SARSA for Markov Decision Processes
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Problem 2: SARSA for Markov Decision Processes (12.5 points)
As an alternative to Value Iteration in the previous problem, there exists another algorithm, SARSA, first proposed by Richard Sutton and detailed here:
http://incompleteideas.net/book/ebook/node64.html. In this problem, you will implement SARSA on the Frozen Lake environment and compare the algorithm to Value Iteration from the previous problem.
Problem specifications:
● Frozen Lake environment can be either 4x4 or 8x8.
● The avatar can move up, down, left, or right.
● Reward associated with each state:
○ Goal location: +1
○ Hole: 0
○ All other locations: 0
● As part of SARSA, you will have to implement an epsilon-greedy helper function to determine the next actions. You should use a value of epsilon = 0.1.
● Use a reasonable value for gamma.
Deliverables:
● A SARSA function that outputs the optimal value function and optimal policy.
● A document containing the value function and policy that results from SARSA on the 4x4 environment (these can simply be copied and pasted arrays from the code output).
○ Describe the difference between the optimal value functions and optimal policies from the previous problem (value iteration) and SARSA. What are the differences and why?
● A Python file that, when run on any 4x4 or 8x8 Frozen Lake environment, shows the avatar traveling from its start location to the goal location (optimally) according to the value iteration results. The start and end locations should be defined at the top and the rest of the code should work if these locations are changed.
Why should one use SARSA instead of the Value Iteration algorithm? You may have noticed that in SARSA we do not assume we know the state transition probabilities as in Value Iteration. In the case that we do not have this information, Value Iteration would not work. In fact, we call this model-free reinforcement learning.
![]() Problem 3: Bayesian Network for Credit Card Fraud Detection (10 points)
Problem 3: Bayesian Network for Credit Card Fraud Detection (10 points)
With the advent of deep learning technologies, creating and disseminating deep fake videos have become significant security threats. Deep fake technology allows malicious actors to generate highly realistic fake videos, audio, or images for various deceptive purposes, such as impersonation, misinformation, and fraud. Arecent notable incident involved a finance worker who paid out $25 million following a video call with a deepfake ‘chief financial officer’. Such incidents underscore how deep fakes can manipulate public opinion, damage reputations, disrupt financial systems, and highlight the urgent need for financial institutions to detect and mitigate deep fake threats in transactions.
Silverman Manley,a financial institution, recognizes the urgency of addressing these challenges to safeguard its transaction processes. In response, you have been tasked with developing a state-of-the-art credit card fraud detection system. This system needs to utilize Bayesian networks to analyze transactional data effectively and predict the likelihood of fraudulent activities. The Bayesiannetwork model will consider various features, including transaction amount, location, time, and cardholder's spending behavior. Crucially, in light of the evolving threat landscape marked by deep fakes, the system must also incorporate mechanisms to assess and mitigate the risks posed by potential deep fake interventions and therefore involves the identity verification stage.
Network Structure
The Bayesian network should have the following structure:
1. Transaction Amount influences the Cardholder's Spending Behavior.
2. Transaction Location and Transaction Time influence the Identity Verification process.
3. Both Cardholder's Spending Behavior and Identity Verification influence the probability of a Fraudulent Transaction.
Your Task
1. Implement the Bayesian network as described above using the pgmpy library. Define the structure and the Conditional Probability Distributions (CPDs) based on the relationshipsoutlined.
2. Assign hypothetical probabilities to each node in the network, ensuring they reflect the dependencies accurately. For example, a high transaction amount may be less common and thus could influence the cardholder's spending behavior differently.
3. Perform inference in the Bayesian network to calculate the probability of a
transaction being fraudulent given evidence such as a high transaction amount, a transaction occurring in a suspicious location, and at an unusual time.
Assignment Requirements
1. Your Python code should use the pgmpy library for creating the Bayesian network, defining CPDs, and performing inference. Include comments at every step to
explain your implementation, as these will be crucial for grading.
