DTS304TC Machine Learning Assessment Task 1
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
DTS304TC Machine Learning
Coursework - Assessment Task 1
Submission deadline: TBD
Percentage in final mark: 50%
Learning outcomes assessed:
A. Demonstrate a solid understanding of the theoretical issues related to problems that machine learning algorithms try to address.
B. Demonstrate understanding of properties of existing ML algorithms and new ones.
C. Apply ML algorithms for specific problems.
Individual/Group: Individual
Length: The assessment has a total of 4 questions which gives 100 marks. The submitted file must be in pdf format.
Late policy: 5% of the total marks available for the assessment shall be deducted from the assessment mark for each working day after the submission date, up to a maximum of five working days
Risks:
. Please read the coursework instructions and requirements carefully. Not following these instructions and requirements may result in loss of marks.
. The formal procedure for submitting coursework at XJTLU is strictly followed. Submission link on Learning Mall will be provided in due course. The submission timestamp on Learning Mall will be used to check late submission.
Question 1: Coding Exercise - Heart Disease Classification with Machine Learning (50 Marks)
In this coding assessment, you are presented with the challenge of analyzing a dataset that contains patient demographics and health indicators to predict heart disease classifications. This entails solving a multi-class classification problem with five distinct categories, incorporating both categorical and numerical attributes.
Your initial task is to demonstrate proficiency in encoding categorical features and imputing missing values to prepare the dataset for training a basic classifier. Beyond these foundational techniques, you are invited to showcase your advanced skills. This may include hyperparameter tuning using sophisticated algorithms like the Asynchronous Successive Halving Algorithm (ASHA). You are also encouraged to implement strategies for outlier detection and handling, model ensembling, and addressing class imbalance to enhance your model's performance.
Moreover, an external test set without ground truth labels has been provided. Your classifier's performance will be evaluated based on this set, underscoring the importance of building a model with strong generalization capabilities.
The competencies you develop during this practical project are not only essential for successfully completing this assessment but are also highly valuable for your future pursuits in the field of data science. Throughout this project, you are encouraged to utilize code that was covered during our Lab sessions, as well as other online resources for assistance. Please ensure that you provide proper citations and links to any external resources you employ in your work. However, the use of Generative AI for content generation (such as ChatGPT) is not permitted on all assessed coursework in this module.
Project Steps:
a) Feature Preprocessing (8 Marks)
![]() You are required to demonstrate four key preprocessing steps: loading the dataset, encoding categorical features, handling missing values, and dividing the dataset into training, validation, and test sets.
You are required to demonstrate four key preprocessing steps: loading the dataset, encoding categorical features, handling missing values, and dividing the dataset into training, validation, and test sets.
![]() It is crucial to consistently apply the same feature preprocessing steps—including encoding categorical features, handling missing values, and any other additional preprocessing or custom modifications you implement—across the training, validation, internal testing, and the externally provided testing datasets. For efficient processing, you may want to consider utilizing the sklearn.pipeline and sklearn.preprocessing library functions.
It is crucial to consistently apply the same feature preprocessing steps—including encoding categorical features, handling missing values, and any other additional preprocessing or custom modifications you implement—across the training, validation, internal testing, and the externally provided testing datasets. For efficient processing, you may want to consider utilizing the sklearn.pipeline and sklearn.preprocessing library functions.
b) Training Classifiers (10 Marks)
![]() Train a logistic regression classifier with parameter tuned using grid search, and a random forest classifier with parameters tuned using Async Successive Halving Algorithm (ASHA) with ray[tune] libraries. You should optimize the model's AUC score during the hyperparameter tuning process.
Train a logistic regression classifier with parameter tuned using grid search, and a random forest classifier with parameters tuned using Async Successive Halving Algorithm (ASHA) with ray[tune] libraries. You should optimize the model's AUC score during the hyperparameter tuning process.
![]() You should aim to optimize a composite score, which is the average of the classification accuracy and the macro-averaged F1 score. This objective encourages a balance between achieving high accuracy overall and ensuring that the classifier performs well across all classes in a balanced manner, which is especially important in multi-class classification scenarios where class imbalance might be a concern.
You should aim to optimize a composite score, which is the average of the classification accuracy and the macro-averaged F1 score. This objective encourages a balance between achieving high accuracy overall and ensuring that the classifier performs well across all classes in a balanced manner, which is especially important in multi-class classification scenarios where class imbalance might be a concern.
