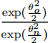 ). What is the stationary distribution? Briefly describe the MH algorithm to simulate samples from that stationary distribution.
). What is the stationary distribution? Briefly describe the MH algorithm to simulate samples from that stationary distribution.
Question 8 (18 marks) You want to sample from 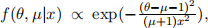 where θ is real-valued and µ ∈ {0, 1} and x is known.
where θ is real-valued and µ ∈ {0, 1} and x is known.
(a) Give the conditional distributions of θ|µ, x and µ|θ, x, including their parameters.
(b) Briefly describe a Gibbs sampling algorithm for sampling (θ, µ), and how you would use it to estimate the mean of
.
2021-11-15