2. Accompany your code with a detailed explanation of your approach. This should include:
a. A diagram of the Bayesian network + a rationale for the structure of the network and the choice of probabilities.
b. How the probabilities are stored in the CPDs and how these are utilized for inference.
c. Explain how evidence is incorporated into the model to update the beliefs about the likelihood of a fraudulent transaction. Discuss any assumptions made and
their potential impact on the model's predictions.
Submission Guidelines
Submit your Python script containing the implementation of the Bayesian network, along with a PDF report detailing your approach, the network diagram, and an explanation of the probabilities and inference process.
Ensure your code is well-commented and organized for readability.
In your report, clearly state any assumptions made and justify your choices in the network structure and probability assignments.
Hints:
1. In the Bayesian network for detecting credit card fraud, each factor has its own simple
values. Transaction Amount can be High (1) for amounts larger than usual, or Low (0)
for typical spending levels. Transaction Location can be Suspicious (1) if it's not usual
for the cardholder's habits or known for fraud, and Non-suspicious (0) if it fits with regular spending patterns. Transaction Time could be Unusual (1) if it happens at a time not normally seen for spending, or Usual (0) if it's at a common time. If the Cardholder's Spending Behavior changes from what's normal, it's Anomalous (1); if it follows their usual pattern, it's Normal (0). Lastly, Identity Verification either Fails (1) if it doesn't meet security checks, or Passes (0) if all is okay.
2. Pseudocode- look into how the bayesian model is defined to get a sense of the network structure!
Problem 4: Bayesian Network
(20 points)
Words/ keywords in the text often tell us a lot about the type of text. For example, Email containing text such as “get rich fast” would most likely be a fraud email and must be marked as spam. Explain how you can use Bayesian Networks for spam filtering and write a python program for spam filtering. This question expects you to think beyond just implementing the Bayesian network; you must create your own conditional probability table using the data and the spam keywords.
The input to your program could be any text, the output must be the probability of that text being spam.
For example,
You could use the email text in the following dataset for working on your model or use text from elsewhere (but clearly mention what is being used in your code):
https://www.kaggle.com/datasets/venky73/spam-mails-dataset
Make sure you have a function for preprocessing the text (stop words removal, de-capitalization, etc.)
Example keywords to look for:
spam_keywords = [ 'Viagra', 'Cialis', 'Levitra', 'Vicodin', 'Xanax',
'Ambien', 'OxyContin', 'Percocet', 'Valium', 'Tramadol', 'Adderall',
'Ritalin', 'Modafinil', 'Phentermine', 'Ativan', 'Klonopin', 'Zoloft',
'Prozac', 'Paxil', 'Wellbutrin', 'Celexa', 'Lexapro', 'Effexor', 'Zyprexa',
'Abilify', 'Seroquel', 'Lamictal', 'Depakote', 'Lithium', 'Nigerian',
'Lottery', 'Free', 'Discount', 'Limited time offer', 'Money-back guarantee',
'Investment opportunity', 'Secret', 'Unsubscribe', 'Click here', 'Double your
money', 'Cash','Urgent', 'Get rich quick', 'Work from home', 'Multi-level
marketing', 'Pyramid scheme', 'Enlarge', 'Buy now', 'Online pharmacy',
'Weight loss', 'Casino', 'Credit report', 'Debt relief']
This is not an exhaustive list. You can use fuzzy logic to improve your model to recognize more such keywords.
Fuzzy logic is a mathematical approach that deals with uncertainty and imprecision in natural language processing (NLP). It allows reasoning with uncertain or ambiguous variables and can be applied in various NLP tasks such as sentiment analysis and text classification.
In the current scenario, say you have the word “Urgent” in your list of keywords for spam filtering, but not “Immediate”. And you have the following emails:
● One containing the sentence “needs Urgent action/attention”
● Other containing the sentence “needs Immediate action/attention”
The model would mark only the first email as spam since it would have a higher probability for “urgent” being spam. However, If we had away to identify that urgent and immediate are similar, our model would certainly do better. Fuzzy logic can help identify this similarity.
You can use libraries such as nltk and spacy that provide fuzzy string-matching capability.
How would you extend the concept of using keywords to get the essence of the text for document classification? Can Bayesian Networks be used for document classification?