To clarify, your optimization goal is to maximize a composite accuracy metric defined as follows: accuracy = 0.5 * (f1_score(gt, pred, average='macro') + accuracy_score(gt, pred))
In this formula, f1_score and accuracy_score refer to functions provided by the scikit-learn library, with f1_score being calculated with the 'macro'average to treat all classes equally.
![]() Ensure that you perform model adjustments, including hyperparameter tuning, on the validation set rather than the testing set to promote the best generalization of your model.
Ensure that you perform model adjustments, including hyperparameter tuning, on the validation set rather than the testing set to promote the best generalization of your model.
![]() We have included an illustrative example of how to implement the ASHA using the ray[tune] library. Please refer to the notebook DTS304TC_ASHA_with_Ray_Tune_Example.ipynb located in our project data folder for details.
We have included an illustrative example of how to implement the ASHA using the ray[tune] library. Please refer to the notebook DTS304TC_ASHA_with_Ray_Tune_Example.ipynb located in our project data folder for details.
c) Additional Tweaking and External Test Set Benchmark (19 Marks)
![]() You are encouraged to explore a variety of advanced techniques to improve your model's predictive power.
You are encouraged to explore a variety of advanced techniques to improve your model's predictive power.
1. Utilizing different classifiers, for example, XGBoost.
2. Implementing methods for outlier detection and treatment.
3. Creating model ensembles with varied validation splits.
4. Addressing issues of class imbalance.
5. Applying feature engineering strategies, such as creating composite attributes.
6. Implementing alternative validation splitting strategies, like cross-validation or stratified sampling, to enhance model tuning.
7. Additional innovative and valid methods not previously discussed.
You will be awarded 3 marks for successfully applying any one of these methods. Should you incorporate two or more of the aforementioned techniques, a total of 6 marks will be awarded.
Please include code comments that explain how you have implemented these additional techniques. Your code and accompanying commentary should explicitly state the rationale behind the selection of these supplementary strategies, as well as the underlying principles guiding your implementation. Moreover, it should detail any changes in performance, including improvements, if any, resulting from the application of these strategies. An additional 4 marks will be awarded for a clear and comprehensive explanation. To facilitate a streamlined review and grading process, please ensure that your comments and relevant code are placed within a separate code block in your Jupyter notebook, in a manner that is readily accessible for our evaluation.
Additionally, utilize the entire dataset and the previously determined optimal hyperparameters and classification pipeline to retrain your top-performing classifier. Then, apply this model to the features in 'dts304tc_a1_heart_disease_dataset_external_test.csv', which lacks true labels, to produce a set of predictive probability scores. Save these probabilistic scores in a table with two columns: the first column for patient IDs and the second for the output classification labels. Export this table to a file named external_test_results_[your_student_id].csv. Submit this file for evaluation. In the external evaluation conducted by us, your scores will be benchmarked against the performance of models developed by your classmates. You will receive four marks for successfully completing the prescribed classifier retraining and submission process. Additionally, your classifier's benchmark ranking—based on its performance relative to models developed by your peers—will be assigned five marks, contingent upon your standing in the ranking.
d) Result Analysis (8 Marks)
• For your best-performing model, compute critical performance metrics such as precision, recall, specificity, and the F1 score for each class. Additionally, generate the confusion matrix based on your internal test set. Ensure that the code for calculating these performance metrics, as well as the resulting statistics, are clearly displayed within your Jupyter notebook. For ease of review,
position these elements towards the end of your notebook to provide direct access to your outcomes.
• Conduct a feature importance analysis by utilizing the feature importance scoring capabilities
provided by your chosen classifier. What are the top three most important features for classifying this medicial condition? If your best performing model does not offer feature importance scoring, you may utilize an alternative model for this analysis. Present the results of the feature importance analysis within your Jupyter notebook using print statements or code comments.
Place these relevant code and findings towards the end of the notebook to facilitate easy review of your results.
e) Project Submission Instructions (5 Marks - Important, Please Read!)
• Submit your Jupyter notebook in both .ipynb and .PDF formats. Ensure that in the PDF version, all model execution results, as well as your code annotations and analyses, are clearly visible. It is critical to maintain a well-organized structure in your Jupyter notebook, complemented by clear commentary using clean code practices. Your submission's readability and navigability are crucial; we cannot assign a score if we cannot understand or locate your code and results. You will receive 5 points for clarity in code structure and quality of code comments.
To maintain the readability of your code when converting your Jupyter notebook to a PDF, ensure that no single line of code extends beyond the printable page margin, thus preventing line truncation. If necessary, utilize line continuation characters or implicit line continuation within parentheses, brackets, or braces in Python to break up longer lines of code. After converting to PDF, thoroughly review the document to confirm that all code is displayed completely and that no line truncation has occurred.
