CS 4710 - Artificial Intelligence Midterm
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CS 4710 - Artificial Intelligence
Midterm
Due: 3/1/2024 11:59AM
Instructions
1. This is an open-book exam. You can check slides and your notes to complete the exam, but use of generative AI is not permitted for this midterm.
2. Please choose your favorite way to finish the midterm questions. If you decide to use handwriting, make sure it is clear enough for reading and grading.
3. Please make sure your submission is in PDF format.
4. No late submission.
A. Multi-choice questions (50%, 5% for each question)
1. (State Space) Given the following state space graph, what is the depth of the search
tree? Assume the search strategy is uninformed.
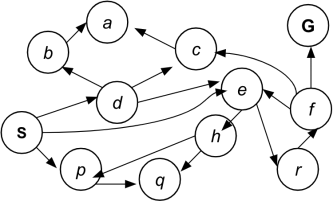
a. 2n, where n is the number of nodes
b. ne, where n is the number of nodes and e is the number of edges between nodes
c. e, where e is the number of edges between nodes
d. Undetermined without knowing which search strategy you are using
e. Infinite
2. (Heuristics) For the following search problem, mark all admissible heuristics.
We have N PacMans and M food pallets in the maze. These PacMans starts at the same position and will move simultaneously at each time step to an adjacent spot. The goal is to all food pallets.
a. Minimum Manhattan distance between any pair of PacMan and food pallet
b. Maximum Manhattan distance between any pair of PacMan and food pallet
c. Average Manhattan distance between any pair of PacMan and food pallet
d. Number of food pallets left
e. Number of food pallets left divided by N
3. (Perceptron) Select the statements that are true about perceptron.
a. The perceptron algorithm will converge for any data distribution.
b. After immediately updating a missed example, perceptron will classify that example correctly.
c. If we run the perceptron with no bias term on d dimensional data, the produced decision boundary will be a hyperplane that passes the origin of the ℜd space.
d. We have three linearly separable classes: A, B, and C. We run perceptron with
initial weights: WA(0) , WB(0) , Wc(0) and run it until convergence. Let T to be the number of
updates of the weights before convergence and S = WA(0) + WB(0) + Wc(0) and S > 0 .
After the updates, WA(T) + WB(T) + Wc(T) = 0.
e. When running the perceptron algorithm, if we make one pass through the data and have no classification mistakes, the algorithm has converged.
4. (Perceptron) We would like to use perceptron algorithm to train a classifier to decide if we should turn on AC. We consider 2 features per data point and labels +1 or -1 to
indicate AC is on or off. Here is the labeld training examples:
|
Features (x1, x2) |
Label y* |
|
(-2, 3) |
1 |
|
(4, -2) |
-1 |
|
(2, 3) |
-1 |
|
(4, 2) |
1 |
If we initialized the perceptron weights to be W1 = 3 and W2 = -3, and no bias. Which of the following statements are true.
a. After processing the first data point with the initial weight, the data point will be correctly classified.
b. After the first weight update, we will update W1 to a smaller value. c. After the first weight update, we will update W2 to a smaller value.
d. The perceptron algorithm will eventually converge on this dataset if we iterate the training data for enough times.
e. This dataset is linearly separable.
5. (Search Formulation) In this question, you will formulate the search problem for flying from one city to another city. The scenario is as follows. After working hard for the whole semester, you decide to go to Hawaii for a vacation. You just want to go from Charlottesville to Hawaii as fast as possible, i.e., not consider the ticket price and number of flights you need to take. Each flight has a departure time and location as well as an arrival time and location, and it goes from city to city. Between flights, you will wait in a city. Select the formulation that gives us a minimal state space.
a. State: current city and current time
b. State: current city, current time, and thee amount of travel time so far
c. Successor: update the city and current time
d. Successor: update the city, current time, and the time spent traveling
e. Goal test: check if the current city is in Hawaii and the amount of travel time is minimal
6. (Logic) We want to come up a hypothesis that can entail the following sentences:
● S1 : A ∧ B ⇒ C
● S2 : ¬A ∨ B ⇒ C
Which of the following statements are true?
a. Hypothesis H: C ⇔ A ∨ B entails S1
b. Hypothesis H: C ⇔ A ∨ B entails S2
c. For a hypothesis H' that can entail both S1 and S2 , we can find some assignments of A, B, and C where H′ ∧ ¬(S1 ∧ S2) will be evaluated to true
d. For a hypothesis H' that can entail both S1 and S2 , we can find some assignments of A, B, and C where H′ ∧ ¬(S1 ∧ S2) will be evaluated to false
e. None of the above
7. (Localization) Consider the robot localization problem we mentioned in the lecture, which of the following statements are true?
a. Localization methods aims to estimate the robot’s belief of its location.
b. If we just let time elapse, the transition probability will be used to update the belief.
c. It is necessary to correct the robot’s belief using likelihood of the collected evidence/observation.
d. The same method can be used to estimate the location of other agents.
e. Localization is a problem to find the most likely explanations.
8. (Agents) Select the statements that are true about rational agents.
a. Utility agents are always rational.
b. If an action is rational, it implies that the agent performed inference.
c. A simple reflex agent is considered rational if its action is correct based on the percept history.
d. Under the condition of uncertainty, choosing an action that maximizes the agent’s expected utility is a rational action.
e. Randomized behavior is never rational.
