DTS205TC High Performance Computing
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
|
Module code and Title |
DTS205TC High Performance Computing |
|
|
School Title |
School of AI and Advanced Computing |
|
|
Assignment Title |
Assessment 2 – Lab Report |
|
|
Submission Deadline |
April 22nd, 2024 @ 23:59 |
|
|
Final Word Count |
NA |
|
|
If you agree to let the university use your work anonymously for teaching and learning purposes, please type “yes” here. |
|
|
DTS205TC High Performance Computing
Individual Lab Report
Due: April 22nd, 2024 @ 23:59
Weight: 50%
Maximum Marks: 100 marks
Learning Outcome
This assessment tests your ability to:
A. Demonstrate understanding of the concepts used in modern processors for increasing the performance.
B. Demonstrate optimization techniques for serial code.
C. Understand and apply parallel computing paradigms.
D. Write optimized programs designed for high-performance computing systems.
Overview
The purpose of this assignment is to evaluate the student’s learning outcome base on their weekly lab exercises. All tasks should be done individually.
Avoid Plagiarism
. Do not submit work from other teams/individuals.
. Do not share code/work to students other than your own team members.
. Do not read code/work from other teams/individuals, discussions between teams should remain high level.
. Do not use code from the Internet, Generative AI, or published textbooks.
1. Lab Reports
Lab 1 (15 marks)
In a hierarchical storage system, the cache hit rate has a significant impact on program performance. Different cache strategies will result in different cache hit ratios. Now, we have recorded 2 datasets, containing CPU access requests to memory for a period of time. They both have 10,000 items from addresses 0 to 63. We will simulate the process of the CPU reading and caching data from the memory through a program. We care about how many cache hits occur under a particular policy.
Please run the program in the attachment to compare the hit rates of different strategies. Please answer:
1) Why are the hit rates of the two strategies different on the two data sets? Please perform a visual analysis of the data and explain why in text.
2) Please design and implement a strategy so that when the cache size is no greater than 5, it can achieve better results than the existing two strategies on the trace2 data set.
Lab 2 (15 marks)
By measuring the bandwidth and delay between each two directly connected nodes, we
obtained three computer network’s performance, which are saved in the attachment. Examples of bandwidth data are:
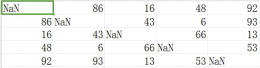
Among them, the data in the i-th row and j-th column represent the bandwidth from node i to node j. Examples of latency data are:
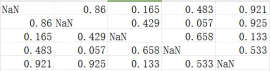
Among them, the data in the i-th row and j-th column represent the delay from node i to node j. Answers are now requested:
1) What type of topology are these networks? Please plot the network structure and judge its type.
2) For each network, program to calculate the shortest delay and maximum throughput from node 1 to node 5, and which nodes are passed through to achieve them? (Any programming language and algorithm library can be used)
Lab 3 (30 marks)
In statistics, bootstrapping is a resampling method that involves repeatedly sampling with replacement from the original data set to estimate the distribution of a population parameter. This approach allows for the estimation of parameter characteristics without assuming the distribution of the population parameter. It is particularly useful when dealing with small sample sizes or unclear population distributions.
Below is a parallel version of the bootstrapping program implemented using mpi4py. Its purpose is to calculate the "variance of the sample mean". Formally speaking, we need to first generate a set of datasets by resampling with replacement 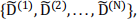 then take their mean
then take their mean 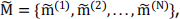 and then calculate their variance
and then calculate their variance 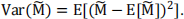
The tasks of this experiment:
1) Estimate the communication time used by this procedure. Assume that the dataset is an array containing D pieces of float type data and needs to be resampled N times. The
transmission delay is L=0 s, and the transmission bandwidth is B bytes/s. The program contains a total of P processes. N is always divisible by P.
2) Modify the part enclosed by the red box to minimize the amount of communication while ensuring the correctness of the results. Explain the mathematical basis for your
modification, give the code, and give the new communication time calculation formula.
NOTE: Only estimation is required, no actual measurement is required; only point-to-point,
blocking communication, i.e. send/recv, can be used.
Lab 4 (30 marks)
Continue with the previous experiment. When the data set is too large, due to the limited
memory capacity of each process (assuming that it cannot store more than 2*D/P float values), they can each load/generate a part of the original data, and they cannot directly exchange them between processes. Only small amounts of intermediate results can be passed. Based on the previous experiment, we further assume that each process can complete S samples per second. It is assumed here that operations other than sampling take no time; D is always divisible by P.
Please redesign the program to shorten the overall running time as much as possible while
ensuring the correctness of the results. Please explain the mathematical basis for your
modification, and provide the code and running time calculation formula (including calculation and communication; if randomness exists, take the expectation).
NOTE: Only estimation is required, no actual measurement is required; only point-to-point, blocking communication, i.e. send/recv, can be used.
Lab 5 (10 marks)
In functional programming, the focus is on using functions to manipulate and transform data, rather than relying on modifying states or performing mutable operations. In python, similar
style operations are also provided for lists, such as map, reduce, sorted and itertools. Since they do not modify individual elements but always create new lists, they can be safely parallelized
and are ideal for big data analysis.
Now we have the data of a directed graph whose record format is a dict. The key is the node, and the value is the destination node pointed by the node through the edge. For example
{0:[1,4,6,7,12,13,16,18,19],
represents the existence of directed edges from node 0 to 1, 4, 6... Please complete the following program and print the 10 nodes that are pointed to the most.
NOTE: ‘for’ and ‘while’ loops cannot be used here, only map, reduce, sorted and itertools can be used to implement equivalent programs.
2. Submission
You must submit the following files to LMO:
1) A report named as Your_Student_ID.pdf.
2) A directory containing all your source code, named as Your_Student_ID_code.
NOTE: The report shall be in A4 size, size 11 font, and shall not exceed 8 pages in length. You can include only key code snippets in your reports. The complete source code can be placed in the attachment.
2024-04-03