If you have written supplementary code that is not contained within the Jupyter notebook, you must submit that as well to guarantee that your Jupyter notebook functions correctly. Nevertheless, our primary basis for grading will be the PDF version of your Jupyter notebook. Please ensure that all necessary code is included so that the notebook can be executed seamlessly, and your results are reproducible.
![]() Submit the results of your external test as a file named external_test_[your_student_id].csv. This CSV file must be correctly formatted: the first column must contain patient IDs, and the second column must list your predicted classification labels. Any deviation from this format may result in the file being unprocessable by our grading software, and therefore unable to be scored.
Submit the results of your external test as a file named external_test_[your_student_id].csv. This CSV file must be correctly formatted: the first column must contain patient IDs, and the second column must list your predicted classification labels. Any deviation from this format may result in the file being unprocessable by our grading software, and therefore unable to be scored.
Project Material Access Instructions
To obtain the complete set of materials for our project, including the dataset, code, and Jupyter notebook files, please use the links provided below:
![]() (OneDrive Link): https://1drv.ms/u/s!AoRfWDkanfAYnvcrXTKMGhNzRztf0g?e=JDwmbR
(OneDrive Link): https://1drv.ms/u/s!AoRfWDkanfAYnvcrXTKMGhNzRztf0g?e=JDwmbR
![]() (Baidu Drive Link): https://pan.baidu.com/s/1AXSRYO6ujTu1iNspdkIuUA?pwd=h4js Download password: h4js
(Baidu Drive Link): https://pan.baidu.com/s/1AXSRYO6ujTu1iNspdkIuUA?pwd=h4js Download password: h4js
When prompted, use the following password to unlock the zip file: DTS304TC (please note that it is case- sensitive and should be entered in all capital letters).
Additionally, for ease of reference, the project's Jupyter notebooks have been appended to the end of this document.
Please note that the primary library dependencies for this project include pandas, scikit-learn, xgboost, and the ray library with the tune module enabled (ray[tune]).
Question 2: Ensemble Learning (18 marks):
Students are required not to use AI models, such as ChatGPT, for assistance with this question. You should give clear calculation steps and explain the relevant concepts using your own words.
(a) Majority Voting with Independent Classifiers (8 Marks)
1. Given individual classifiers C1, C2, and C3 with statistically independent error rates of 40%, 35%, and 35% respectively, calculate the accuracy of the majority voting ensemble composed of classifiers C1, C2, and C3. Provide the steps you use to determine the ensemble's accuracy, assuming the classifiers' decisions are statistically independent. (5 Marks)
(Hints: Calculate the ensemble 's accuracy by summing the probability that all classifiers are correct with the probabilities of exactly two classifiers being correct while the third is incorrect)
2. Point out the similarities and differences between the majority voting ensemble method and Random Forest, emphasizing the strategies employed by Random Forest to attain higher accuracy. (3 Marks)
(b) AdaBoost Algorithm (10 Marks)
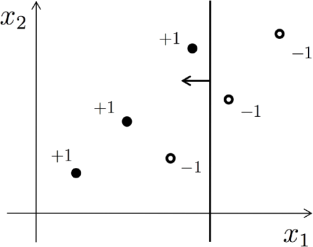
Consider the process of creating an ensemble of decision stumps, referred to as Gm , through the standard AdaBoost method.
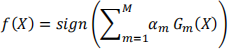
The diagram above shows several two-dimensional labeled points along with the initial decision stump we've chosen. This stump gives out binary values and makes its decisions based on a single variable (the cut-off). In the diagram, there's atiny arrow perpendicular to the classifier's boundary that shows where the classifier predicts a +1. Initially, every point has the same weight.
1. Identify all the points in the above diagram that will have their weights increased after adding the initial decision stump (adjustments to AdaBoost sample weights after the initial stump is used) (2 marks)
2. On the same diagram, draw another decision stump that could be considered in the next round of
boosting. Include the boundary where it makes its decision and indicate which side will result in a +1 prediction. (2 marks)
3. Will the second basic classifier likely get a larger importance score in the group compared to the first one? To put it another way, will α2 > α1 ? Just a short explanation is needed (Calculations are not required). (3 marks)
4. Suppose you have trained two models on the same set of data: one with AdaBoost and another with a Random Forest approach. The AdaBoost model does better on the training data than the Random
Forest model. However, when tested on new, unseen data, the Random Forest model performs better. What could explain this difference in performance? What can be done to make the AdaBoost model perform better? (3 marks)
Question 3: K-Means and GMM Clustering (7 marks)
Students are required not to use AI models, such as ChatGPT, for assistance with this question. You should give clear analysis steps and explain the relevant concepts using your own words.