9. (Search Algorithm Comparison) Consider a search problem where for every action, the cost is a positive number, which of the following statement is true?
a. Greedy search cannot return an optimal solution
b. A* search is guaranteed to expand no more nodes than uniform-cost search (UCS).
c. We can use an A* implementation to generate results for UCS.
d. Iterative deepening uses less memory than breath-first search.
e. Depth first search cannot return an optimal solution.
10. (Overfitting) Select the statements that are true about overfitting
a. Overfitting cannot occur in a Naïve Bayes classifier due to the independence assumption.
b. Overfitting occurs when the test error is higher than the train error.
c. Using a subset of the training data as part of the validation data can help counteract overfitting.
d. Overfitting cannot occur in binary classification problems.
e. None of the above
B. Calculations (50%)
1. (Naive Bayes Classifier) Consider a simple sentiment classification problem with seven training examples
|
Index |
Example |
Label |
|
1 |
I like the coffee |
+1 |
|
2 |
Everyone should try their food |
+1 |
|
3 |
I love how they offer different options for breakfast |
+1 |
|
4 |
I am surprised at all the negative reviews, their coffee is the best in town |
+1 |
|
5 |
Come here if you want to waste your money |
-1 |
|
6 |
the service of this restaurant was awful, I will never come back |
-1 |
|
7 |
The food here is just horrible |
-1 |
and three validation examples:
|
Index |
Example |
Label |
|
1 |
Try a bagel for breakfast, really don’t like it |
-1 |
|
2 |
Never had a coffee like this before |
-1 |
|
3 |
Come here and try their tiramisu, please! |
+1 |
Questions:
a. (5%) Consider the bag-of-words Naive Bayes model with only the following features
F1 = coffee
F2 = food
F3 = money
F4 = breakfast
F5 = horrible
F6 = best
Let y denote the label and Fi denote each feature, please estimate the prior
probability of P(y) and the conditional probability P(Fi |y) for each value of y and Fi.
b. (5%) Please calculate the prediction probability P(y|F1... F6) and their predicted label on each validation example, your calculation should start from prior
probability and the conditional probabilities estimated in Question a.
c. (5%) Please list the indices of training examples that the model can make correct predictions.
d. (5%) You may notice the prediction performances on the training examples and validation example are different. Please explain the issue of this classifier and briefly discuss how you can fix this issue.
2. (Markov Chains) Consider the three websites that engineers often used for developing their deep learning models:huggingface.co (H),pytorch.org (P), andstackexchange.com (S). Often, one website cannot contain all the information that developers need, and they often need to switch back and forth between these three websites for finding information. In this hypothetical example, let’s assume users can switch back and forth with many times. Specifically,
● if a user is athuggingface.co, the chance of switching topytorch.org is 0.5 and to stackexchange.com is 0.1;
● if a user is atpytorch.org, the chance of staying at it is 0.4, and the chance of switching tohuggingface.co is 0.3;
● if a user is atstackexchange.com , the chance of staying at this website is 0.2, and the chance of switching tohuggingface.co andpytorch.org are equal.
Questions:
a. (5%) Let Xt−1 and Xt represent the a user visiting a website at time t- 1 and t. Let H, P, S represent the three websites. Please write down the transition probability table, with each row is one possible value of Xt−1 and each column is one possible value of Xt
b. (5%) Assume an user has the equal chance to visit one of the websites at time t= 1, please calculate the joint probability after two steps P(X1, X2)
c. (5%) Assume an user start fromhuggingface.co, what is the probability of this user visiting each website at t=5?
d. (5%) On the other hand, assume an user is atpytorch.org at t=6, and we know the user starts fromhuggingface.co, which is the most likely browsing trajectory? As we have already know X1 = H and X6 = P , please list the most likely values of X2 ... X5 (in order) that leads from X1 = H to X6 = P.
3. (Probabilistic Inference) Consider the following three random variables
● X: wet grass
● Y: rained
● Z: sprinkler was on
The dependence among these random variables is represented in the simple Bayesian network Z → X ← Y. The joint probability of these three random variables are defined as
|
X |
Y |
Z |
P(X, Y, Z) |
|
0 |
0 |
0 |
0.405 |
|
1 |
0 |
0 |
0.045 |
|
0 |
1 |
0 |
0.0025 |
|
1 |
1 |
0 |
0.0475 |
|
0 |
0 |
1 |
0.09 |
|
1 |
0 |
1 |
0.36 |
|
0 |
1 |
1 |
0.0005 |
|
1 |
1 |
1 |
0.0495 |
Questions:
a. (2%) Please calculate the prior distribution P(Z)
b. (3%) Given the observation that the grass is wet, please calculate the conditional probability P(Z | X = 1)
c. (3%) Now, assume we know it just rained, please calculate the conditional probability of Z with all the information we have, P(Z | X = 1, Y = 1)
d. (2%) Please provide an intuitive explanation of the probability changes from P(Z = 1) to P(Z = 1 | X = 1), to P(Z = 1 | X = 1, Y = 1)
2024-03-02