If yes, explain how this can be done and write a pseudo code for it Else, explain clearly why it is not possible to use Bayesian Networks in this case.
Problem 5: Hidden Markov Models (HMM) (15 points)
Introduction:
A Hidden Markov Model (HMM) is a statistical model that represents systems with hidden states through observable events. HMMs are grounded in probability theory and Bayes' rule, making them powerful tools for various applications, including natural language processing, speech recognition, bioinformatics, and weather prediction. We use the forward-backward algorithm to determine the most-likely hidden state given these transition probabilities.
An HMM consists of the following components:
• Hidden States: These are the states the model transitions through, which are not directly observable. The system is assumed to be a Markov process with unobservable ("hidden") states.
• Observations: These are visible outcomes that provide some information about the hidden states.
• Initial State Probabilities: These probabilities indicate the likelihood of the system starting in each possible state.
• Transition Probabilities: These are the probabilities of moving from one hidden state to another. They reflect the Markov property, where the probability of transitioning to the next state depends only on the current state.
• Emission Probabilities: These are the probabilities of moving from a hidden state to and observation.
In HMM, the future state X is independent on the past given the present. This can be defined as:
P(xt+1 | x1, x2, x3, … , xt) = P(xt+1 | xt)
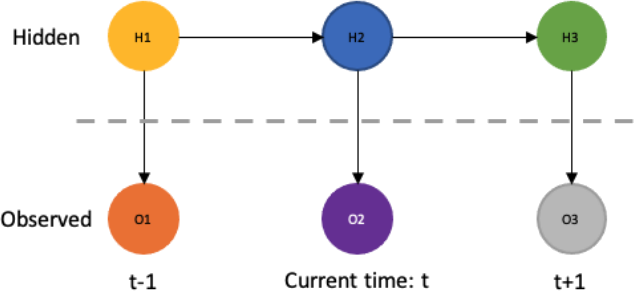
Part #1: Implementing a Hidden Markov Model for Weather Prediction
You are tasked with predicting weather conditions on a tourist island using observed levels of tourist activity. The weather conditions (Sunny, Cloudy, Rainy) influence the tourist activities observed but are not directly observable themselves. Your objective is to implement a Hidden Markov Model (HMM) in Python to calculate the probability of a specific sequence of tourist activities, thereby inferring the underlying weather conditions.
Objectives:
1- Define these problem parameters:
• Hidden States: Weather conditions (Sunny, Cloudy, Rainy)
• Observations: Levels of tourist activity (High, Moderate, Low)
• Transition Probabilities: Refer to table 1
• Emission Probabilities: Refer to table 2
• Initial State Probabilities: Sunny: 1/3, Cloudy: 1/3, Rainy: 1/3
2- Implement a forward algorithm.
3- Analyze the sequence: ['High', 'High', 'Moderate', 'Low', 'Moderate', 'High', 'Low']

Deliverables:
Implement the forward algorithm that calculates the sequence probability. The result should be around 0.03%.
Background on Forward Algorithm:
The Forward algorithm is a procedure used in Hidden Markov Models (HMMs) to calculate the probability of asequence of observed events. It iteratively combines the probabilities of transitioning between hidden states with the probabilities of emitting observed symbols from those states, at each step of the sequence. By summing these probabilities across all possible paths through the hidden states, the algorithm efficiently computes the likelihood of the observed sequence.
Part #2: Replication of a paper that uses HMM
In this part, you are to choose a conference or journal paper that uses HMMs for some sort of application. Design an HMM, including the observed/hidden states and a set of transition probabilities for this application (you may choose to loosely follow or exactly follow the model from the paper of choice). Implement a ≥10-state HMM and implement the forward-backward algorithm on it to determine the most likely hidden state for any intermediate time step.
Deliverables:
• A summary of the paper you chose and how HMMs can be used for the application of choice
• A write-up of the HMM parameters: hidden states; observations; transition, emission, and initial state probabilities
• An implementation of the forward-backward algorithm in Python. Please organize your code as functions or classes and print the result in a clear manner
• Show that your result is either similar or different from the paper of choice
Problem 6: Implementing a Simple Kalman Filter (10 points)
In this problem you will implement a simple Kalman Filter (with lots of guidance). To start, review Section 15.4 in Russell & Norvig and read the following guide: http://bilgin.esme.org/BitsAndBytes/KalmanFilterforDummies .