1. Reflect on the provided data for training and analyze the outcomes of K-Means and GMM techniques. Can we anticipate identical centroids from these clustering methods? Please state your reasoning. (3 marks)

2. Determine which of the given cluster assignments could be a result of applying K-means clustering, and which could originate from GMM clustering, providing an explanation for your reasoning. (4 marks)

Question 4 - Reinforcement Learning (25 marks)
Students are required not to use AI models, such as ChatGPT, for assistance with this question. You should give clear analysis steps and explain the relevant concepts using your own words.
1. Describe the five key components of reinforcement learning using the graph below, explain each of the components and their relationships. (10 marks.)
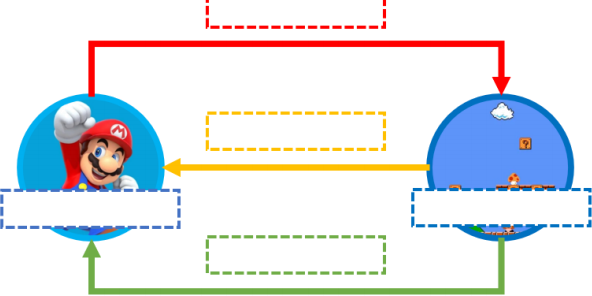
2. The questions below refer to the above code example:
a) What is the significance of the exploration-exploitation strategy in reinforcement learning, and how is it implemented in the code? (5 marks)
b) How would you change this code to use deep learning? You don’t need to write the code, only
describe the major changes you would make and explain the advantage of deep learning approaches over the Q-table. (5 marks)
c) Describe the current reward function for Cartpole. Design a reward function of your own and explain your reward function. (5 marks)
In [ ]: # to student: this is an code snapshot showing how to use ray tune framework to # you are responsible for completing the code, debugging and making sure it work
import sklearn.datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn import metrics
import os
from ray.tune.schedulers import ASHAScheduler
from sklearn.model_selection import train_test_split
from ray import tune
from ray import train
def train_rf(config: dict, data=None):
# Initialize the RandomForestClassifier with the configuration
classifier = RandomForestClassifier(
n_estimators=config["n_estimators"],
max_depth=config["max_depth"],
min_samples_split=config["min_samples_split"],
min_samples_leaf=config["min_samples_leaf"],
class_weight="balanced",
random_state=42
)
# Fit the RandomForestClassifier on the training data
X_train = data[0]
y_train = data[1]
X_validation = data[2]
y_validation = data[3]
# To Be filled: Train your Random Forest Classifier here
# To Be filled: Evaluate the classifier on the validation set here and get e
# Send the accuracy to Ray Tune
train.report({'accuracy': accuracy})
# note that X_train, y_train, X_validation, y_validation are your training and v
tunable_function = tune.with_parameters(train_rf, data=[X_train, y_train, X_vali
def tune_random_forest(smoke_test=False):
# Define the search space for hyperparameters
search_space = {
"n_estimators": # setup your search space here
"max_depth": # setup your search space here
"min_samples_split" : # setup your search space here
"min_samples_leaf" : # setup your search space here
}
# Define the scheduler for early stopping
scheduler = ASHAScheduler(
max_t= # setup your ASHA parameter here,
grace_period=# setup your ASHA parameter here,
reduction_factor=# setup your ASHA parameter here
)
# Set up the tuner
tuner = tune.Tuner(
tunable_function,
a1_ASHAScheduler_ray_tune_for_student
tune_config=tune.TuneConfig(
metric="accuracy",
mode="max",
scheduler=scheduler,
num_samples=1 if smoke_test else 200,
),
param_space=search_space,
)
# Execute the tuning process
results = tuner.fit()
return results
# Run the tuning function
best_results = tune_random_forest(smoke_test=False)
best_trial = best_results.get_best_result(metric="accuracy", mode="max")
# Get the best trial's hyperparameters
best_params = best_trial.config
# Print the best hyperparameters
print("Best hyperparameters found were: ", best_params)
# Initialize a new RandomForestClassifier with the best hyperparameters
best_rf = RandomForestClassifier(**best_params, random_state=42)
# The remaining part of your code continues ....
2024-03-03