QBUS2820 Assignment 2
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
QBUS2820 Assignment 2 (30 marks)
1 Background and Task
Your task is to develop a predictive model to forecast the daily confirmed cases of COVID-19 of a country given its historical daily confirmed cases. The COVID-19 data set Covid_19_train.csv contains the COVID-19 daily cases observed from 29/02/2020 to 20/09/2020. This data set is based on a real COVID-19 data set with some added noise for the de-identification purposes. The test data set Covid_19_test.csv (not provided) has the same structure as the training data, and contains the COVID-19 daily cases from 21/09/2020 to 05/10/2020 (15 days).
Your task is to develop a predictive model, using Covid_19_train.csv, to forecast the COVID-19 daily cases of the country from 21/09/2020 to 05/10/2020. Note that, this is a multiple-step-ahead forecast problem.
Test error
For the measure of forecast accuracy, please use mean squared error (MSE). The MSE, computed on the test data, is defined as follows. Let 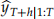 be the h-step-ahead forecast of
be the h-step-ahead forecast of 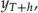 based on the training data
based on the training data 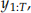 where
where 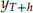 is the h-th value in the test data Covid_19_test.csv. The test error is computed as follows
is the h-th value in the test data Covid_19_test.csv. The test error is computed as follows
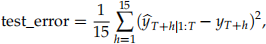
where 15 is the number of observations in the test data.
2 Submission Instructions
1. You need to submit, via the link in the Canvas site, a Python file, named SID_implementation.ipynb (SID is your student ID) that implements your data analysis procedure and produces the test error. You might submit additional files that are needed for your implementation, the names of these files must follow the same format SID_xxx.
2. The Python file is written using Jupyter Notebook, with the assumption that all the necessary data files (Covid_19_train.csv and Covid_19_test.csv) are in the same folder as the Python file.
● If the training of your model involves generating random numbers, the random seed in SID_implementation.ipynb must be fixed, e.g. np.random.seed(0), so that the marker expects to have the same results as you had.
● The Python file SID_implementation.ipynb must include the following code
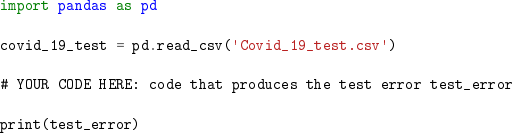
The idea is that, when the marker runs SID_implementation.ipynb, with the test data Covid_19_test.csv in the same folder as the Python file, he/she expects to see the same test error as you would if you were provided with the test data. The file should contain sufficient explanations so that the marker knows how to run your code.
● In case you want to test your code to see if a test error is produced, a “fake” test data is provided. This data set has the same format as the real test data Covid_19_test.csv, except that the COVID-19 cases in there are not the actual values. Don’t worry about the test error produced with this “fake” test data - this is just to test if your code runs smoothly.
● You should ONLY use the methods covered in the lectures and tutorials in this assign-ment. You are free to use any Python libraries to implement your models as long as these libraries are be publicly available on the web.
3. You should describe within the Jupyter Notebook your data analysis procedure in some detail. The description should be detailed enough so that other data scientists, who are supposed to have background in your field, understand and are able to implement the task.
3 Marking Criteria
This assignment weighs 30 marks in total. The prediction accuracy contributes 25 marks and the description of your data analysis procedure (see Section 2.3) contributes 5 marks. The marking is structured as follows.
1. The accuracy of your forecast: Your test error will be compared against the smallest test error among all students. The marker first runs SID_implementation.ipynb
● Given that this file runs smoothly and a test error is produced, the 25 marks will be allocated based on your prediction accuracy, compared to the smallest MSE produced by the best student, and the appropriateness of your implementation.
● If the marker cannot get SID_implementation.ipynb run or a test error isn’t produced, some partial marks (maximum 5) will be allocated based on the appropriateness of SID_implementation.ipynb.
2. The 5 marks for the description of the data analysis procedure are allocated based on
● the appropriateness of the chosen forecasting method.
● the details, discussion and explanation of your data analysis procedure.
2021-11-12