Questions to answer before implementing (submit your answers in a document):
● What is the connection between Kalman Filters and HMMs? What are the
similarities and what are the most important differences? Section 15.4 in Russell & Norvig will help with this question.
● What is the goal of Kalman Filtering?
In the implementation, we assume we have some signal x, that has the following
discrete-time model with Gaussian process noise wk (the mean and variance of this noise is left unspecified):
xk+1 = Axk + wk
Process noise results from natural stochasticity in the system we are measuring. The
above linear system can represent any linear process– in fact, this is how robot
dynamics and signals are represented. We also have measurements of this signal, zk, which is related to xk through another linear system. Our method of measuring the
signal may also have natural stochasticity, which we represent as vk (also Gaussian noise with unspecified parameters). The measurement model is defined as follows:
zk+1 = Hzk + vk
You will now implement the steps detailed in the guide linked above, with the help of the starter code provided in the file kalman_filter_prob.py. Follow the flow chart in Step 3 in the guide. The model parameters are given in .mat files and are loaded for you. You will need to use numpy tools to perform the necessary matrix multiplications.
Questions to answer after implementing (submit your answers in a document):
● Describe the significance/differences between the Time Update and Measurement Update steps in Step 3 of the guide.
● What is the significance of the measurement z having a different dimension to the signal values x?
● Plot the norm of the error covariance matrix P with respect to the number of
iterations elapsed. What can you say about the shape of the curve? What does it show us about our estimate of P and the Kalman Filter gain matrix K? In two
sentences describe the meanings of the P and K matrices.
● Provide a similar analysis for the plot of the norm of x - x_hat.
Problem 7:
(10 points)
A company wants to predict the sales of its products over the next year based on historical sales data. The company knows that sales are influenced by various factors, such as advertising spending, price, and seasonal trends. Using probabilistic reasoning overtime, how can the company build a model that takes these factors into account and predicts future sales? Some possible models to consider would be Dynamic Bayesian Network or HMM.
a) Which model can be used in this case? (discuss different possibilities and choose the best option giving a justification of why it is better)
b) Why is it a good fit for the scenario?
c) Implement the chosen model in python (state clearly in your code the
states of the model)[Choose the correct relationships, probabilities can be assumed]
You could use libraries like pomegranate if you wish to for this task.
Problem 8: First-Order Markov Chain Model
(10 points)
You now wish to analyze whether a customer will make a purchase or not. You can use any dataset of your choice that contains information about customer purchase histories and online stores. Using a first-order Markov Chain Model, design a probabilistic model to predict the probability of a customer making a purchase at a given time, based on their past purchase history and other relevant variables. Your implementation must contain:
● The forward algorithm to compute alpha
● The backward algorithm to compute beta
● Function for calculating the posterior probabilities
Useful Theory from Russell and Norvig:
In a first-order Markov Chain Model, the probability of transitioning to a new state depends only on the current state, and not on any past states. We can use this model to predict the probability of a customer making a purchase at a given time, based on their past purchase history and other relevant variables. Here are the formulas for alpha, beta, and posterior probabilities:
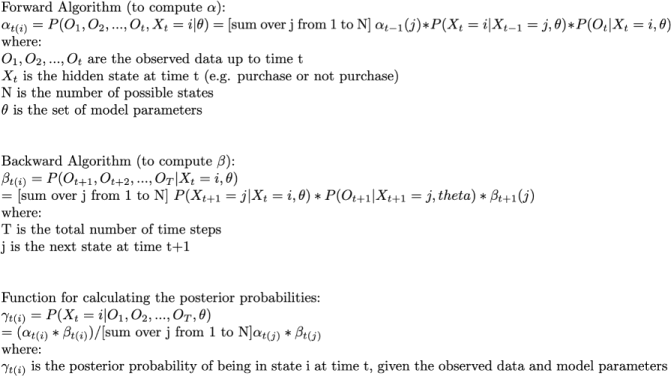
2024-04-08