CISC 3410: Artificial Intelligence
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CISC 3410: Artificial Intelligence
P1 (30 Points)
Due: Feb 26th, 11:59 pm
Grading, submission, and late policy:
● You are expected to complete this project on your own (not with a partner).
● Please refer to the syllabus for the late submission policy.
● You must submit your assignment via Blackboard.
● Your code should work without errors; code that fails will not be graded.
In this project, you will implement uninformed and informed search strategies to solve sudoku puzzles. For those unfamiliar with the sudoku puzzle, please refer to Wikipedia. You are provided with a starter code in the file game.py. We will use an existing public library to generate puzzles and verify solutions. We will use the py-sudoku library; follow the link for installation instructions. Usage instructions on the readme page should help you get started with the library.
Implementation:
You will complete the function definitions in the provided game.py Python file. Each function definition corresponds to a different graph search strategy. Before starting with implementation, please read the instructions here carefully. The Python library we are working with can generate puzzles of varying difficulties. Let us not worry about that for now; we will look at how to deal with this in the evaluation section. The initial state for your search implementation is the puzzle you are provided with, and the goal state is the completed puzzle.
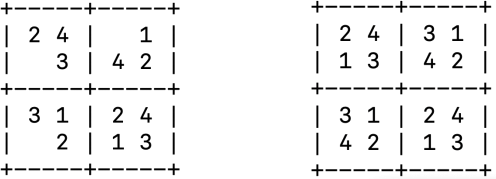
Fig. 1: Initial state on the left and goal state on the right for a 2x2 sudoku puzzle
Fig. 1 shows the initial and goal states for a 2x2 sudoku puzzle, and Fig. 2 shows part of the state space for a different 2x2 puzzle. To expand the initial state, you will pick an empty cell in the grid and fill it with a number between one and four. Filling in numbers in the empty states is the only available action for this problem. While expanding a node, you will add nodes corresponding to all possible states from the current state for every empty cell, even nodes corresponding to invalid states in sudoku. For the puzzle in Fig. 2, three cells are empty, which means you will have twelve nodes in the first level four for each empty cell.

Fig. 2: Partial state space of a 2x2 sudoku puzzle
Based on the above explanation, if e represents the number of empty cells and n the number of possible values in a cell, what is the branching factor for a node during expansion?
Including invalid nodes as part of the frontier does increase the computational time and the number of states we need to keep track of. We will relax this in the future. Using the above strategy for node expansion, implement the following two functions:
a) [6 points] Breadth-first search (bfs): You must maintain a FIFO queue for the frontier; refer to the queue in-built library in Python.
b) [6 points] Depth-first search (dfs): You must maintain a LIFO queue for the frontier; refer to the queue in-built library in Python.
Both implementations should use the graph search version, and goal verification should be done before adding a node to the queue. Use the provided examples in the main section as a reference for accessing the puzzle and making changes to the puzzle board. For the next two implementations, you will reimplement the breadth-first and depth-first searches accounting for invalid states.
c) [4 points] Breadth-first search with pruning (bfs_pruning): Same as bfs, except if an expanded node is invalid, you will not add it to the frontier. You can check the validity of a puzzle board using the function valid_puzzle().
d) [4 points] Depth-first search with pruning (dfs_prning): Same as dfs, except if an
expanded node is invalid, you will not add it to the frontier. You can check the validity of a puzzle board using the function valid_puzzle().
Evaluation:
You will evaluate your implementation on the following criteria:
1) [3 points] Runtime vs puzzle size: For this, you will evaluate different-sized puzzles starting from 2x2 up to 4x4. You will set the puzzle difficulty to 0.2 while generating the puzzles. For each puzzle size, you will make ten runs and document the time it took to find the solution for the puzzle for different search strategies. You can use timeit or any other method to track runtime. If a search strategy does not return a solution within a reasonable time, you can terminate the run and document it as NA. I will leave it up to you to determine a reasonable time. Generate a plot with the X-axis search strategy and the Y-axis's resulting runtime. If the runtime is NA, you can set it to the time you terminated the program.
2) [3 points] Runtime vs. puzzle difficulty: You will repeat the exercise in the previous section. Instead of varying the puzzle size, you will use the same puzzle 2x2 and vary the puzzle difficulty from 0.2 to 0.9 at increments of 0.1. Plot the resulting runtime with Runtime on the Y-axis and puzzle difficulty on the X-axis.
3) Based on the previous two evaluations, answer the following questions:
a) [2 points] Why is there a difference in runtime for different search algorithms? Justify your answer using the number of nodes that different strategies expand.
b) [2 points] How much runtime is saved using the pruned breadth and
depth-first search versions? Does the savings correlate with the previous answer?
Submission instructions:
● You will submit two files: a game.py Python file with your implementation and a document with the evaluation results and answers to the questions.
● If you are using external libraries, include instructions on how to install them.
● If you are programming in a different language, you should include instructions on compiling and running your project.
● Start early. Good Luck!
2024-03-02